kettle5.3批量插入impala
1.pentaho-big-data-plugin大数据插件
kettle5.3对应的pentaho-big-data-plugin-5.3(大数据插件)里面扩展支持了很多数据库连接,其中就包含了hive,hive2和impala,源码中分别对应以下这几个类:
HiveDatabaseMeta
Hive2DatabaseMeta
ImpalaDatabaseMeta它们都是通过hive-jdbc去连接的,其实cloudera公司也出了个impala-jdbc。先编译pentaho-big-data-plugin-5.3得到运行包,在5.3版本还是保留着ant+ivy进行编译打包,但是依赖包所在的repo地址已经不再是下载得到的源码中ivysetting.xml中的地址:
"pentaho.resolve.repo" value="http://ivy-nexus.pentaho.org/content/groups/omni" override="false" />
改为:
"pentaho.resolve.repo" value="https://nexus.pentaho.org/content/groups/omni" override="false" /> 从dist下将编译好的压缩包解压放到{kettle}/plugins目录下,pentaho-big-data-plugin解压后目录:

kettke启动后会扫描plugins下所有插件根目录以及lib目录下的所有jar包,hadoop-configurations目录放置着不同hadoop版本相关依赖和配置文件:

至于自己需要使用什么版本的hadoop则在pentaho-big-data-plugin/plugin.properties进行配置:
active.hadoop.configuration=cdh53 #对应上图的目录名称,这里自己使用cdh5.3在编译好pentaho-big-data-plugin后,默认有cdh53、hadoop-20、hdp22、mapr401几个不同的版本,这些不同版本的hadoop都是可以通过编译pentaho-hadoop-shims这个项目来获得,可以看到kettle5.3对应的pentaho-hadoop-shims-5.3远不止这几个hadoop版本,至于想得到更高版本的hadoop可以尝试找对应的pentaho-hadoop-shims来编译,将编译好的shim复制到hadoop-configurations目录然后更改active.hadoop.configuration即可。
上面说到连接impala时是使用hive-jdbc驱动的,但相关的jar是在cdh5.3/lib目录下面的,kettle本身不会加载到这些hadoop版本下的jar包,而且就算大数据插件也是由不同的ClassLoader加载的,忘记了下载kettle的时候有没包含了pentaho-hadoop-hive-jdbc-shim-5.3.jar,反正编译源码得到的kettle是没这个jar,就是通过它去加载了cdh53下的包,需要把它放{kettle}/lib目录下,这个包在编译pentaho-hadoop-shims的子项目hive-jdbc这个项目时会生成,它实现了HiveDirver以及ImpalaDriver并通过大量的反射最终才加载到cdh53下的hive-jdbc驱动。
配置完这些再启动spoon,可以看到数据库连接界面已经多了很多种连接类型:
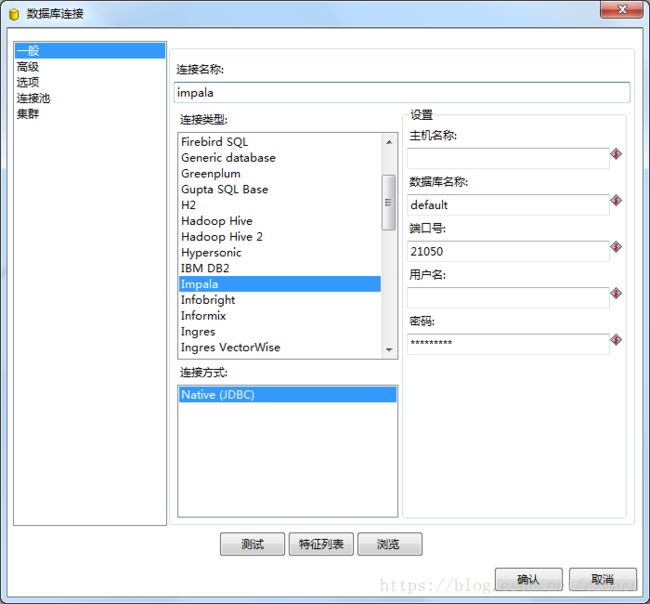
2.HiveJdbc不支持批量插入/更新
既然kettle的大数据插件已经支持了impala这些数据库连接类型,于是尝试进行插入测试,随意创建一个转换,从一个表读取数据然后插入到impala的表中,如下:
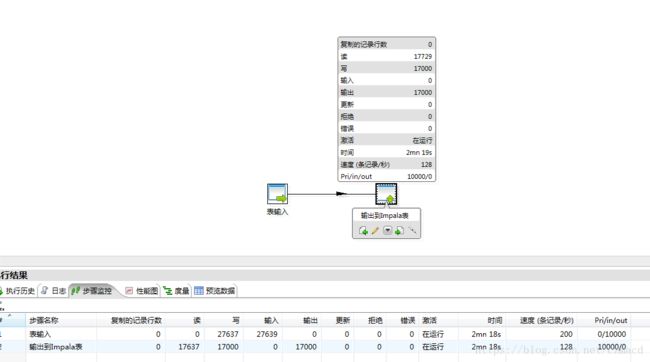
通过监控见到插入到impala的速度居然只有100+每秒,由于数据并不是直接存在hdfs,而是存在kudu,对于kudu表是支持行级的随机读写,但明显不是预期的效果。通过调试kettle的源码发现,在kettle中表输出步骤的实现中使用的是PreparedStatement.executeBatch()进行批量插入的,但是在hive-jdbc中是不支持批量更新的:
//HiveDatabaseMetaData
public boolean supportsBatchUpdates() throws SQLException {
return false;
}
//HiveStatement
public int[] executeBatch() throws SQLException{
throw new SQLException("Method not supported");
}
而在executeBatch()之前会先判断j是否支持批量更新,如果不支持就会一条条提交了,根据官方文档提到,insert语句并不适合用在基于hdfs的表:

所以只能是自己写逻辑了,通过insert into table(x,x,x) values(x,x,x),(x,x,x)…..这种方式进行批量更新,参考表输出(TableOutput),自己实现一下步骤插件。
扯到另一个,hivejdbc中HiveResultSetMetaData.isSigned()其实也是不支持的,但在org.pentaho.di.core.row.value.ValueMetaBase中用到了很多次却没异常,是因为被pentaho-hadoop-shim-xx.jar中的DriverProxyInvocationChain代理了方法并实现了逻辑,类似的还有getMetaData()等其它方法。
自定义插件
参考kettle本身的”表输出”步骤进行修改逻辑,把多条记录拼成一条insert sql执行,对kettle插件原理及开发不太熟悉的可以参考一下https://blog.csdn.net/d6619309/article/details/50020977。
为插件创建一个项目名为kettle-impala-plugin的项目,项目结构如下:
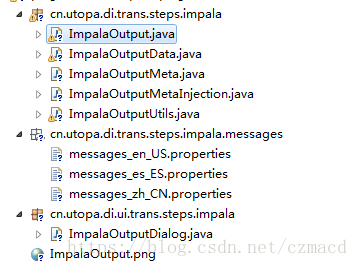
从表输出源码目录中复制文件并命名成以上文件,表输出这个步骤插件是在kettle启动时从自身xml读取到配置信息并加载的,如果以自定义插件还是建议通过注解@Step来声明自己开发的插件,例如:

主要是对ImpalaOutput类进行修改,重点在writeToTable方法,直接贴出修改后的代码:
if (r == null) { // Stop: last line or error encountered
if (log.isDetailed()) {
logDetailed("Last line inserted: stop");
}
return null;
}
Statement insertStatement = null;
Object[] insertRowData;
Object[] outputRowData = r;
String tableName = null;
boolean sendToErrorRow = false;
String errorMessage = null;
boolean rowIsSafe = false;
if (meta.isTableNameInField()) {
// Cache the position of the table name field
if (data.indexOfTableNameField < 0) {
String realTablename = environmentSubstitute(meta.getTableNameField());
data.indexOfTableNameField = rowMeta.indexOfValue(realTablename);
if (data.indexOfTableNameField < 0) {
String message = "Unable to find table name field [" + realTablename + "] in input row";
logError(message);
throw new KettleStepException(message);
}
if (!meta.isTableNameInTable() && !meta.specifyFields()) {
data.insertRowMeta.removeValueMeta(data.indexOfTableNameField);
}
}
tableName = rowMeta.getString(r, data.indexOfTableNameField);
if (!meta.isTableNameInTable() && !meta.specifyFields()) {
// If the name of the table should not be inserted itself,
// remove the table name
// from the input row data as well. This forcibly creates a copy
// of r
//
insertRowData = RowDataUtil.removeItem(rowMeta.cloneRow(r), data.indexOfTableNameField);
} else {
insertRowData = r;
}
} else if (meta.isPartitioningEnabled() && (meta.isPartitioningDaily() || meta.isPartitioningMonthly())
&& (meta.getPartitioningField() != null && meta.getPartitioningField().length() > 0)) {
// Initialize some stuff!
if (data.indexOfPartitioningField < 0) {
data.indexOfPartitioningField = rowMeta
.indexOfValue(environmentSubstitute(meta.getPartitioningField()));
if (data.indexOfPartitioningField < 0) {
throw new KettleStepException(
"Unable to find field [" + meta.getPartitioningField() + "] in the input row!");
}
if (meta.isPartitioningDaily()) {
data.dateFormater = new SimpleDateFormat("yyyyMMdd");
} else {
data.dateFormater = new SimpleDateFormat("yyyyMM");
}
}
ValueMetaInterface partitioningValue = rowMeta.getValueMeta(data.indexOfPartitioningField);
if (!partitioningValue.isDate() || r[data.indexOfPartitioningField] == null) {
throw new KettleStepException(
"Sorry, the partitioning field needs to contain a data value and can't be empty!");
}
Object partitioningValueData = rowMeta.getDate(r, data.indexOfPartitioningField);
tableName = environmentSubstitute(meta.getTableName()) + "_"
+ data.dateFormater.format((Date) partitioningValueData);
insertRowData = r;
} else {
tableName = data.tableName;
insertRowData = r;
}
if (meta.specifyFields()) {
//
// The values to insert are those in the fields sections
//
insertRowData = new Object[data.valuenrs.length];
for (int idx = 0; idx < data.valuenrs.length; idx++) {
insertRowData[idx] = r[data.valuenrs[idx]];
}
}
if (Const.isEmpty(tableName)) {
throw new KettleStepException("The tablename is not defined (empty)");
}
insertStatement = data.statements.get(tableName);
if (insertStatement == null) {
// String sql =data.db.getInsertStatement( environmentSubstitute(
// meta.getSchemaName() ), tableName, data.insertRowMeta );
String sql = ImpalaOutputUtils.getInsertStatement(data.db, environmentSubstitute(meta.getSchemaName()),
tableName, data.insertRowMeta);
data.sqls.put(tableName, sql);
if (log.isDetailed()) {
logDetailed("impala insert into table sql: " + sql);
}
insertStatement = ImpalaOutputUtils.createStatement(data.db);
data.statements.put(tableName, insertStatement);
}
try {
// For PG & GP, we add a savepoint before the row.
// Then revert to the savepoint afterwards... (not a transaction, so
// hopefully still fast)
//
if (data.useSafePoints) {
data.savepoint = data.db.setSavepoint();
}
data.batchBuffer.add(r); // save row
if (log.isRowLevel()) {
logRowlevel("cache row before insert: " + data.insertRowMeta.getString(insertRowData));
}
// Get a commit counter per prepared statement to keep track of
// separate tables, etc.
Integer commitCounter = data.commitCounterMap.get(tableName);
if (commitCounter == null) {
commitCounter = Integer.valueOf(1);
} else {
commitCounter++;
}
data.commitCounterMap.put(tableName, Integer.valueOf(commitCounter.intValue()));
// Release the savepoint if needed
//
if (data.useSafePoints) {
if (data.releaseSavepoint) {
data.db.releaseSavepoint(data.savepoint);
}
}
/***
* 提交触发点取决于“提交记录数量”,"使用批量插入"的可选项将不再生效
*/
if ((data.commitSize > 0) && ((commitCounter % data.commitSize) == 0)) {
try {
String batchSql = ImpalaOutputUtils.getBatchSql(data, tableName);
insertStatement.execute(batchSql);
data.db.commit();
} catch (SQLException ex) {
throw new KettleDatabaseException("Error updating batch", ex);
} catch (Exception ex) {
throw new KettleDatabaseException("Unexpected error inserting row", ex);
}
// Clear the batch/commit counter...
//
data.commitCounterMap.put(tableName, Integer.valueOf(0));
rowIsSafe = true;
} else {
rowIsSafe = false;
}
} catch (KettleDatabaseException dbe) {
if (getStepMeta().isDoingErrorHandling()) {
if (log.isRowLevel()) {
logRowlevel("Written row to error handling : " + getInputRowMeta().getString(r));
}
if (data.useSafePoints) {
data.db.rollback(data.savepoint);
if (data.releaseSavepoint) {
data.db.releaseSavepoint(data.savepoint);
}
// data.db.commit(true); // force a commit on the connection
// too.
}
sendToErrorRow = true;
errorMessage = dbe.toString();
} else {
if (meta.ignoreErrors()) {
if (data.warnings < 20) {
if (log.isBasic()) {
logBasic("WARNING: Couldn't insert row into table: " + rowMeta.getString(r) + Const.CR
+ dbe.getMessage());
}
} else if (data.warnings == 20) {
if (log.isBasic()) {
logBasic("FINAL WARNING (no more then 20 displayed): Couldn't insert row into table: "
+ rowMeta.getString(r) + Const.CR + dbe.getMessage());
}
}
data.warnings++;
} else {
setErrors(getErrors() + 1);
data.db.rollback();
throw new KettleException(
"Error inserting row into table [" + tableName + "] with values: " + rowMeta.getString(r),
dbe);
}
}
}
if (sendToErrorRow) {
// Simply add this row to the error row
putError(rowMeta, r, data.commitSize, errorMessage, null, "TOP001");
outputRowData = null;
} else {
outputRowData = null;
// A commit was done and the rows are all safe (no error)
if (rowIsSafe) {
for (int i = 0; i < data.batchBuffer.size(); i++) {
Object[] row = data.batchBuffer.get(i);
putRow(data.outputRowMeta, row);
incrementLinesOutput();
}
// Clear the buffer
data.batchBuffer.clear(); //提交后,清空缓存
}
}
return outputRowData;新增了一个工具类ImpalaOutputUtils,附上源码:
public class ImpalaOutputUtils {
/**
* 获取insert into table values语句
* @param db
* @param schemaName
* @param tableName
* @param fields
* @return
*/
public static String getInsertStatement(Database db, String schemaName, String tableName, RowMetaInterface fields) {
StringBuffer ins = new StringBuffer(128);
String schemaTable = db.getDatabaseMeta().getQuotedSchemaTableCombination(schemaName, tableName);
ins.append("INSERT INTO ").append(schemaTable).append(" (");
// now add the names in the row:
for (int i = 0; i < fields.size(); i++) {
if (i > 0) {
ins.append(", ");
}
String name = fields.getValueMeta(i).getName();
ins.append(db.getDatabaseMeta().quoteField(name));
}
ins.append(") VALUES ");
return ins.toString();
}
public static Statement createStatement(Database db) throws KettleDatabaseException {
try {
return db.getConnection().createStatement();
} catch (SQLException e) {
throw new KettleDatabaseException("Couldn't create statement:", e);
}
}
/**
* 构建 (value1,value2,value3),(value1,value2,value3),(value1,value2,value3)
* @param data
* @param tableName
* @return
* @throws KettleDatabaseException
*/
public static String getBatchSql(ImpalaOutputData data, String tableName) throws KettleDatabaseException {
StringBuffer sql = new StringBuffer(data.sqls.get(tableName));
for (Object[] row : data.batchBuffer) {
StringBuffer rowValues = new StringBuffer();
for (int i = 0; i < data.insertRowMeta.size(); i++) {
ValueMetaInterface v = data.insertRowMeta.getValueMeta(i);
Object cell = row[i];
try {
switch (v.getType()) {
case ValueMetaInterface.TYPE_NUMBER:
rowValues.append(v.getNumber(cell).doubleValue()).append(",");
break;
case ValueMetaInterface.TYPE_INTEGER:
rowValues.append(v.getInteger(cell).intValue()).append(",");
break;
case ValueMetaInterface.TYPE_STRING:
rowValues.append("\"").append(v.getString(cell)).append("\"").append(",");
break;
case ValueMetaInterface.TYPE_BOOLEAN:
rowValues.append(v.getBoolean(cell).booleanValue()).append(",");
break;
case ValueMetaInterface.TYPE_BIGNUMBER:
rowValues.append(v.getBigNumber(cell)).append(",");
break;
default:
rowValues.append("\"").append(v.getString(cell)).append("\"").append(",");
break;
}
} catch (Exception e) {
throw new KettleDatabaseException(
"Error setting value #" + i + " [" + v.toStringMeta() + "] on prepared statement", e);
}
}
rowValues.setCharAt(rowValues.length() - 1, ' ');
sql.append("(").append(rowValues).append("),");
}
sql.setCharAt(sql.length()-1, ' ');
return sql.toString();
}
}
编译并打包插件ant dist
成功后在dist目录下看到jar以及压缩包:

把压缩包解压后并拷贝到spoon工具的plugins目录下,此时pentaho-big-data-plugin应该已经存在:
![]()
启动spoon后,如果在左侧的输出目录中可以看到自定义的插件,至少说明插件已经被kettle加载到了,然后测试:
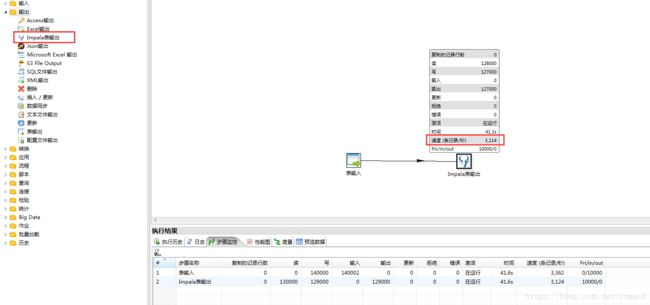
修改后的插入速度达到了3000+每秒,还可以接受
HiveJdbc Vs ImpalaJdbc
上面有说到cloudera公司也出了个ImpalaJdbc,在批量插入impala-kudu表过程中也有尝试使用它,因为在ImpalaJdbc中看到了很多HiveJdbc没有实现的方法它都实现了,例如executeBatch这些都已经实现了,但很奇怪的是,自己写了个demo并使用executeBatch方式进行批量插入测试时依然只有100+的速度,由于ImpalaJdbc不开源,没办法踪具体的原因。
另外对于insert into table(col1,col2,col3) values(v1,v2,v3),(v1,v2,v3),(v1,v2,v3)….这种方式的sql执行,使用ImpalaJdbc的速度只有使用HiveJdbc时的零点几倍。