推荐系统-基于userCF推荐模型
时间:2017年5月
出处:http://blog.csdn.net/csearch/article/details/71244282
声明:版权所有,转载请联系作者并注明出
1.UserCF原理
基于用户的协同过滤推荐算法先使用统计技术寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的喜好产生目标用户的推荐。
基本原理就是利用用户访问行为的相似性来互相推荐用户可能感兴趣的资源,如下图所示:
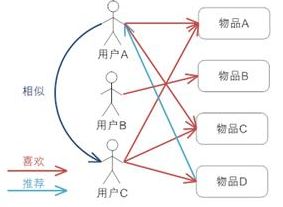
上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户A喜欢物品A、物品C,用户B喜欢物品B,用户C喜欢物品A、物品C和物品D;
从这些用户的历史喜好信息中,我们可以发现用户A和用户C的口味和偏好比较类似的,同事用户C还喜欢物品D,那么我们可以推断用户A可能也喜欢物品D,因此可以将物品D推荐给用户A。
基于用户协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合。
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
2.Python版本代码示例
2.1.读取数据集
from collections import defaultdict
# data_path = "../data/ml-1m/ratings.dat";sep = "::"
data_path = "../data/ml-100k/u1.base";sep = "\t"
fp = open(data_path, "r")
user2item_matrix = defaultdict(defaultdict) # 用户到物品的评分矩阵
item2user_matrix = defaultdict(defaultdict) # 物品到用户的倒排评分矩阵
# UserID \t MovieID \t Score \t Time
for line in open(data_path):
lines = line.strip().split(sep)
userID, movieID, score = lines[0],lines[1],lines[2]
user2item_matrix[userID][movieID] = float(score)
item2user_matrix[movieID][userID] = float(score)
fp.close()
print("totol users:",len(user2item_matrix))
print("totol items:",len(item2user_matrix))输出
(‘totol users:’, 943)
(‘totol items:’, 1650)
2.2.计算用户-用户相似度矩阵
步骤(1)的关键就是计算两个用户的兴趣相似度,协同过滤算法主要利用行为的相似度来计算兴趣的相似度。
给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。
那么,可以通过如下的Jaccard公式简单地计算u和v的兴趣相似度:
或者通过余弦相似度计算:
import math
def user_sim_cosine(user2item_matrix):
W = defaultdict(defaultdict) # 用户-用户-相似度矩阵
user_list = user2item_matrix.keys()
for i in user_list:
for j in user_list:
if i==j:
continue
W[i][j] = len(set(user2item_matrix[i].keys()) & set(user2item_matrix[j].keys()))
W[i][j] /= math.sqrt(len(user2item_matrix[i].keys())*len(user2item_matrix[j].keys())*1.0)
return W
%time W = user_sim_cosine(user2item_matrix)输出
CPU times: user 12.4 s, sys: 244 ms, total: 12.7 s
Wall time: 12.5 s
3.3.基于用户-用户相似度矩阵,进行TopK排序推荐
import operator
def recommend(user2item_matrix, user_id, W, K=10):
'''通过用户userid、训练集数据、用户相似度矩阵进行topN推荐'''
rank=defaultdict(int)
# 获取用户的物品列表
user_item_set = user2item_matrix[user_id].keys()
# 遍历与该user_id相似的用户和相似度得分
for w_userid,w_score in sorted(W[user_id].items(),key=operator.itemgetter(1),reverse=True)[0:K]:
# 遍历相似用户看过的物品与打分
for item_id,item_score in user2item_matrix[w_userid].items():
# 如果相似用户看过的电影也在目标用户的物品集合中,则忽略该物品的推荐
if item_id in user_item_set:
continue
# 计算该物品推荐给用户的排序分
rank[item_id] = w_score*item_score
# 对所有推荐物品与打分按照排序分进行降序排序,取前K个物品
rank_list = sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:K]
return rank_list
%time print recommend(user2item_matrix,'5',W,3)输出
[(‘343’, 1.7452803288387695), (‘271’, 1.7452803288387695), (‘1239’, 1.7452803288387695)]
CPU times: user 1.72 ms, sys: 317 µs, total: 2.04 ms
Wall time: 1.8 ms