探索数据分析
作者:Blink
邮箱:592702703@qq.com
爱好:喜欢数据分析、可视化和机器学习,目前研究深度学习中。
可以结团Kaggle或者比赛喔!
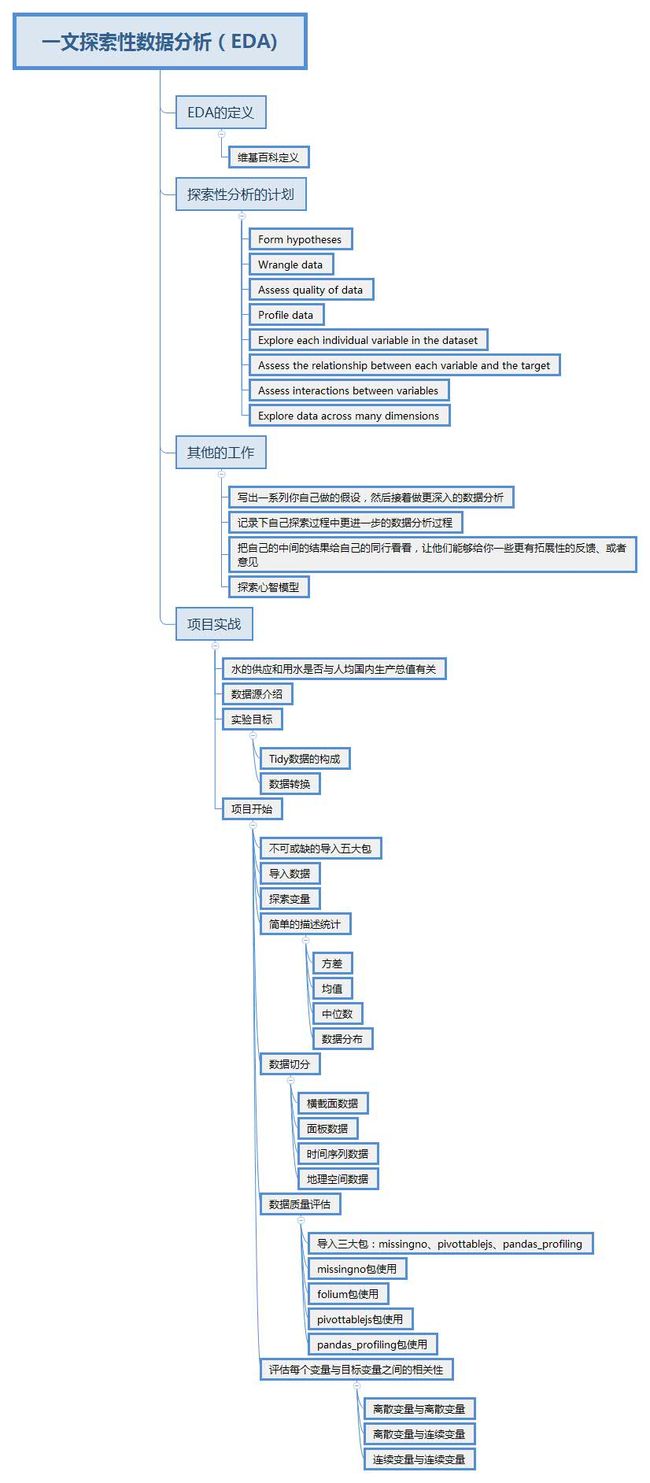
什么叫探索性数据分析?
探索性数据分析(Exploratory Data Analysis,简称EDA),摘抄网上的一个中文解释,是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是党我们对面对大数据时代到来的时候,各种杂乱的“脏数据”,往往不知所措,不知道从哪里开始了解目前拿到手上的数据时候,探索性数据分析就非常有效。探索性数据分析是上世纪六十年代提出,其方法有美国统计学家John Tukey提出的。
附上:Howard Seltman 探索数据分析的英语文档http://www.stat.cmu.edu/~hseltman/309/Book/chapter4.pdf
维基百科的英语解释:
In statistics, exploratory data analysis(EDA) is an approach to analyzing data sets to summarize their maincharacteristics, often with visual methods. A statistical model can be used ornot, but primarily EDA is for seeing what the data can tell us beyond theformal modeling or hypothesis testing task. Exploratory data analysis waspromoted by John Tukey to encourage statisticians to explore the data, andpossibly formulate hypotheses that could lead to new data collection andexperiments. EDA is different from initial data analysis (IDA), which focusesmore narrowly on checking assumptions required for model fitting and hypothesistesting, and handling missing values and making transformations of variables asneeded. EDA encompasses IDA.
百度翻译:
在统计学中,探索性数据分析(EDA)是一种分析数据集以概括其主要特征的方法,通常使用可视化方法。可以使用或使用统计模型,但主要是EDA是为了了解数据在形式化建模或假设测试任务之外能告诉我们什么。探索性数据分析是John Tukey提拔的鼓励统计学家的研究数据,并尽可能提出假设,尽可能生成新的数据收集和实验。EDA不同于初始数据分析(IDA),,它更集中于检查模型拟合和假设检验所需的假设,以及处理缺少的值,并根据需要进行变量转换。EDA包含IDA。
探索性分析的计划:
1、Form hypotheses/develop investigation theme to explore形成假设,确定主题去探索
2、Wrangle data清理数据,网上有一个网址公布斯坦福有一个软件叫datawrangler可以供大家自己免费下载,用于探索数据分析,很快的解决数据清洗的工作,作为一个将来想成为数据科学家的人,处理“脏数据”,是我们必须走的路。这个软件我还没有试,我把链接发在下面,供爱学习的小伙伴好好学习。http://vis.stanford.edu/wrangler/
https://www.trifacta.com/products/wrangler/
https://www.douban.com/note/501799325/
3、Assess quality of data评价数据质量
4、Profile data数据报表
5、Explore each individual variable in the dataset探索分析每个变量
6、Assess the relationship between each variable and the target探索每个自变量与因变量之间的关系
7、Assess interactions between variables探索每个自变量之间的相关性
8、Explore data across many dimensions从不同的维度来分析数据
通过以上的探索性分析,你还可以做以下的工作:
1、写出一系列你自己做的假设,然后接着做更深入的数据分析
2、记录下自己探索过程中更进一步的数据分析过程
3、把自己的中间的结果给自己的同行看看,让他们能够给你一些更有拓展性的反馈、或者意见。不要独自一个人做,国外的思维就是知道了什么就喜欢open to everybody,要走出去,多多交流,打开新的世界。
4、将可视化与结果结合一起。探索性数据分析,就是依赖你好的模型意识,(在《深入浅出数据分析》P34中,把模型的敏感度叫心智模型,最初的心智模型可能错了,一旦自己的结果违背自己的假设,就要立即回去详细的思考)。所以我们在数据探索的尽可能把自己的可视化图和结果放一起,这样便于进一步分析。
实战案例
目标名称:水的供应和用水是否与人均国内生产总值有关?(提出假设)
数据源:http://www.fao.org/nr/water/aquastat/data/query/index.html下图数据源界面(如果您经常做学术研究,例如OECD等数据都是这样的。)
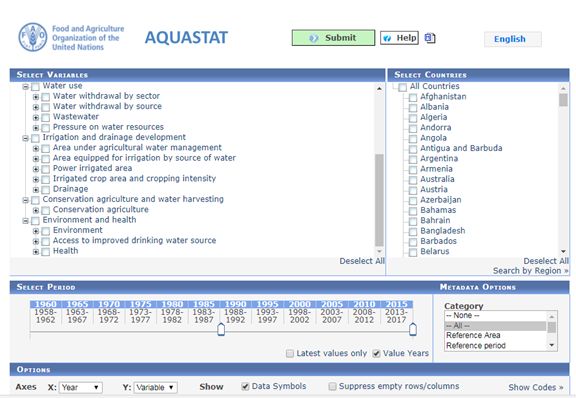
数据源简单介绍:
网站:http://www.fao.org/nr/water/aquastat/metadata/index.stm
组织的三个主要目标是:
1.消除饥饿、粮食不安全和营养不良
2.消除贫困促进经济社会进步
3.自然资源的可持续管理和利用,包括土地、水、空气、气候和遗传资源,以造福今世后代。
为支持这些目标,《宪法》第1条要求粮农组织“收集、分析、解释和传播与营养、粮食和农业有关的信息”。因此,水温自动调节器开始,其目的是通过收集有助于联合国粮农组织的目标,与水资源相关的信息传播分析,用水和农业用水管理,对国家重点在非洲,亚洲,美国,拉丁美洲,加勒比海。
联合国粮农组织提供数据,元数据,报告国家概况,河流域概况,分析区域,图,表空间,数据,指导方针,和其他的在线工具:
1、水资源:内部、跨界、总
2、水的用途:按部门,按来源,废水
3、灌溉:地点、面积、类型、技术、作物
4、水坝:位置,高度,容量,表面积
5、与水有关的机构、政策和立法
项目软件:软件python 3.6展示的软件Anaconda里面的jupster notebook,运行环境Window7,使用电脑Thinkpad T450。
项目计划:
通过对数据有简单的预估,这个时候,由于自己的电脑内存比较小,跑上十万以后的数据都会有明显的卡顿,为此采取了一个特殊的策略—使用Tidy Data进行试验。Tidy Data大家可能不熟悉,我直接也给大家上了干货。TidyData的官方解读:https://tomaugspurger.github.io/modern-5-tidy.html直接连接可以查看如何使用小批量的数据进行实验。
本实验的目标为三点:每个变量形成一个列,每个观测值形成一行,不同类型的观测单元组成一个表格。
数据转换:
1、取对数log:当数据的峰值很高,通过将数据取对数能够将数据归一化处理。
2、连续变量分组(bin):分组连续变量,能够更加简便的了解观测值的分布。
3、简化类别:一个单一的数据,往往类别太多会让人迷乱,一般不想超过8-10列,那就尽量找到重要的类别。(机器学习里面这一个部分很重要,和特征选择一样)
项目开始:
第一步,不可或缺的导入五大包:NumPy、Pandas、Matplotlib、Seaborn,Warnings大家对这四个包不熟悉的可以百度官方网站,有专门的材料。特别主要的就是Seaborn,这个库目前可视化的能力已经超过之前对Python的理解,有很多人说R可视化效果很好,但是我觉得这个可视化一点都不差。%matplotlib inline很多人不懂为什么会加上这个意思,这就是在jupter画图的时候,能够将可视化的图能够在结果中展现出来,我试过很多时候忘记加,结果图就只出现一行字。所以需要加上这个。

导入弹出红色烦人的warinngs包,让它们被忽略。

第二步,导入数据
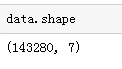
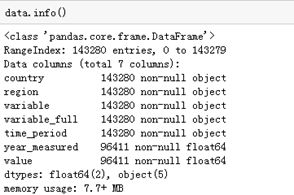
由于数据是压缩包的形式,我们平时一般的是CSV,TXT的格式,那我们可以试一试压缩包的读取方式。对数据进行基本的了解,Pandas为我们提供了很多可以简便查看和检查数据的方法。data.info(),data.shape,data.head(),data.tail()。
下面是结果的展示


第三步,探索变量
结果显示不全,但是把一些重要的变量进行解释一下:

total_area国土面积(1000公顷)
arable_land可耕作面积
permanent_crop_area多年生作物面积
cultivated_area耕地面积
percent_cultivated耕地面积占比
total_pop总人口
rural_pop农村人口
urban_pop城市人口
gdp国内生产总值
gdp_per_capita人均国内生产总值
agg_to_gdp农业,增加国内生产总值
human_dev_index人类发展指数
gender_inequal_index性别不平等指数
percent_undernourished营养不良患病率
avg_annual_rain_depth长期平均年降水量
national_rainfall_index全国降雨指数
第四步,简单的描述统计(后面对数据描述做详细的处理),某一列的数据的类别数据,缺失值的简单统计(后面会对缺失值详细处理),例如统计国家有多少个,时间段的统计,缺失值(国土面积)的统计




第五步,数据切分
面板数据一些基本定义
横截面:一个时期内所有国家的数据
时间序列:一个国家随着时间推移的数据
面板数据:所有国家随着时间的推移数据
地理空间:所有地理上相互关联的数据
1、时间切分,定义时间切分的函数,设置透视表,索引为国家,列为变量,值为对应的Value值。这个就是横截面数据生成。

查看时间1958-1962年阶段的值,使用time_slice函数使用结果
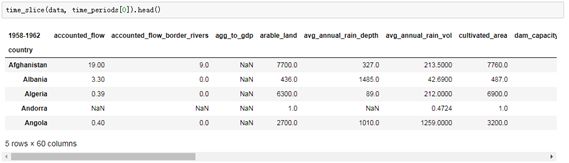
2、国家函数定义,索引为变量,列为每个时间阶段的变化,这个就是时间序列数据。
第四十个国家的结果


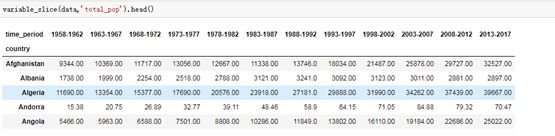
3、设置变量切分函数,索引为国家,列为时间变化,这个就是面板数据。

当变量为total_pop的人口的时候,面板数据如何?
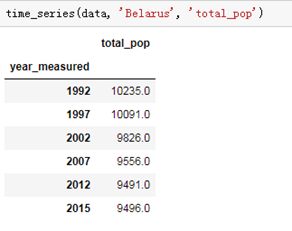
5、国家和变量二维的时间序列变化

当国家为Belarus和变量为total_pop时候的时间序列表,我们还可以通过改变国家和变量的名称来查看不同的时间序列结果
6、由于案例中区域划分层次太多,建立字典,将区域进行进一步简单划分:




首先查看区域有多少类别,通过结果发现,等级划分太频繁,为此我们进行了更进一步的简化,此处我们应用了lambda函数来进行简化地区的变更,其实可以应用replace函数来对应替换。其实用replace的效率会更高(http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.replace.html),我还放上一个replace的应用。
定义一个小的区域的函数

第六步,数据质量评估
评估缺失值数据在所有数据字段中的普遍性,评估其丢失是随机还是系统的,并在缺少数据是确定模式;
标签包含给定字段丢失数据的默认值;
确定质量评估抽样策略和初始EDA;
时间数据类型,保证格式的一致性和粒度的数据,并执行对数据的所有日期的检查;
在多个字段捕捉相同或者相似的信息的情况下,了解它们之间的关系并评估最有效的字段使用;
查看每个字段数据类型
对于离散值类型,确保数据格式一致,评估不同值和唯一百分比的数据,并对答案的类型进行正确检查
连续数据类型,进行描述性统计,并对值进行检查
1、导入三大包:missingno、pivottablejs、pandas_profiling
Missingnohttps://github.com/ResidentMario/missingno非常重要的一个包,可视化的展示数据缺失的分布情况,能够查看缺失值的分布情况,缺失数据有哪些原因,哪些地方有丢失?里面的柱状图,热力图都可视化效果很好。
Pivottalblejshttps://github.com/nicolaskruchten/jupyter_pivottablejs能够形成一个透视表,将每个变量形成统计。https://github.com/nicolaskruchten/pivottable
Pandas_profilinghttps://github.com/JosPolfliet/pandas-profiling/blob/master/examples/meteorites.ipynb
2、查看一个切分数据的缺失值,missingno工具包的使用
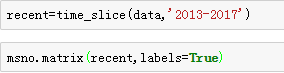
A、查看‘2013-2017’阶段的数据缺失,从输出值我们可以查看哪些国家、哪些变量缺失数据比较多,图的最后一列是data completeness我们可以看到国家的总的缺失情况,

B、还可以研究一下时间序列的数据缺失值情况:例如变量是水资源总量,”exploitable_total”,在每个时间段确实情况,为了把图展示的更漂亮,更加合理,把matplotlib的参数进行调整。从可视化的展示结果显示,只有一小部分国家报告了可利用的水资源总量,这些国家中只有极少数国家拥有最近一段时间的数据。我们将删除该变量,因为这么少的数据点会导致很多问题。


C、接着我们有研究了降雨量的数据缺失值研究,结果显示2002年以后就没有数据统计了,可以剔除该变量。


D、还记得我们之前定义过的subregion()函数吗?这个时候,我们就需要用上单一一个区域的数据缺失值的研究了。我们这个时候只研究2013-1017年北美洲数据的缺失值情况。从图的结果显示,从Haiti到后面的Dominica的55个变量有不同程度的数据缺失状况。此外我们针对最后的Dominica的缺失数据进行检查,找出这部分为什么会缺失?


3、通过地图查看folium工具包使用,每个国家缺失值数据的分布

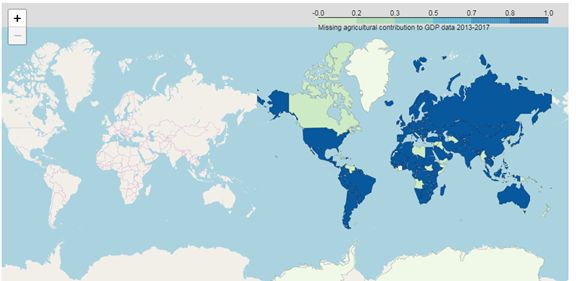
A、导入包folium,没有安装就常规的pip install folium包,还需要下载world.json(http://blog.csdn.net/chinagissoft/article/details/52136253),Choropleth图,分级统计图法可反映布满整个区域的现象(如地貌切割密度)、呈点状分布的现象(如居民点的密度)或线状分布的现象(如河流密度或道路网密度),但较多的是反映呈面状但属分散分布的现象,如反映人口密度、某农作物播种面积的比、人均收入等。此法因常用色级表示,故亦称色级统计图法。Pandas.notnull*1常规利用布尔值判断是否为空值,这里运用0或1标记。例如我们在案例运用了各国农业数据缺失对GDP数据的影响,我们从图中可以发现亚洲各国的数据缺失比较严重。
B、还可以查看2013-2017年阶段全球营养不良的缺失数据情况


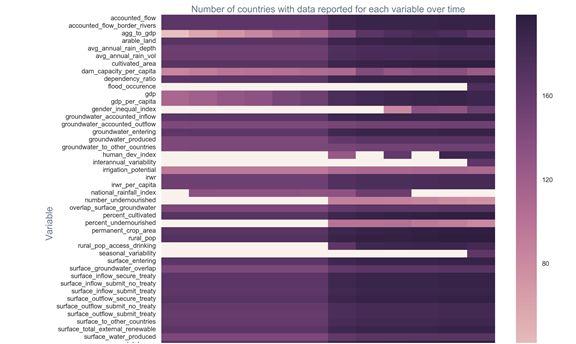
C、通过seaborn的热力图查看随着时间的每个国家对55个指标变量的重视程度变化趋势

4、pivottablejs包使用,查看数据相关性,也可以用于数据切分,和EXCEL的透视表功能相似。

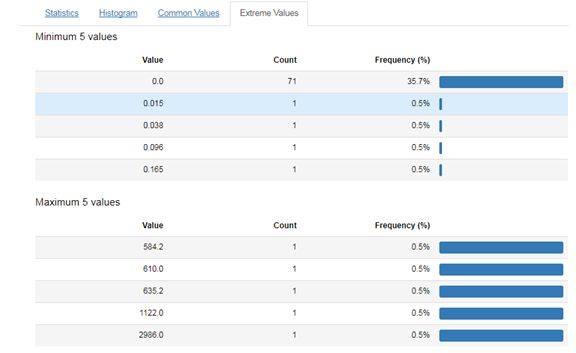
5、Pandas_profiling使用,数据质量探索的主要工具包,报表包来研究2013-2017年55个单变量数据的分布以及变量之间的相关系分析。首先对数据简单进行了一个统计性描述,会提示每个变量的缺失值情况,然后其中rejected表示由于和其他的变量之间的相关性很高,可以剔除改变量。此外还会告诉每个变量的分布,但是我们利用这个可能有一些问题,就是例如这里的total_pop可能因为和其他变量相关性比较高,所以rejected。所以后面我们会单独分析人口变量。





6、数据峰度和偏度的研究
忽略的人口变量变量,单变量的分析知识点引入,单变量峰度和偏度分析,
在每个变量的探索分析中,我们不难发现每个变量都会有Kurtosis和Skew,前面的是峰度,后面一个是偏度。峰度是描述总体中所有取值分布形态陡缓程度的统计量。这个统计量需要与正态分布相比较,峰度为0表示该总体数据分布与正态分布的陡缓程度相同;峰度大于0表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;峰度小于0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。峰度的绝对值数值越大表示其分布形态的陡缓程度与正态分布的差异程度越大。
峰度的具体计算公式为:

偏度与峰度类似,它也是描述数据分布形态的统计量,其描述的是某总体取值分布的对称性。这个统计量同样需要与正态分布相比较,偏度为0表示其数据分布形态与正态分布的偏斜程度相同;偏度大于0表示其数据分布形态与正态分布相比为正偏或右偏,即有一条长尾巴拖在右边,数据右端有较多的极端值;偏度小于0表示其数据分布形态与正态分布相比为负偏或左偏,即有一条长尾拖在左边,数据左端有较多的极端值。偏度的绝对值数值越大表示其分布形态的偏斜程度越大。
偏度的具体计算公式为:
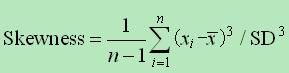
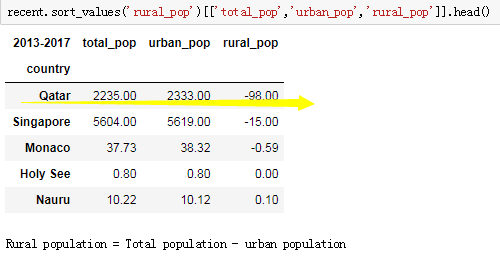
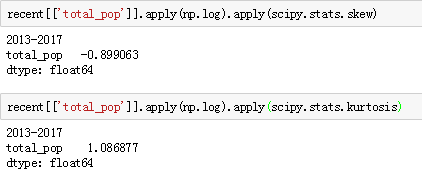
研究人口的分布情况,发现农村人口最小值里面有一个-98的异常值,于是就对这个农村人口进行深度研究,观察发现是Qatar这个地区的城市人口在2015年比总的人口高98,而且查看2015年之前的数据发现,前面的都是逐渐增长的,那可以判定这个-98和-13都有可能是一些异常值,或者是错误值。后面对峰度值和偏度值利用scipy都做了统计发现这两个指标都能得出。我们发现结果的峰值和偏值都比较大,可以做一个对数转换,对数变换是数据变换的一种常用方式,数据变换的目的在于使数据的呈现方式接近我们所希望的前提假设,从而更好的进行统计推断。




7、可视化分析
A、单变量的变化来分析总的人口变量变化

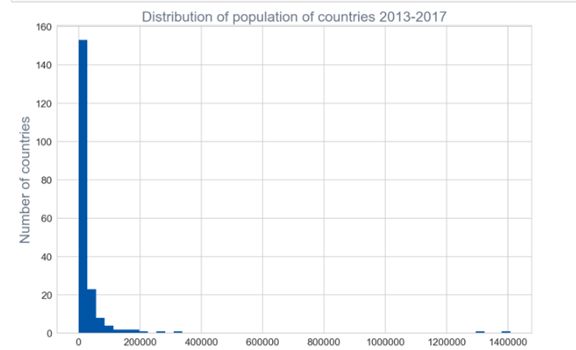
B、发现图形分布,没有我们看到的之前各种分布,可以通过对数转换,从新看看新的分布。
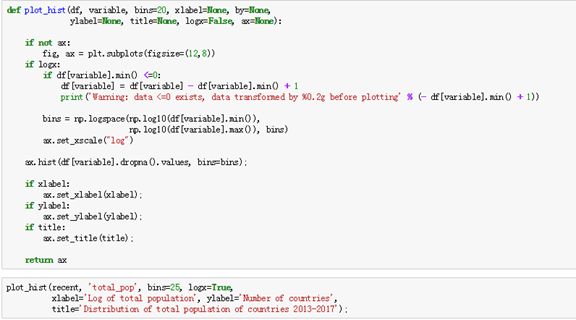
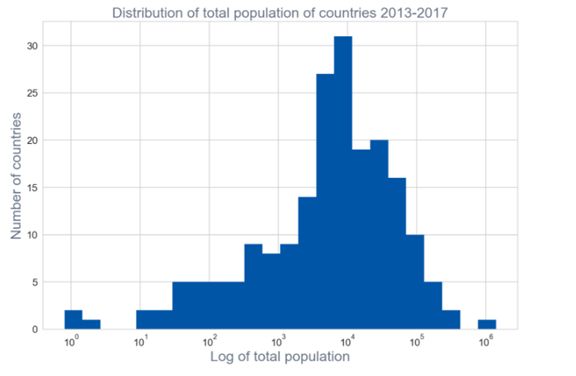
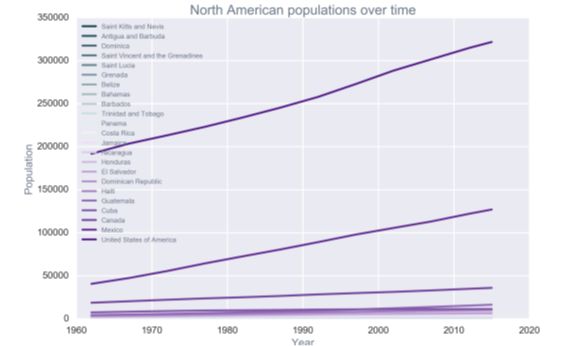
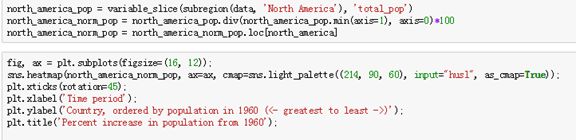
C、通过上面的人口的2013-2017年是一个左偏分布图。以下还列出了美国这个地区人口时间序列图,然后北美所有国家的人口随时间增长图,接着就是每个地区人口增长百分比,开始线条看着分辨不出每个国家的变化,用热力图就很明显的分辨每个地区的增长情况,这样就可以做一些分析,查找哪些地区增长的明显,为什么增长比其他地区明显,是否有战争或者大规模迁移导致,或者是现在生活条件变好,导致的人口增长。





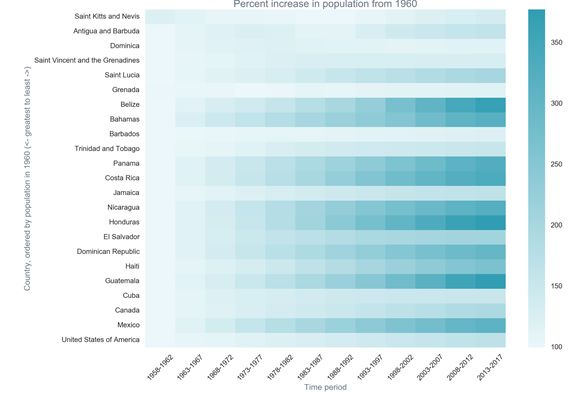
D、研究水资源变量随时间的变化,随地区的变化的情况。

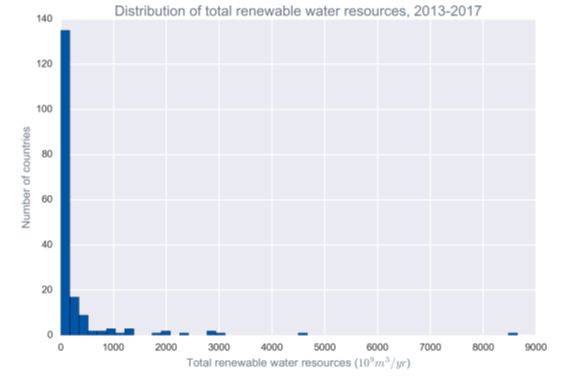


第七步,评估每个变量与目标变量之间的相关性。
变量分为两种,一种是离散变量,一个是连续变量。通过可视化的展示这些自变量的与因变量之间的相关性。
1、离散变量与离散变量
热力图(http://seaborn.pydata.org/generated/seaborn.heatmap.html?highlight=heatmap#seaborn.heatmap),
柱状图(http://seaborn.pydata.org/tutorial/categorical.html?highlight=bar%20plot#bar-plots)
2、离散变量与连续变量
箱体图http://seaborn.pydata.org/generated/seaborn.boxplot.html#seaborn.boxplot
小提琴图,http://seaborn.pydata.org/examples/simple_violinplots.html
直方图,http://seaborn.pydata.org/tutorial/distributions.html#histograms
3、连续变量与连续变量
散点图http://seaborn.pydata.org/examples/marginal_ticks.html?highlight=scatter
Hexbin图http://seaborn.pydata.org/tutorial/distributions.html#hexbin-plots
像高斯核图一样的图http://seaborn.pydata.org/tutorial/distributions.html#kernel-density-estimation
热力图http://seaborn.pydata.org/generated/seaborn.heatmap.html#seaborn.heatmap
联合图http://seaborn.pydata.org/generated/seaborn.jointplot.html#seaborn.jointplot
首先研究2013-2017年之间的seasonal_varality与GDP per captial之间的相关性,可以先用散点图来查看。


还可以用JointGrid画图,自动探索两个连续变量之间的相关性


多自变量与因变量之间的相关性研究,其他54个变量与GDP之间的正相关和负相关的比例,通过可视化展示。最后发现总的外在循环水资源的供应与人均GDP成负相关,
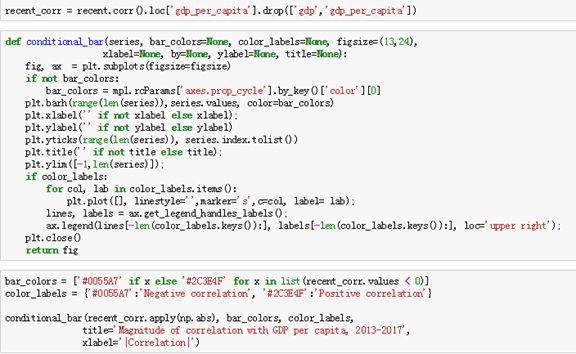

参考文献:网易云课堂《python数据分析与机器学习》,唐宇迪
附带国外一个kaggle案例的数据分析案例
https://www.kaggle.com/aselad/why-are-our-employees-leaving-prematurely/notebook