机器学习深度学习中反向传播之偏导数链式法则
前记
无论是机器学习还是深度学习,都是构造目标函数,这个目标函数内部有很多未知变量,我们的目标就是求得这些未知变量。
那么如何构造目标函数?这是一个非常优美的话题(本文未讲,先欠着)。美好的目标函数求未知数的偏导数是一个漂亮表达式,会让你惊叹到数学如此婀娜多娇。
如果有人能够求得未知变量的解析表达式,那该是多么幸福的事情,现实是残酷的。(我知道你想说伪逆是最小二乘的解析表达式,然后呢……难道你就打算只学会一个最简单的最小二乘吗?)。为此大部分都是采用梯度下降(那些别的神奇的算法都是基于梯度下降),那何为梯度下降?
如: L = f ( x ) L=f(x) L=f(x),采用泰勒(不认识泰勒,就假装不存在这两个字)一阶导数展开:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) f(x) = f(x_0)+f^{'}(x_0)(x-x_0) f(x)=f(x0)+f′(x0)(x−x0)
想求得 f ( x ) f(x) f(x)的最小值,我先蒙一个 x 0 x_0 x0,然后我就拼命的更新 x n e w x^{new} xnew,令每次更新的差值为 Δ x = x n e w − x 0 \Delta x = x^{new}-x_0 Δx=xnew−x0,则:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) = f ( x 0 ) + f ′ ( x 0 ) Δ x f(x) = f(x_0)+f^{'}(x_0)(x-x_0)= f(x_0)+f^{'}(x_0)\Delta x f(x)=f(x0)+f′(x0)(x−x0)=f(x0)+f′(x0)Δx
当 Δ x = − η ⋅ f ′ ( x 0 ) ( η > 0 ) \Delta x = -\eta \cdot f^{'}(x_0) (\eta>0) Δx=−η⋅f′(x0)(η>0)时,
f ( x ) = f ( x 0 ) − η ⋅ f ′ 2 ( x 0 ) f(x) = f(x_0) - \eta \cdot f^{'^~2}(x_0) f(x)=f(x0)−η⋅f′ 2(x0)
至少我每次 f ( x n e w ) f(x^{new}) f(xnew)总比我之前 f ( x 0 ) f(x_0) f(x0) 要减少一点点 η ⋅ f ′ 2 ( x 0 ) \eta \cdot f^{'^~2}(x_0) η⋅f′ 2(x0)吧(此话不严谨,因为学习率很大的时候,你就会筐瓢)。那个 η \eta η就是梯度学习率。
如果你觉得不够精确,我要在二阶泰勒展开,那就是“牛顿法”。
本文通篇就是在围绕着如何求一阶导数展开。
如何求解一阶导数
学习数学,总是在学习的时候很痛苦,这个鬼画符得出的结论要表达什么?我学了有什么用?用起来的时候发现“数学真香”。所以本文尽量每讲一个知识点时都拼凑深度学习或者机器学习中的知识点。
先刷一个链式法则:
所谓的链式法则,其实就是把一个个好大巴大的函数当做一个整体,求全微分,然后逐步肢解一个个内部函数。

如图所示, J = F ( f ( x ) , g ( x ) ) J = F(f(x),g(x)) J=F(f(x),g(x));
求全微分:
Δ J = F f ′ ⋅ Δ f + F g ′ ⋅ Δ g \Delta J = F^{'}_{f}\cdot \Delta f + F^{'}_{g}\cdot \Delta g ΔJ=Ff′⋅Δf+Fg′⋅Δg
又因为: Δ f = f ′ ⋅ Δ x ; Δ g = g ′ ⋅ Δ x \Delta f = f^{'}\cdot\ \Delta x;\Delta g = g^{'}\cdot\ \Delta x Δf=f′⋅ Δx;Δg=g′⋅ Δx从而:
Δ J = F f ′ ⋅ f ′ ⋅ Δ x + F g ′ ⋅ g ′ ⋅ Δ x \Delta J = F^{'}_{f}\cdot f^{'}\cdot\ \Delta x+ F^{'}_{g}\cdot g^{'}\cdot\ \Delta x ΔJ=Ff′⋅f′⋅ Δx+Fg′⋅g′⋅ Δx
写成链式:
∂ J ∂ x = ∂ J ∂ f ⋅ ∂ f ∂ x + ∂ J ∂ g ⋅ ∂ g ∂ x \frac{\partial J}{\partial x} = \frac{\partial J}{\partial f}\cdot\frac{\partial f}{\partial x}+\frac{\partial J}{\partial g}\cdot\frac{\partial g}{\partial x} ∂x∂J=∂f∂J⋅∂x∂f+∂g∂J⋅∂x∂g
总结一下链式法则,总是需要找到变量至目标的路径,然后依次从后往前展开。
1.实数对向量求偏导
f ( x ) = a T x = x T a f(x) = \bm{a}^T\bm{x}= \bm{x}^T\bm{a} f(x)=aTx=xTa
其中 x = [ x 1 , x 2 , x i , . . . , x n ] T , a = [ a 1 , a 2 , a i , . . . , a n ] T \bm{x}=[x_1,x_2,x_i,...\ ,x_n]^T,\bm{a}=[a_1,a_2,a_i,...\ ,a_n]^T x=[x1,x2,xi,... ,xn]T,a=[a1,a2,ai,... ,an]T
∵ f ( x ) = ∑ i = 1 n a i x i \because f(x) = \sum\limits_{i=1}^n a_ix_i ∵f(x)=i=1∑naixi
∂ f ∂ x i = a i \frac{\partial f}{\partial x_i} = a_i ∂xi∂f=ai
∴ ∂ f ∂ x = [ a 1 , a 2 , a i , . . . , a n ] T = a \therefore\quad\frac{\partial f}{\partial \bm{x}} =[a_1,a_2,a_i,...\ ,a_n]^T=\bm{a} ∴∂x∂f=[a1,a2,ai,... ,an]T=a
一个实数对一个列向量求导数,结果还是一个列向量。其实记忆起来就按照 f ( x ) = a ⋅ x , ( a , x 为 实 数 ) f(x) =a\cdot x,(a,x为实数) f(x)=a⋅x,(a,x为实数)来记忆,只是结果必须要与维度对齐。
个人建议所有的导数在不太熟悉的情况下,对向量以及矩阵求导都要带上维度。
比如 f ( x ) = x T a f(x) = \bm{x}^T\bm{a} f(x)=xTa, f ( x ) f(x) f(x)对x求导数立马想到 f ( x ) = a ⋅ x f(x)=a\cdot x f(x)=a⋅x,这个肯定知道一元函数的导数: f ′ ( x ) = a f'(x)=a f′(x)=a,但是还在犹豫当对向量求偏导数时,结果为 a a a还是 a T a^T aT ?显然对列向量偏导数应该还是为列向量,因此:
f ′ ( x ) n × 1 = a n × 1 \mathop{f'(x)}\limits_{n\times1}=\mathop{\bm{a}}\limits_{n\times1} n×1f′(x)=n×1a
现在就可以轻松应对机器学习中的LR(逻辑斯蒂回归)分析(仅考虑一个样本样本,该样本的信息为 x \bm{x} x向量,标签为y取值等于0或者等于1)。
z = ω T x z = \bm{\omega}^T\bm{x} z=ωTx
a = f ( z ) = 1 1 + e − z a = f(z)=\frac{1}{1+e^{-z}} a=f(z)=1+e−z1
损 失 函 数 : J = − y l n ( a ) − ( 1 − y ) l n ( 1 − a ) 损失函数:J=-yln(a)-(1-y)ln(1-a) 损失函数:J=−yln(a)−(1−y)ln(1−a)
求得 ∂ J / ∂ z = ( ∂ J / ∂ a ) ⋅ ( ∂ a / ∂ z ) = ( a − y ) \partial J/\partial z =(∂J/∂a)\cdot(∂a/∂z)= (a-y) ∂J/∂z=(∂J/∂a)⋅(∂a/∂z)=(a−y)
由实数对向量求偏导的结论, ∂ z / ∂ ω = x \partial z/\partial\bm{\omega} = \bm{x} ∂z/∂ω=x
∂ J / ∂ ω = ( ∂ J / ∂ z ) ⋅ ( ∂ z / ∂ ω ) = ( a − y ) ⋅ x \partial J/\partial \bm{\omega} =(∂J/∂z)\cdot(∂z/∂\bm{\omega})= (a-y)\cdot \ \bm{x} ∂J/∂ω=(∂J/∂z)⋅(∂z/∂ω)=(a−y)⋅ x
是不是发现 b b b不见了,将 x \bm{x} x扩展为 [ x ; 1 ] [\bm{x};1] [x;1], ω \bm{\omega} ω扩展为 [ ω ; b ] [\bm{\omega};b] [ω;b]即可。
2.向量对向量、矩阵求偏导
先给出多层全连接神经网络并经过 s o f t m a x softmax softmax进行m个分类的结构图。
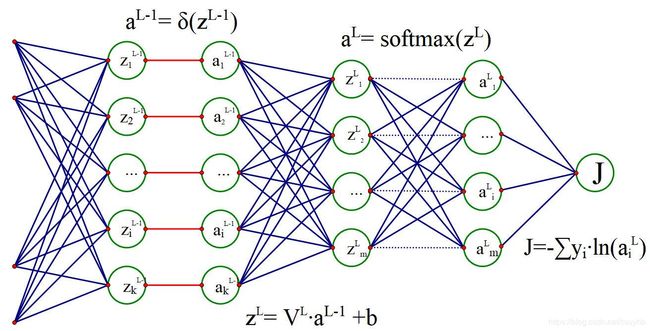
目的是求得所有层之间的V和b参数,因为所有的 z i → a i z^i\to a^i zi→ai为非线性函数,且未含有任何需要辨识的参数。除了最后的 s o f t m a x softmax softmax,甚至所有的非线性函数都是单输入单输出函数。
2.1从后往前递推,先求 ∂ J / ∂ z L \partial J/\partial z^L ∂J/∂zL,其结论为:
∂ J / ∂ z L = a L − y \partial J/\partial z^L=a^L-\bm{y} ∂J/∂zL=aL−y
似曾相识,和LR中 ∂ J / ∂ z = ( ∂ J / ∂ a ) ⋅ ( ∂ a / ∂ z ) = ( a − y ) \partial J/\partial z =(∂J/∂a)\cdot(∂a/∂z)= (a-y) ∂J/∂z=(∂J/∂a)⋅(∂a/∂z)=(a−y)型式相同,这就是前记中描述的,构造较好的目标函数能够得到漂亮的数学型式。
关于 s o f t m a x softmax softmax层的偏导数求法,本文不做进一步分析,搜索“softmax反向传播”,都有详细的推导。只说一下思路,以对 z i L z^L_i ziL一个元素求偏导为例,先要 J J J对所有的 a j L a^L_j ajL求偏导,因为 a L a^L aL层所有元素都与 z i L z^L_i ziL有关系,而且当 j ̸ = i j\not=i j̸=i时, a j L a^L_j ajL仅有分母中含有 z i L z^L_i ziL; j = i j=i j=i时, a j L a^L_j ajL分子、分母中含有 z i L z^L_i ziL(这就是上图中softmax层我将水平连接线画成了虚线,以与 j ̸ = i j\not=i j̸=i区别开)。
2.2继续求 ∂ J / ∂ a L − 1 \partial J/\partial a^{L-1} ∂J/∂aL−1
上面已经求得 ∂ J / ∂ z L \partial J/\partial z^L ∂J/∂zL,现在找其与 ∂ J / ∂ a L − 1 \partial J/\partial a^{L-1} ∂J/∂aL−1的关系。
z L = V L ⋅ a L − 1 z^L = V^L\cdot \ a^{L-1} zL=VL⋅ aL−1
∴ Δ z L ⟹ V L ⋅ Δ a L − 1 \therefore \Delta z^L \Longrightarrow V^L\cdot \ \Delta a^{L-1} ∴ΔzL⟹VL⋅ ΔaL−1
Δ J ⇒ ( ∂ J ∂ z L ) T ⋅ Δ z L ⇒ ( ∂ J ∂ z L ) T ⋅ ( V L ⋅ Δ a L − 1 ) ⇒ ( ∂ J ∂ z L ) T ⋅ V L ⋅ Δ a L − 1 ⇒ ( ( V L ) T ⋅ ∂ J ∂ z L ) T ⋅ Δ a L − 1 \begin{aligned} \Delta J & \Rightarrow (\frac{\partial J}{\partial z^L})^T\cdot\Delta z^L\\ & \Rightarrow (\frac{\partial J}{\partial z^L})^T\cdot\ (V^L\cdot \ \Delta a^{L-1}) \\ &\Rightarrow (\frac{\partial J}{\partial z^L})^T\cdot\ V^L\cdot\Delta a^{L-1}\\ &\Rightarrow ((V^{L})^T\cdot\frac{\partial J}{\partial z^L})^T\cdot\Delta a^{L-1}\\ \end{aligned} ΔJ⇒(∂zL∂J)T⋅ΔzL⇒(∂zL∂J)T⋅ (VL⋅ ΔaL−1)⇒(∂zL∂J)T⋅ VL⋅ΔaL−1⇒((VL)T⋅∂zL∂J)T⋅ΔaL−1
同时:
Δ J ⇒ ( ∂ J ∂ a L − 1 ) T ⋅ Δ a L − 1 \Delta J \Rightarrow (\frac{\partial J}{\partial a^{L-1}})^T\cdot\Delta a^{L-1} ΔJ⇒(∂aL−1∂J)T⋅ΔaL−1
与上面的“等式”对比可知:
(1) ∴ ∂ J ∂ a L − 1 = ( V L ) T ⋅ ∂ J ∂ z L \therefore\frac{\partial J}{\partial a^{L-1}} = (V^{L})^T\cdot\frac{\partial J}{\partial z^L} \tag{1} ∴∂aL−1∂J=(VL)T⋅∂zL∂J(1)
“ ⇒ ” “\Rightarrow” “⇒”这个符号在本文中意味着啥?先别急,你就当做一个等于号来看待最后再解释。
2.3继续求 ∂ J / ∂ V L \partial J/\partial V^{L} ∂J/∂VL
这次打算从最基本的 V L V^L VL矩阵单个元素 V i j L V^L_{ij} VijL处理开始,然后逐步分析行 V i 行 L V^L_{i行} Vi行L,然得出整个矩阵的偏导数 ∂ J / ∂ V L \partial J/\partial V^{L} ∂J/∂VL。
∵ ∂ z i L ( z i L = V i 行 ⋅ a L − 1 ) ∂ V i j = a j L − 1 \because \frac{\partial z^L_i(z^L_i = V_{i行}\cdot a^{L-1})}{\partial V_{ij}} =a^{L-1}_j ∵∂Vij∂ziL(ziL=Vi行⋅aL−1)=ajL−1
(对单个元素求偏导) ∴ ∂ J ∂ V i j = ∂ J ∂ z i L ⋅ ∂ z i L ∂ V i j = ∂ J ∂ z i L ⋅ a j L − 1 \therefore \frac{\partial J}{\partial V_{ij}} = \frac{\partial J}{\partial z^L_i} \cdot \frac{\partial z^L_i}{\partial V_{ij}} = \frac{\partial J}{\partial z^L_i}\cdot a^{L-1}_j \tag{对单个元素求偏导} ∴∂Vij∂J=∂ziL∂J⋅∂Vij∂ziL=∂ziL∂J⋅ajL−1(对单个元素求偏导)
(对行求偏导) ∴ ∂ J ∂ V i 行 = ∂ J ∂ z i L ⋅ ( a L − 1 ) T \therefore \frac{\partial J}{\partial V_{i行}} = \frac{\partial J}{\partial z^L_i}\cdot (a^{L-1})^T \tag{对行求偏导} ∴∂Vi行∂J=∂ziL∂J⋅(aL−1)T(对行求偏导)
扩展至对矩阵求偏导:
(2) ∴ ∂ J ∂ V = [ ∂ J ∂ z 1 L ⋅ ( a L − 1 ) T ⋮ ∂ J ∂ z m L ⋅ ( a L − 1 ) T ] = ∂ J ∂ z L ⋅ ( a L − 1 ) T \therefore \frac{\partial J}{\partial V} =\left[ \begin{matrix} \frac{\partial J}{\partial z^L_1}\cdot (a^{L-1})^T \\ \vdots \\ \frac{\partial J}{\partial z^L_m}\cdot (a^{L-1})^T \end{matrix} \right] = \frac{\partial J}{\partial z^L}\cdot (a^{L-1})^T \tag{2} ∴∂V∂J=⎣⎢⎢⎡∂z1L∂J⋅(aL−1)T⋮∂zmL∂J⋅(aL−1)T⎦⎥⎥⎤=∂zL∂J⋅(aL−1)T(2)
关于对 V V V的偏导数求法是按照定义,一五一十一板一眼的求,后面在解释" ⇒ \Rightarrow ⇒"符号时,会进一步通过矩阵的方法来获得相同的表达式。
继续求 ∂ J / ∂ z L − 1 \partial J/\partial z^{L-1} ∂J/∂zL−1
以图中 a L − 1 = δ ( z L − 1 ) a^{L-1} = \delta(z^{L-1}) aL−1=δ(zL−1)为例,显然: ∂ a i L − 1 / ∂ z i L − 1 = δ ( z i L − 1 ) ⋅ ( 1 − δ ( z i L − 1 ) ) \partial a^{L-1}_i/\partial z^{L-1}_i = \delta(z^{L-1}_i)\cdot(1-\delta(z^{L-1}_i)) ∂aiL−1/∂ziL−1=δ(ziL−1)⋅(1−δ(ziL−1))
∴ ∂ J / ∂ z = ∂ J ∂ a ⊙ ∂ a ∂ z = ∂ J ∂ a ⊙ δ ( z L − 1 ) ⊙ ( 1 − δ ( z L − 1 ) ) \therefore \partial J/\partial z =\frac{\partial J}{\partial a} \odot \frac{\partial a}{\partial z}= \frac{\partial J}{\partial a} \odot \delta(z^{L-1})\odot(1-\delta(z^{L-1})) ∴∂J/∂z=∂a∂J⊙∂z∂a=∂a∂J⊙δ(zL−1)⊙(1−δ(zL−1))
检查一下这个表达式中,所有 ⊙ \odot ⊙两边的表达式都为 k × 1 k\times1 k×1维的列向量。个人感觉上式凭直觉是显而易见的,下面开始推导:
∂ J ∂ a ⊙ Δ a ⇒ ∂ J ∂ a ⊙ [ δ ( z L − 1 ) ⊙ ( 1 − δ ( z L − 1 ) ) ⊙ Δ z ] ⇒ [ ∂ J ∂ a ⊙ δ ( z L − 1 ) ⊙ ( 1 − δ ( z L − 1 ) ) ] ⊙ Δ z \begin{aligned} \frac{\partial J}{\partial a} \odot \Delta a &\Rightarrow\frac{\partial J}{\partial a}\odot [\delta(z^{L-1})\odot(1-\delta(z^{L-1}))\odot \Delta z] \\ &\Rightarrow [\frac{\partial J}{\partial a} \odot\delta(z^{L-1})\odot(1-\delta(z^{L-1}))]\odot \Delta z\end{aligned} ∂a∂J⊙Δa⇒∂a∂J⊙[δ(zL−1)⊙(1−δ(zL−1))⊙Δz]⇒[∂a∂J⊙δ(zL−1)⊙(1−δ(zL−1))]⊙Δz
上式为左右两个列向量"相等",代表 两个列向量所有元素对应相等,那两边向量元素和也必然相等。
Δ J ⇒ ( ∂ J ∂ a ) T ⋅ Δ a ⇒ [ ∂ J ∂ a ⊙ δ ( z L − 1 ) ⊙ ( 1 − δ ( z L − 1 ) ) ] T ⋅ Δ z \Delta J \Rightarrow(\frac{\partial J}{\partial a})^T \cdot \Delta a \Rightarrow [\frac{\partial J}{\partial a} \odot\delta(z^{L-1})\odot(1-\delta(z^{L-1}))]^T\cdot\ \Delta z ΔJ⇒(∂a∂J)T⋅Δa⇒[∂a∂J⊙δ(zL−1)⊙(1−δ(zL−1))]T⋅ Δz
同时: Δ J ⇒ ( ∂ J ∂ z L − 1 ) T ⋅ Δ z L − 1 \Delta J \Rightarrow(\frac{\partial J}{\partial z^{L-1}})^T\cdot\Delta z^{L-1} ΔJ⇒(∂zL−1∂J)T⋅ΔzL−1
(3) ∴ ∂ J / ∂ z L − 1 = ∂ J ∂ a L − 1 ⊙ δ ( z L − 1 ) ⊙ ( 1 − δ ( z L − 1 ) ) \therefore\partial J/\partial z^{L-1} =\frac{\partial J}{\partial a^{L-1}} \odot\delta(z^{L-1})\odot(1-\delta(z^{L-1})) \tag{3} ∴∂J/∂zL−1=∂aL−1∂J⊙δ(zL−1)⊙(1−δ(zL−1))(3)
老实说,公式(3)的推导我也不知道是不是在画蛇添足……
先将第2节内容《向量对向量、矩阵求偏导》做个总结:
公式1,对向量的偏导数传递至向量的偏导数;两个向量关系为矩阵相乘。
公式2,对向量的偏导数传递至矩阵的偏导数;
公式3,对向量的偏导数传递至向量的偏导数;两个向量之间元素为一一对应的函数关系。
有了以上公式三联,就可以通过梯度下降实现全连接神经网络多分类的参数辨识。2.1节能够得到对 z L z^L zL的偏导数,然后通过公式(2)得到 L L L层的参数 V L V^L VL,结合公式(1)(3)即可往前推进一层至 L − 1 L-1 L−1层,依次类推(本文没有考虑偏置项 b b b,原理类似)。
3.Hadamard积求偏导
其实上述2.3节里面就有hadamard积的微分,这里还是单独陈列出来。
已知: z = x ⊙ y ; J = f ( z ) ; z=x \odot y;J=f(z); z=x⊙y;J=f(z);各个变量的维度: z [ m × 1 ] , x [ m × 1 ] , y [ m × 1 ] , J [ 1 × 1 ] z[m\times1],x[m\times1],y[m\times1],J[1\times1] z[m×1],x[m×1],y[m×1],J[1×1]
求: ∂ J / ∂ x ? \partial J/\partial x? ∂J/∂x?
(4) ∂ J / ∂ x = [ ∂ J ∂ x 1 ⋮ ∂ J ∂ x m ] = [ ∂ J ∂ z 1 ⋅ y 1 ⋮ ∂ J ∂ z m ⋅ y m ] = ∂ J ∂ z ⊙ y = y ⊙ ∂ J ∂ z \partial J/\partial x = \left[ \begin{matrix} \frac{\partial J}{\partial x_1}\ \\ \vdots \\ \frac{\partial J}{\partial x_m} \end{matrix} \right] =\left[ \begin{matrix} \frac{\partial J}{\partial z_1}\cdot y_1\ \\ \vdots \\ \frac{\partial J}{\partial z_m}\cdot y_m \end{matrix} \right]= \frac{\partial J}{\partial z}\odot y=y \odot \frac{\partial J}{\partial z}\tag{4} ∂J/∂x=⎣⎢⎡∂x1∂J ⋮∂xm∂J⎦⎥⎤=⎣⎢⎡∂z1∂J⋅y1 ⋮∂zm∂J⋅ym⎦⎥⎤=∂z∂J⊙y=y⊙∂z∂J(4)
可我还是喜欢上面画蛇添足的思路。
4.所有偏导推导思路
4.1当仅有华山一条道,且仅改变单个变量时,可以有如下表达式:
(I) Δ J = ( ∂ J / ∂ f ) T ⋅ Δ f = ( ∂ J / ∂ x ) T ⋅ Δ x \Delta J = (\partial J/ \partial f)^T\cdot \Delta f= (\partial J/ \partial x)^T\cdot \Delta x \tag{I} ΔJ=(∂J/∂f)T⋅Δf=(∂J/∂x)T⋅Δx(I)
其中维度: f [ m × 1 ] , x [ k × 1 ] , J [ 1 × 1 ] f[m\times1],x[k\times1],J[1\times1] f[m×1],x[k×1],J[1×1]
何为华山一条道?以全微分图为例,你会发现上式是不对的,但是如果去掉 g g g路径则没有问题。
何为仅改变单个变量?以 z L = V L ⋅ a L − 1 z^L = V^L\cdot \ a^{L-1} zL=VL⋅ aL−1为例,实则:
Δ z L = Δ V L ⋅ a L − 1 + V L ⋅ Δ a L − 1 \Delta z^L = \Delta V^L\cdot \ a^{L-1}+V^L\cdot \Delta a^{L-1} ΔzL=ΔVL⋅ aL−1+VL⋅ΔaL−1
但是如果仅考虑对单个变量 a L − 1 a^{L-1} aL−1求偏导(即认为别的变量为常量,如 V L V^L VL变量),是可以认为:
Δ J = ( ∂ J / ∂ z L ) T ⋅ Δ z L ⇒ ( ∂ J / ∂ a L − 1 ) T ⋅ Δ a L − 1 \Delta J =(\partial J/ \partial z^L)^T\cdot \Delta z^L \Rightarrow (\partial J/ \partial a^{L-1})^T\cdot \Delta a^{L-1} ΔJ=(∂J/∂zL)T⋅ΔzL⇒(∂J/∂aL−1)T⋅ΔaL−1
这也是为什么之前说" ⇒ \Rightarrow ⇒“符号直接当作等号”="来看。有了4.1则公式(1)的推导手到擒来。
在满足4.1的条件下,矩阵偏导数全微分表达式又是如何呢?
4.2矩阵偏导数全微分表达式
显然不是 Δ J = ( ∂ J / ∂ V ) T ⋅ Δ V \Delta J = (\partial J/ \partial V)^T\cdot \Delta V ΔJ=(∂J/∂V)T⋅ΔV,维度对不上,正确的表达式应该是:
(II) Δ J = T r ( ( ∂ J / ∂ V ) T ⋅ Δ V ) \Delta J = Tr((\partial J/ \partial V)^T\cdot \Delta V)\tag{II} ΔJ=Tr((∂J/∂V)T⋅ΔV)(II)
其中 T r ( ) Tr() Tr()为矩阵的迹,矩阵的迹有性质: T r ( A ⋅ B ) = T r ( B ⋅ A ) Tr(A\cdot B)=Tr(B\cdot A) Tr(A⋅B)=Tr(B⋅A)。公式(II)看起来很复杂实则就是两个表达式的对应元素相乘的和。
为此,再把公式(2)用4.2的知识推导一遍:
Δ J = ( ∂ J / ∂ z ) T ⋅ Δ z ( ∵ Δ z ⇒ Δ V ⋅ a ) = ( ∂ J / ∂ z ) T ⋅ ( Δ V ⋅ a ) ( ∵ 行 向 量 乘 以 列 向 量 等 于 列 向 量 乘 以 行 向 量 的 迹 ) = T r ( ( Δ V ⋅ a ) ⋅ ( ∂ J / ∂ z ) T ) = T r ( Δ V ⋅ a ⋅ ( ∂ J / ∂ z ) T ) = T r ( Δ V ⋅ ( ∂ J / ∂ z ⋅ a T ) T ) = T r ( ( ∂ J / ∂ z ⋅ a T ) T ⋅ Δ V ) \begin{aligned} \Delta J & =(\partial J/ \partial z)^T\cdot \Delta z \qquad (\because\Delta z \Rightarrow \Delta V \cdot a)\\ & = (\partial J/ \partial z)^T\cdot (\Delta V \cdot a)\\ & (\because 行向量乘以列向量等于列向量乘以行向量的迹)\\ & =Tr( (\Delta V \cdot a)\cdot (\partial J/ \partial z)^T) \\ & =Tr( \Delta V \cdot a\cdot (\partial J/ \partial z)^T) \\ & =Tr( \Delta V \cdot (\partial J/ \partial z\cdot a^T)^T)\\ & =Tr((\partial J/ \partial z\cdot a^T)^T \cdot \Delta V) \end{aligned} ΔJ=(∂J/∂z)T⋅Δz(∵Δz⇒ΔV⋅a)=(∂J/∂z)T⋅(ΔV⋅a)(∵行向量乘以列向量等于列向量乘以行向量的迹)=Tr((ΔV⋅a)⋅(∂J/∂z)T)=Tr(ΔV⋅a⋅(∂J/∂z)T)=Tr(ΔV⋅(∂J/∂z⋅aT)T)=Tr((∂J/∂z⋅aT)T⋅ΔV)
与公式(II)对比便知: ∂ J / ∂ V = ∂ J / ∂ z ⋅ a T \partial J/ \partial V = \partial J/ \partial z\cdot a^T ∂J/∂V=∂J/∂z⋅aT,可见利用4.1以及4.2的知识,可以相对较为轻松的完成公式(1)(2)的推导。
关于hadamard积的微分求导,也可以利用4.1,4.2的知识(再次重复公式(3))。
∂ J / ∂ z ⊙ Δ z = ∂ J / ∂ z ⊙ ( y ⊙ Δ x ) = ( ∂ J / ∂ z ⊙ y ) ⊙ Δ x \partial J/ \partial z\odot\Delta z = \partial J/ \partial z\odot (y\odot\Delta x)=(\partial J/ \partial z\odot y)\odot\Delta x ∂J/∂z⊙Δz=∂J/∂z⊙(y⊙Δx)=(∂J/∂z⊙y)⊙Δx
等式左右两个向量相等则其所有元素之和相等。
( ∂ J / ∂ z ) T ⋅ Δ z = ( ∂ J / ∂ z ⊙ y ) T ⋅ Δ x (\partial J/ \partial z)^T\cdot\Delta z =(\partial J/ \partial z\odot y)^T\cdot\Delta x (∂J/∂z)T⋅Δz=(∂J/∂z⊙y)T⋅Δx
∴ ∂ J / ∂ x = ∂ J / ∂ z ⊙ y \therefore \partial J/ \partial x = \partial J/ \partial z\odot y ∴∂J/∂x=∂J/∂z⊙y
实际上, a T ⋅ ( b ⊙ c ) = ( a ⊙ b ) T ⋅ c a^T\cdot(b\odot c) = (a\odot b)^T\cdot c aT⋅(b⊙c)=(a⊙b)T⋅c(凭直觉该式应该是没错的, 到底有没有这个性质我也没去查)
( ∂ J / ∂ z ) T ⋅ Δ z = ( ∂ J / ∂ z ) T ⋅ ( y ⊙ Δ x ) = ( ∂ J / ∂ z ⊙ y ) T ⋅ Δ x (\partial J/ \partial z)^T\cdot\Delta z = (\partial J/ \partial z)^T\cdot (y\odot\Delta x)=(\partial J/ \partial z\odot y)^T\cdot\Delta x (∂J/∂z)T⋅Δz=(∂J/∂z)T⋅(y⊙Δx)=(∂J/∂z⊙y)T⋅Δx
通过总结再回过来看偏微分的链式表达式,似乎能够闭卷了,可是如果纯粹靠推导难免有点容易出错。此时想起来高中数学的对联“奇变偶不变,符号看象限”。如果用这种型式描述偏微分就是:“型式由原式决定,左右转置看维度”。"型式由原式决定”:比如hadamard积的微分传递还是hadamard积的形式; z = V ⋅ a z=V\cdot a z=V⋅a微分传递后还是矩阵相乘的形式,“左右转置看维度”: ∂ J / ∂ a \partial J/\partial a ∂J/∂a与 ∂ J / ∂ z \partial J/\partial z ∂J/∂z定相差一个 V T V^T VT,,至于该转置应该左乘还是右乘 ∂ J / ∂ z \partial J/\partial z ∂J/∂z则看维度匹配。 ∂ J / ∂ a \partial J/\partial a ∂J/∂a维度为 [ k × 1 ] [k\times 1] [k×1], ∂ J / ∂ z \partial J/\partial z ∂J/∂z维度为 [ m × 1 ] [m\times 1] [m×1], V V V维度为 [ m × k ] [m\times k] [m×k],在维度匹配上, [ k × 1 ] = [ m × k ] T ⋅ [ m × 1 ] [k\times 1] = [m\times k]^T\cdot [m\times 1] [k×1]=[m×k]T⋅[m×1]。
∴ ∂ J / ∂ a = V T ⋅ ∂ J / ∂ z \therefore \partial J/\partial a=V^T\cdot\partial J/\partial z ∴∂J/∂a=VT⋅∂J/∂z
5.展望
这篇文章写完也算给自己对反向传播的一个总结吧,也是对自己的一个交代。还有卷积神经网络中对卷积内核的偏导数求导和层之间偏导链式没有写,也不晓得要哪天才会再来写,毕竟敲公式太遭罪了,还是一笔一纸的流畅。
真理总是越辩越明,如果觉得以上博文有任何问题欢迎留言。