hive的3种数据存储格式
hive有textFile,SequenceFile,RCFile三种文件格式。
其中textfile为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。
SequenceFile,RCFile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中,然后再从textfile表中用insert导入到SequenceFile,RCFile表中。
create table zone0000rc(ra int, dec int, mag int) row format delimited fields terminated by '|' stored as rcfile;
load data local inpath '/home/cq/usnoa/zone0000.asc ' into table zone0000tf;
insert overwrite table zone0000rc select * from zone0000tf;(begin a job)
File Format
| TextFile |
SequenceFIle |
RCFFile |
|
| Data type |
Text Only |
Text/Binary |
Text/Binary |
| Internal Storage Order |
Row-based |
Row-based |
Column-based |
| Compression |
File Based |
Block Based |
Block Based |
| Splitable |
YES |
YES |
YES |
| Splitable After Compression |
No |
YES |
YES |
源数据放在test1表中,大小 26413896039 Byte。
创建sequencefile 压缩表test2,使用insert overwrite table test2 select ...语句将test1数据导入 test2 ,设置配置项:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
SET io.seqfile.compression.type=BLOCK;
set io.compression.codecs=com.hadoop.compression.lzo.LzoCodec;
导入耗时:98.528s。另压缩类型使用默认的record,耗时为418.936s。
创建rcfile 表test3 ,同样方式导入test3。
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
set io.compression.codecs=com.hadoop.compression.lzo.LzoCodec;
导入耗时 253.876s。
以下为其他统计数据对比:
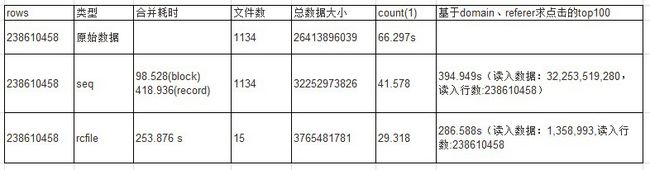
| rows | 类型 | 合并耗时 | 文件数 | 总数据大小 | count(1) | 基于domain、referer求点击的top100 |
| 238610458 | 原始数据 | 1134 | 26413896039 | 66.297s | ||
| 238610458 | seq | 98.528(block) 418.936(record) | 1134 | 32252973826 | 41.578 | 394.949s(读入数据:32,253,519,280,读入行数:238610458) |
| 238610458 | rcfile | 253.876 s | 15 | 3765481781 | 29.318 | 286.588s(读入数据:1,358,993,读入行数:238610458 |
因为原始数据中均是小文件,所以合并后文件数大量减少,但是hive实现的seqfile 处理竟然还是原来的数目。rcfile 使用lzo 压缩效果明显,7倍的压缩比率。查询数据中读入数据因为这里这涉及小部分数据,所以rcfile的表读入数据仅是seqfile的4%.而读入行数一致。
SequeceFile是Hadoop API提供的一种二进制文件支持。这种二进制文件直接将
1)支持压缩,且可定制为基于Record或Block压缩(Block级压缩性能较优)
2)本地化任务支持:因为文件可以被切分,因此MapReduce任务时数据的本地化情况应该是非常好的。
3)难度低:因为是Hadoop框架提供的API,业务逻辑侧的修改比较简单。
坏处是需要一个合并文件的过程,且合并后的文件将不方便查看。
SequenceFile 是一个由二进制序列化过的key/value的字节流组成的文本存储文件,它可以在map/reduce过程中的input/output 的format时被使用。在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。
SequenceFile分别提供了读、写、排序的操作类。
SequenceFile的操作中有三种处理方式:
1) 不压缩数据直接存储。 //enum.NONE
2) 压缩value值不压缩key值存储的存储方式。//enum.RECORD
3)key/value值都压缩的方式存储。//enum.BLOCK
工作中用到了RcFile来存储和读取RcFile格式的文件,记录下。
RcFile是FaceBook开发的一个集行存储和列存储的优点于一身,压缩比更高,读取列更快,它在MapReduce环境中大规模数据处理中扮演着重要的角色。
读取操作:
- job信息:
- Job job = new Job();
- job.setJarByClass(类.class);
- //设定输入文件为RcFile格式
- job.setInputFormatClass(RCFileInputFormat.class);
- //普通输出
- job.setOutputFormatClass(TextOutputFormat.class);
- //设置输入路径
- RCFileInputFormat.addInputPath(job, new Path(srcpath));
- //MultipleInputs.addInputPath(job, new Path(srcpath), RCFileInputFormat.class);
- // 输出
- TextOutputFormat.setOutputPath(job, new Path(respath));
- // 输出key格式
- job.setOutputKeyClass(Text.class);
- //输出value格式
- job.setOutputValueClass(NullWritable.class);
- //设置mapper类
- job.setMapperClass(ReadTestMapper.class);
- //这里没设置reduce,reduce的操作就是读Text类型文件,因为mapper已经给转换了。
- code = (job.waitForCompletion(true)) ? 0 : 1;
- // mapper 类
- pulic class ReadTestMapper extends Mapper
- @Override
- protected void map(LongWritable key, BytesRefArrayWritable value, Context context) throws IOException, InterruptedException {
- // TODO Auto-generated method stub
- Text txt = new Text();
- //因为RcFile行存储和列存储,所以每次进来的一行数据,Value是个列簇,遍历,输出。
- StringBuffer sb = new StringBuffer();
- for (int i = 0; i < value.size(); i++) {
- BytesRefWritable v = value.get(i);
- txt.set(v.getData(), v.getStart(), v.getLength());
- if(i==value.size()-1){
- sb.append(txt.toString());
- }else{
- sb.append(txt.toString()+"\t");
- }
- }
- context.write(new Text(sb.toString()),NullWritable.get());
- }
- }
job信息:
Job job = new Job();
job.setJarByClass(类.class);
//设定输入文件为RcFile格式
job.setInputFormatClass(RCFileInputFormat.class);
//普通输出
job.setOutputFormatClass(TextOutputFormat.class);
//设置输入路径
RCFileInputFormat.addInputPath(job, new Path(srcpath));
//MultipleInputs.addInputPath(job, new Path(srcpath), RCFileInputFormat.class);
// 输出
TextOutputFormat.setOutputPath(job, new Path(respath));
// 输出key格式
job.setOutputKeyClass(Text.class);
//输出value格式
job.setOutputValueClass(NullWritable.class);
//设置mapper类
job.setMapperClass(ReadTestMapper.class);
//这里没设置reduce,reduce的操作就是读Text类型文件,因为mapper已经给转换了。
code = (job.waitForCompletion(true)) ? 0 : 1;
// mapper 类
pulic class ReadTestMapper extends Mapper {
@Override
protected void map(LongWritable key, BytesRefArrayWritable value, Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
Text txt = new Text();
//因为RcFile行存储和列存储,所以每次进来的一行数据,Value是个列簇,遍历,输出。
StringBuffer sb = new StringBuffer();
for (int i = 0; i < value.size(); i++) {
BytesRefWritable v = value.get(i);
txt.set(v.getData(), v.getStart(), v.getLength());
if(i==value.size()-1){
sb.append(txt.toString());
}else{
sb.append(txt.toString()+"\t");
}
}
context.write(new Text(sb.toString()),NullWritable.get());
}
}
输出压缩为RcFile格式:
- job信息:
- Job job = new Job();
- Configuration conf = job.getConfiguration();
- //设置每行的列簇数
- RCFileOutputFormat.setColumnNumber(conf, 4);
- job.setJarByClass(类.class);
- FileInputFormat.setInputPaths(job, new Path(srcpath));
- RCFileOutputFormat.setOutputPath(job, new Path(respath));
- job.setInputFormatClass(TextInputFormat.class);
- job.setOutputFormatClass(RCFileOutputFormat.class);
- job.setMapOutputKeyClass(LongWritable.class);
- job.setMapOutputValueClass(BytesRefArrayWritable.class);
- job.setMapperClass(OutPutTestMapper.class);
- conf.set("date", line.getOptionValue(DATE));
- //设置压缩参数
- conf.setBoolean("mapred.output.compress", true);
- conf.set("mapred.output.compression.codec", "org.apache.hadoop.io.compress.GzipCodec");
- code = (job.waitForCompletion(true)) ? 0 : 1;
- mapper类:
- public class OutPutTestMapper extends Mapper
- @Override
- public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String line = value.toString();
- String day = context.getConfiguration().get("date");
- if (!line.equals("")) {
- String[] lines = line.split(" ", -1);
- if (lines.length > 3) {
- String time_temp = lines[1];
- String times = timeStampDate(time_temp);
- String d = times.substring(0, 10);
- if (day.equals(d)) {
- byte[][] record = {lines[0].getBytes("UTF-8"), lines[1].getBytes("UTF-8"),lines[2].getBytes("UTF-8"), lines[3].getBytes("UTF-8")};
- BytesRefArrayWritable bytes = new BytesRefArrayWritable(record.length);
- for (int i = 0; i < record.length; i++) {
- BytesRefWritable cu = new BytesRefWritable(record[i], 0, record[i].length);
- bytes.set(i, cu);
- }
- context.write(key, bytes);
- }
- }
- }
- }
SequenceFile提供了若干Writer的构造静态获取。
//SequenceFile.createWriter();
SequenceFile.Reader使用了桥接模式,可以读取SequenceFile.Writer中的任何方式的压缩数据。
三种不同的压缩方式是共用一个数据头,流方式的读取会先读取头字节去判断是哪种方式的压缩,然后根据压缩方式去解压缩并反序列化字节流数据,得到可识别的数据。
流的存储头字节格式:
Header:
*字节头”SEQ”, 后跟一个字节表示版本”SEQ4”,”SEQ6”.//这里有点忘了 不记得是怎么处理的了,回头补上做详细解释
*keyClass name
*valueClass name
*compression boolean型的存储标示压缩值是否转变为keys/values值了
*blockcompression boolean型的存储标示是否全压缩的方式转变为keys/values值了
*compressor 压缩处理的类型,比如我用Gzip压缩的Hadoop提供的是GzipCodec什么的..
*元数据 这个大家可看可不看的
所有的String类型的写操作被封装为Hadoop的IO API,Text类型writeString()搞定。
未压缩的和只压缩values值的方式的字节流头部是类似的:
*Header
*RecordLength记录长度
*key Length key值长度
*key 值
*是否压缩标志 boolean
*values
剩下的大家可看可不看的,并非这个类中主要的。
方案一:
方案四: