CPU 集群 / GPU 集群/ 异构集群 /分布式
—–集群与分布式区别
—–集群
—–集群分类
—–CPU 集群
—–异构集群
—–异构集群简单搭建—
—–– 天河一号–
—–– 编程语言–
ref 1国家超算天津中心 天河一号&三个计算机集群
http://www.nscc-tj.gov.cn/resources/resources_1.asp
天河一号 超算:峰值速度提升为4700TFlops,持续速度提升为2566TFlops(LINPACK实测值)
—–集群与分布式区别——
分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。
ref http://blog.csdn.net/zhang0311/article/details/49123847
集群是个物理形态,分布式是个工作方式。只要是一堆机器,就可以叫集群,他们是不是一起协作着干活,这个谁也不知道;一个程序或系统,只要运行在不同的机器上,就可以叫分布式,嗯,C/S架构也可以叫分布式。
集群一般是物理集中、统一管理的,而分布式系统则不强调这一点。所以,集群可能运行着一个或多个分布式系统,也可能根本没有运行分布式系统;分布式系统可能运行在一个集群上,也可能运行在不属于一个集群的多台(2台也算多台)机器上。
简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
例如:
如果一个任务由10个子任务组成,每个子任务单独执行需1小时,则在一台服务器上执行改任务需10小时。
采用分布式方案,提供10台服务器,每台服务器只负责处理一个子任务,不考虑子任务间的依赖关系,执行完这个任务只需一个小时。(这种工作模式的一个典型代表就是Hadoop的Map/Reduce分布式计算模型)
而采用集群方案,同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,10小后,10个任务同时完成,这样,整身来看,还是1小时内完成一个任务!
——集群——–
1.两大特性:
可扩展性
高可用性
2.两大能力
负载均衡
错误恢复
3.两大技术
集群地址
内部通信
—-集群分类—
linux集群三类:
Linux High Availability 高可用集群
(普通两节点双机热备,多节点HA集群,RAC, shared, share-nothing集群等)
Linux Load Balance 负载均衡集群
(LVS等….)
Linux High Performance Computing 高性能科学计算集群
(Beowulf 类集群….)
分布式存储
其他类linux集群
(如Openmosix, rendering farm 等..)
1. 高可用集群(High Availability Cluster)
常见的就是2个节点做成的HA集群,有很多通俗的不科学的名称,比如”双机热备”, “双机互备”, “双机”.
高可用集群解决的是保障用户的应用程序持续对外提供服务的能力。 (请注意高可用集群既不是用来保护业务数据的,保护的是用户的业务程序对外不间断提供服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度)。
- 负载均衡集群(Load Balance Cluster)
负载均衡系统:集群中所有的节点都处于活动状态,它们分摊系统的工作负载。一般Web服务器集群、数据库集群和应用服务器集群都属于这种类型。
负载均衡集群一般用于相应网络请求的网页服务器,数据库服务器。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器上。从检查其他服务器状态这一点上看,负载均衡和容错集群很接近,不同之处是数量上更多。
- 科学计算集群(High Performance Computing Cluster)
高性能计算(High Perfermance Computing)集群,简称HPC集群。这类集群致力于提供单个计算机所不能提供的强大的计算能力。
高性能计算分类 :高吞吐计算、分布计算
高吞吐计算(High-throughput Computing)
有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。象在家搜寻外星人( SETI@HOME – Search for Extraterrestrial Intelligence at Home )就是这一类型应用。这一项目是利用Internet上的闲置的计算资源来搜寻外星人。SETI项目的服务器将一组数据和数据模式发给Internet上 参加SETI的计算节点,计算节点在给定的数据上用给定的模式进行搜索,然后将搜索的结果发给服务器。服务器负责将从各个计算节点返回的数据汇集成完整的 数据。因为这种类型应用的一个共同特征是在海量数据上搜索某些模式,所以把这类计算称为高吞吐计算。所谓的Internet计算都属于这一类。按照 Flynn的分类,高吞吐计算属于SIMD(Single Instruction/Multiple Data)的范畴。
分布计算(Distributed Computing)
另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。按照Flynn的分类,分布式的高性能计算属于MIMD(Multiple Instruction/Multiple Data)的范畴。
—CPU 集群——
并行:MPI
—-异构集群——
天河一号 http://www.nscc-tj.gov.cn/cloudcenter/bigdata.asp
-MPI+OpenMP+CUDA异构编程模型
-Scalaca toolset、TAU性能分析软件
-ParaView、VTK、IDL等大数据可视化软件
- MPI+CUDA
ref 《基于CPU/GPU 集群的编程研究》(深圳 星云 )
MPI负责进程间数据传输,CUDA 负责GPU计算程序设计,MPI和CUDA都是基于C语言,所以它们可以兼容的写到一个c文件里
OpenCL (Open Computing Language) 是业界第一个跨平台的异构编程框架
openmp+MPI
纯MPI性能比纯openmp和MPI+openmp混合都要好很多,只是内存占用会大一些。原因是集群普遍是NUMA节点,节点内的data locality对于openmp是一个大问题。而MPI编程模型天生强制比较好的data locality。当然openmp结合affinity设置也能写出来locality好的程序,但是普遍的说法是,如果你想用openmp写出MPI的性
能,那你的openmp代码肯定长得像MPI代码。具体做法就是把mpi的通信,用openmp数据复制替代,还不如直接用MPI得了,至少可以扩展到分布式。还有一个做法就是每个numa单元一个MPI进程,numa单元内部用openmp。这样需要比较复杂的cpu binding设置,但是是可以部分解决locality问题的
openmp+MPI混合编程在MPI基础上加大了复杂度,采用它的目的,是减少内存占用,而非提高性能。即使是在单个节点,纯粹的共享内存系统,MPI程序在性能上也不输openmp,大多数时候甚至更好这些异构计算资源和基于它们的不同层次的并行计算能力,给并行程序设计带来困难
———-异构集群简单搭建——–
ref https://www.zhihu.com/question/26562656/answer/33398115
集群分为四个部分:计算节点、存储节点、管理节点、集群辅件。计算节点就是负责运算的节点,就GPU集群来讲,就是使用CPU和GPU卡(或PHI卡)计算,一般只安装一块硬盘作为系统盘,计算节点通过Infiniband网络(以下简称IB网络)连接存储节点来完成运算数据的读取和存储。目前(2014年)IB网络的主流速度是40Gb/s,换算成大家日常中说的“速度”就是8GB/s,也就是理论上一个8GB U盘所装满的数据一秒钟就能传输完毕。存储节点,顾名思义,就是存数据的,一堆硬盘。管理节点,顾名思义,就是负责管理的,一般是一台终端机。集群辅件,是包括IB网络(IB交换机、线材等)、千兆以太网络(千兆以太网交换机、线材等)、Rack(机柜)、PDU(就是高级点的插座)等一些东西
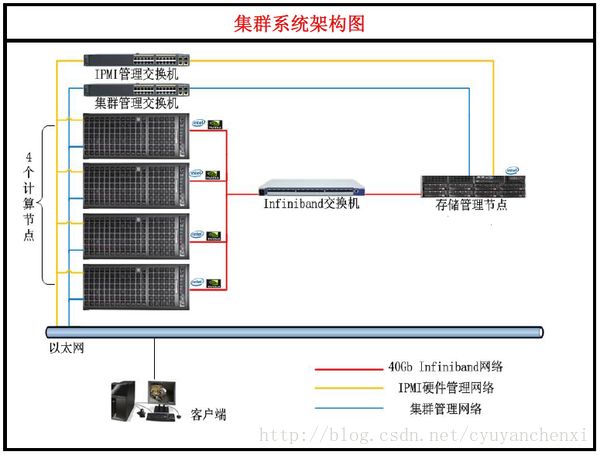
ref http://blog.csdn.net/liujiandu101/article/details/51278065
主流的混合集群编程模型是MPI+CUDA,MPI负责进程间数据传输,CUDA 负责GPU计算程序设计,MPI和CUDA都是基于C语言,所以它们可以兼容的写到一个c文件里。
——–天河一号————–
“天河一号”采用CPU和GPU相结合的异构融合计算体系结构,硬件系统主要由计算处理系统、互连通信系统、输入输出系统、监控诊断系统与基础架构系统组成,软件系统主要由操作系统、编译系统、并行程序开发环境与科学计算可视化系统组成。总体技术指标如下:
(1)峰值速度4700TFlops,持续速度2566TFlops(LINPACK实测值),内存总容量262TB,存储总容量2PB。
(2)计算处理系统:包含7168个计算结点和1024个服务结点。每个计算结点包含2路英特尔CPU和一路英伟达GPU,每个服务结点包含2路飞腾CPU。全系统共计23552个微处理器,其中英特尔至强X5670 CPU(2.93GHz、6核)14336个、飞腾-1000 CPU(1.0GHz、8核)2048个、英伟达M2050 GPU(1.15GHz、14核/448个CUDA核)7168个,CPU核共计102400个,GPU核共计100352个。
(3)互连通信系统:采用自主设计的高阶路由芯片NRC和高速网络接口芯片NIC,实现光电混合的胖树结构高阶路由网络,链路双向带宽160Gbps,延迟1.57us。
(4)输入输出系统:采用Lustre全局分布共享并行I/O结构,6个元数据管理结点,128个对象存储结点,总容量2PB。
(5)监控诊断系统:采用分布式集中管理结构,实现系统实时安全监测、控制和调试诊断。
(6)基础架构系统:采用高密度双面对插组装结构,冷冻水空调密闭风冷散热。环境温度10℃~35℃,湿度10%~90%。
(7)操作系统:64位麒麟Linux,面向高性能并行计算优化,支持能耗管理、高性能虚拟计算域等,可广泛支持第三方应用软件。
(8)编译系统:支持C、C++、Fortran77/90/95、Java语言,支持OpenMP、MPI并行编程,支持异构协同编程框架,高效发挥CPU和GPU的协同计算能力
——编程语言———
1)如果你只需要在Windows平台上进行异构编程,并且看重易编程性的话,C++ AMP无疑是最好的选择。依托于Visual Studio这个强有力的开发工具,再加上基于C++这一更高层抽象带来的先天优势,C++ AMP将为Windows开发者进行异构编程提供良好的支持。
2)如果你只需要在Nvidia的GPU卡上进行异构编程,并且非常看重性能的话,CUDA应该是第一选择:在Nvidia的强力支持下,CUDA在Nvidia硬件上的性能一直保持领先,许多学术研究表明OpenCL与CUDA的性能相差不大,在一部分应用中CUDA的性能稍微好于OpenCL。同时CUDA的开发环境也非常成熟,拥有众多扩展函数库支持。
3)如果你更注重不同平台间的可移植性,OpenCL可能是目前最好的选择。作为第一个异构计算的开放标准,OpenCL已经得到了包括Intel,AMD,Nvidia,IBM,Oracle,ARM,Apple,Redhat等众多软硬件厂商的大力支持。当然,C++ AMP本身也是一个开放的标准,只是目前只有微软自己做了实现,将来C++ AMP的跨平台支持能做到什么程度还是一个未知数。
其实从编程语言的发展来看,易编程性往往比性能更加重要。从Java和.Net的流行,到脚本语言的崛起,编程效率无疑是最重要的指标。更不用说开发者往往可以通过更换下一代GPU硬件来获得更好的性能。从这点来看,C++ AMP通过降低异构编程的编程难度,实际上也是推进了异构编程的普及。下面我们需要看的就是C++ AMP是否能成为真正的业界标准,而不仅仅局限于微软自己的平台,微软这次开放C++ AMP标准的行为也正是为了推广C++ AMP在业界的普及。