机器学习与人脸识别1:如何理解机器学习
下面两个解释观点是从知乎摘取的:仅供参考
1. 人工智能与机器学习
一个常常让大众感到困惑的问题是:人工智能(AI),机器学习(ML),深度学习(DL),机器视觉(CV)以及自然语言处理(NLP)之间是什么关系?
从科普角度粗略地说,人工智能涵盖了其他所有概念[图1],而机器学习是人工智能的一个子方向,而深度学习又是机器学习中的一类方法。至于机器视觉与自然语言处理,它们是人工智能领域的两个具体应用,而且往往会用到深度学习。

图1 人工智能与相关概念的关系
2. 什么是机器学习?
越是简单的概念其实越难解释。比如有人提到机器学习问题事实上是一个「优化问题」,有人认为是机器学习是一个「编程概念」,也有人认为现阶段的机器学习是「统计推断」。
从不同的角度看,这些说法都有道理。我个人比较喜欢Tom+Mitchell对于「学习任务」的定义:
每个机器学习都可以被精准地定义为:1)+任务T;2)+训练过程E;3)+模型表现P。而学习过程则可以被拆解为「为了实现任务T」,我们「通过训练过程E」,逐步「提高表现P」的一个过程。
比如我们想要做一个模型来判断一张图片是猫还是狗(任务T)。为了提高模型的准确度(模型表现P),我们不断给模型提供图片让其学习猫与狗的区别(训练过程E)。在这个学习过程中,我们所得到的最终模型就是机器学习的产物,而训练过程就是学习过程。「机器学习」和「人类学习」是可以做类比的。套用刚才的公式:为了在高考中得到高分(任务T),小王每天做10套模拟题(训练E),并不断参加模考检测自己的错误率(评估P)。
但除了相似性以外,机器与人类在学习过程中也有很多差异:
- 机器可以标准化学习过程,并提取出了学习结果(模型),使得结果可迁移可复制。而人类的知识往往迁移成本更高,比如小王高考得到了高分,即使可以培训,但他没法把这个秘诀直接传授给小张。
- 机器可以从大量数据中进行学习,而人类则有更大的限制。随着硬件发展和数据量累计,机器学习模型可以从海量数据中学习,而人类的大脑并不能做到这一点。但换个角度看,人类最擅长的就是小样本学习并进行举一反三,比如看两张猫狗图片就能大致有个概念,而机器则往往需要海量数据才能做到。
- 机器更加擅长准确定义问题,而人类更擅长复杂且模糊问题。因为现阶段模型的限制,机器学习更擅长定义清晰的问题,比如是猫还是狗,是高还是矮,在局部问题上表现出众。而人类更擅长是做出复杂情况下判断,拥有更好的“全局观”。
- 值得一提的是对于同一任务,机器和人类的解决思路不同。比如分辨猫与狗,人类可能会依靠舌头的位置,而机器从数据中可能学到的显著差别是瞳距鼻形等(只是假设)。
机器与人类的学习过程中有很多差别,上面只是其中的一小部分。比较显著的差别是现阶段的机器更适合简单问题、大量数据的高效且准确的预测,而人类更适合复杂状况下面临有限数据做出决策。在可预见的未来,我们依然还是需要两条腿走路,让机器和人类做各自擅长的事情,不能单纯的说谁更好。其实结合人类知识与机器的学习能力是非常自然的想法,比如现在比较流行的主动学习(active+learning),比如让机器学会阅读从人类知识库中收集知识,比如人机互动(HCI)与机器学习的交叉研究等。
3. 机器学习任务的复杂度
前面提到了机器学习的最终产物往往是一个「模型」。因此从另一个角度看,机器学习其实是在「寻找一个映射函数f(.),使得输入x经过f(x)后得到期望的输出y,也就是y=f(x) 」。继续拿猫狗分类为例,我们希望输入x1(猫与狗的图片)之后得到正确的输出y1(它是猫还是狗),此时学习的过程就是寻找正确的判别器f(.)的过程。
如果我们预先假设f(.)应该符合 fx=ax2+b 形式,那么学习过程就是确定a与b取值的问题。这也是为什么机器学习也可以被理解为优化问题或者参数寻优的过程。在求解最优参数时,往往没有闭式解(closed-form+solution),即很少会得到a=x+x3-2, b= -0.1�� 这种明确的答案。因此需要用各种优化算法求解,且大部分优化问题是无法得到最佳答案的,这也是为什么我们很少会得到「完美的机器学习」模型。
通过上面这个例子,我们可以看到机器学习成功与否取决于多个因素:
·任务T的定义是否明确,有多复杂。学习难度随着任务复杂度上升,比如分辨图片是{猫,够,人}就比{猫,狗}更加复杂。
·训练E的难度,比如有多少可用数据(一般而言数据越多越好),训练开销有多大,硬件是否能够支持。随着任务复杂度上升,我们对于正确模型的假设就越复杂,所需要搜索和寻优的空间就越大。
·评估标准P是否适合,如果选择了不适当的评估可能南辕北辙。比如分辨猫狗时,评估是否能正确识别图片中动物的数量是错误的。随着任务的复杂度上升,定义评估标准也会更加复杂。
不难看出,机器学习中的每个环节都互有关联。而且在整个过程中,我们不可避免地会引入各种各样的人为先验(代入我们的假设)。举个例子,我们往往基于经验提出对模型的猜想,比如猜测正确模型是一个二次函数,形式为fx=ax2+b,但真实的情况可能是fx=ax2+bx+c,那不可避免的我们就引入了人为的偏差(bias),这样再怎样训练都无法学习到完美模型。同理,即使我们对于模型有正确的假设,但如果数据量不够,也很难寻找到最优参数。另一个常常被人挂在嘴边的机器学习问题是过拟合,也就是说在学习过程中模型“死记硬背”,却没有发现数据中真正核心的部分只记住了表象。就像小王背会了很多往年高考题的答案,毫厘不差,但上了真正的考场依然低分,因为他并没有学会解题而只是背住了训练题的答案。
从理论角度看,我们有PAC学习理论(Probably+Approximately+Correct)来给定某个学习任务的过拟合误差的边界(边界)。PAC中给出的边界取决于:1)+训练数据的数量;(2)+模型假设空间的复杂度等。而在实际场景中,衡量一个学习任务的复杂度却不容易,比如训练数据并非是从真实数据分布中随机产生。即便如此,我们依然可以大致得到这个结论:简单且正确的模型假设+大量的训练数据=优秀的机器学习模型,这为我们应用机器学习方法打下了一个基础。
4. 如何应用机器学习?
如何让机器学习落地到各行各业是一个非常有价值但同时充满挑战的任务。除了上文提到的理论基础外,我们还需要选择合适的任务来实践,并不是任何问题都适合应用机器学习。从我为不同行业客户提供咨询的经验来看:
1.首先要解决的是认知偏差。我们首先要理解「机器学习不是万灵药,不是魔法,更不是诈骗」,它不会一期之间让所有人失业,也不只是噱头。所以当应用机器学习技术时,给它时间,要有耐心,不要认为有过高期待也不必不屑一顾。
2. 承接上一点,应用机器学习的过程应该是迭代式的。我们一般推荐「半自动系统」或者「混合系统」,即结合已有的「人类经验」与「机器学习模型」,而不是一步到位。举个例子,我们现在想用机器学习方法优化信用卡反诈骗系统。那么比较好的实践经验是同时用现有的规则系统与建立的机器学习系统,并从中找到平衡点。如果二者输出结果相同,那么接受其判断,否则人为验证,并重新训练模型。随着训练数据越来越多且准确,这套系统也会越来越智能,可以逐步淘汰现有的系统。
3. 有了合理预期的前提下,要选择适当的方向来应用机器学习模型。一般情况下,我们建议从「问题定义明确,数据储量充沛,能提供关键价值」的方向入手,每次尝试解决一个重要小问题。比如预测一个公司的营收就比预测它的股价发展要容易一些,因为后者还会受到更多复杂因素的影响。选择对的问题比努力有时候还要更重要。
4. 利用现有工具,避免重复开发。市面上已经有了很多针对各种任务的工具库和成功的解决方案。比如通用机器学习工具库Sklearn,更偏向深度学习的TensorFlow和PyTorch,分布式机器学习PySpark,图形式(无需编程)的平台ML+Studio,各种针对视觉、自然语言的API服务。使用这些已有的成熟的工具,很多时候可以快速判断是否值得投入使用机器学习。
5. 总结
总结来看,机器学习可以被看做是一种与人类思维有异曲同工的学习方法,各有擅长之处。进入二十一世纪后,随着硬件与数据量的发展,高精度的机器学习模型正在变为可能,特别是在机器视觉和自然语言领域已经有了很多突破。即使如此,我们也还是要认识到它不是个新概念,也不会让每个人都失业。从实际角度出发,机器学习模型的结果跟问题的复杂度、可用数据量,以及正确的评估方法都有很大的关系。从应用角度出发,传统企业应该从「问题定义明确,数据处理大,利润率高的问题」出发,引入混合模型,即同时使用人为的经验与机器学习进行预测。从降低成本的角度出发,要善用已有的工具与成熟的模型,快速迭代。
如果你不是一个人工智能专家,不要担心,我不会提及线性回归和k-均值聚类。
数据分析和机器学习
数据分析和机器学习
如果你认为大数据仅仅是关于SQL语句查询和海量的数据的话,那么别人也会理解你的,但是大数据真正的目的是通过对数据的推断,从数据中获取价值、从数据中发现有用的东西。例如,“如果我降低5%的价格,我将增加10%的销售量。”
数据分析是重要的技术,包括如下方面:
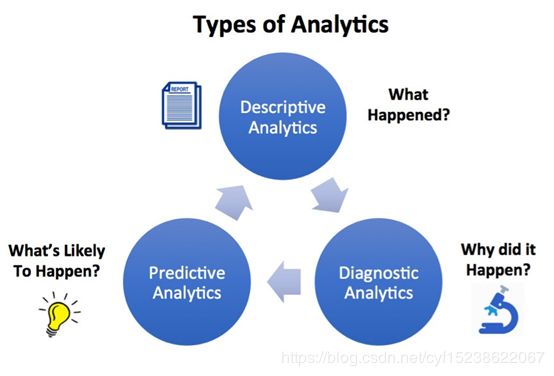
- 描述性分析:确定所发生的事情。这通常涉及到描述发生了什么现象的报告。例如,用这个月的销售额与去年同期进行比较的结果。
- 特征性分析:解释现象发生的原因,这通常涉及使用带有OLAP技术的控制台用以分析和研究数据,根据数据挖掘技术来找到数据之间的相关性。
- 预测性分析:评估可能发生的事情的概率。这可能是预测性分析被用来根据你的工作性质、个人兴趣爱好,认为你是一个潜在的读者,以便能够链接到其他的人。
机器学习适合于预测性分析。
什么是机器学习
机器学习是人工智能的一个子集,即用机器去学习以前的经验。与传统的编程不同,开发人员需要预测每一个潜在的条件进行编程,一个机器学习的解决方案可以有效地基于数据来适应输出的结果。
一个机器学习的算法并没有真正地编写代码,但它建立了一个关于真实世界的计算机模型,然后通过数据训练模型。
机器学习如何工作?
垃圾邮件过滤是一个很好的例子,它利用机器学习技术来学习如何从数百万封邮件中识别垃圾邮件,其中就用到了统计学技术。
例如,如果每100个电子邮件中的85个,其中包括“便宜”和“伟哥”这两个词的邮件被认为是垃圾邮件,我们可以说有85%的概率,确定它是垃圾邮件。并通过其它几个指标(例如,从来没给你发送过邮件的人)结合起来,利用数十亿个电子邮件进行算法测试,随着训练次数不断增加来提升准确率。
事实上,谷歌表示它现在已经可以拦截99.99%左右的垃圾邮件。
机器学习实例
一般包括以下几个方面:
- 目标影响:主要针对Google和Facebook的目标广告,基于个人兴趣爱好,并通过Netflix推荐电影,还通过亚马逊推荐购物;
- 信用评分:银行使用收入数据,从你的居住地、你的年龄和婚姻状况来预测你是否会拖欠贷款;
- 信用卡欺诈检测:用于根据你之前一些可能的消费习惯,在线禁止具有欺诈行为的信用卡或借记卡的使用;
- 购物篮分析:根据数以百万个类似顾客的消费习惯,用来预测你更可能使用哪些特殊优惠政策;
在一个有争议的案例:美国零售商对使用了25种不同的健康和化妆品产品的顾客的购物篮进行分析,来成功地预测妇女怀孕,包括非常准确的预产期。然而却事与愿违,当一个年轻女孩的父亲抱怨说,在女儿被怀孕相关的特殊优惠轰炸后,目的就变成了鼓励未成年少女怀孕。
你需要什么
事实上,你是在寻找数据中的关联性,但你需要一些领域的专业知识来验证结果。计算机可以找到一个模式,但是只有专家才能验证它是否具有关联性。
总之,以下是你所需要的:
- 目标.你正在试图解决的问题。例如,信用卡被盗了吗?股票价格会上涨还是下跌?用户近期最喜欢哪部电影?
- 大量数据. 例如,为了准确预测房屋的价格,你需要详细列出的历史价格。
- 专家.你需要一个知道正确答案的领域专家来验证所产生的结果,并确认什么时候模型足够精确。
- 模式.你在寻找数据中的模式。如果没有模式,你可能会有错误的或者不完整的数据。
机器学习的类型
预测性分析试图基于历史数据来预测未来的结果,最常用的方法被称为监督学习。
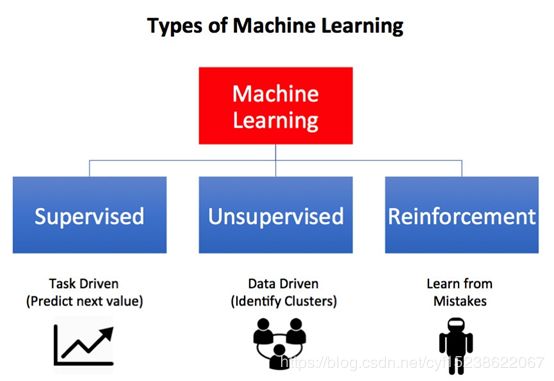
机器学习的类型有:
- 监督学习:当我们需要从过去的数据中知道正确答案的时候,但是还需要预测未来的结果。例如,利用过去的房价来预测当前和未来的价格。有效地使用基于试错的统计改进过程,机器依靠对监督者提供的一组值的测试结果来逐步提高准确性。
- 无监督学习:这里没有明确的正确答案,但我们想从数据中有新的发现。最常用于对数据进行分类或分组,例如,在Spotify上对音乐分类,来帮助推荐你可能想听的歌曲或是专辑。然后,他们将听众分类,看他们是否更可能愿意听Radiohead或Justin Bieber。
- 强化学习:不需要一个领域专家,但需要不断地向预定目标前进。这是一种经常部署神经网络的技术,例如, AphaGo在DeepMind中跟自己打了一百万场比赛,最终成为了世界冠军。
机器学习过程
不同于未来通过机器学习下象棋的场景,目前大多数机器学习是相当麻烦的,在下面的图表中进行了说明:
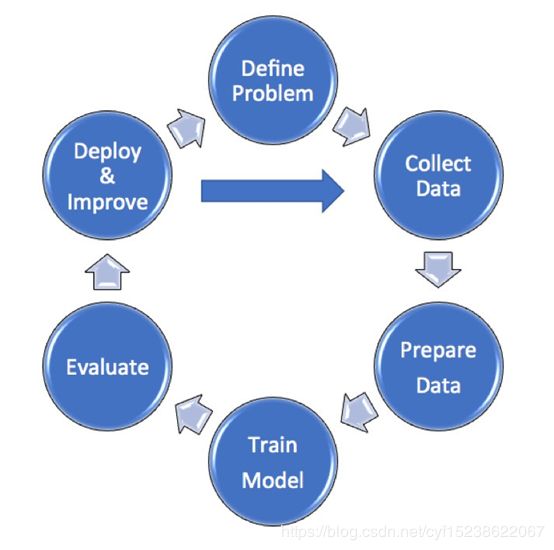
在未来很可能机器学习将会被应用到帮助加快过程,特别是在数据收集和清洗领域,但主要步骤仍然存在以下方面:
- 定义问题:正如我在另一篇文章中所指出的那样,机器学习总是从一个明确的问题和目标开始;
- 收集数据:适合的数据的数量和种类越多,机器学习模型就会变得越精确。这些数据可以来自电子表格、文本文件和数据库,除了商业上可用的数据源之外;
- 准备数据:这包括数据的清理和解析。删除或纠正异常值(失控的错误值);这经常占用总的时间和工作量的60%以上,然后将数据分成两个不同的部分,即训练数据和测试数据;
- 训练模型:针对一组训练数据—用于识别数据中的模式或相关性,或者用于做预测,同时使用重复的测试和误差改进方法来逐步地提高模型的精度;
- 评估模型:通过比较结果与测试数据集的准确度来评估模型。重要的是不要对用于训练系统的数据进行模型评估,以确保无偏差的和独立的测试;
- 部署和改进:这可以涉及到尝试完全不同的算法或者收集更多种类或更大数量的数据。例如,你可以通过使用房屋所有者提供的数据来预估今后的房屋升值空间,从而提高房价预测的准确度;
综上所述,大多数机器学习过程实际上是循环的和连续的,因为更多的数据被添加或者情况会有所变化,因为世界从来不会静止不动,并且总是有改进和提高的空间。
总结
下图说明了机器学习系统所使用的关键策略:
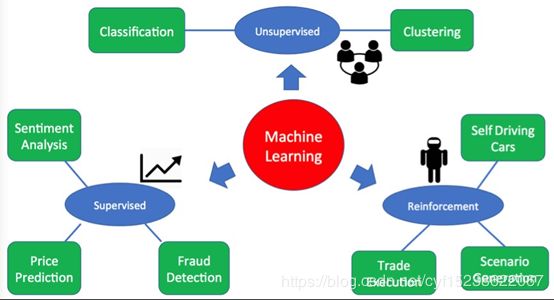
总之,任何机器学习系统的关键部分就是数据。考虑到额外的算法、巧妙的编程和大量的更精确的数据的选择,大数据每次都是胜利者。