pythonBP神经网络识别数字
因为课程要求需要做个神经网络的大作业,就顺便记录下来
BP神经网络原理
BP神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。
BP神经网络的计算过程由正向计算过程和反向计算过程组成。正向传播过程,输入模式从输入层经隐单元层逐层处理,并转向输出层,每~层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入反向传播,将误差信号沿原来的连接通路返回,通过修改各神经元的权值,使得误差信号最小。
(以上来自百度百科)
参考
这次主要学习了《Python神经网络编程》塔里克·拉希德 著,林赐 翻译这本书,这本书写得非常不错,讲得很简单很好理解,对初学者非常友好。下面的代码也是根据书中给的源码略作修改的。
话不多说下面正式开始。
获取测试训练集
MNIST 是一个有名计算机视觉数据库,我们就用它来做我们的数据集。
MNIST 的官网是 http://yann.lecun.com/exdb/mnist/ 。

这几个文件分别是
测试集图像:train-images.idx3-ubyte
测试集标签:train-labels.idx1-ubyte
训练集图像:t10k-images.idx3-ubyte
训练集标签:t10k-labels.idx1-ubyte
图像集里面的其实并不是一张张图片,而是一大堆数组,每一行有784个0~255像素值组成的数组,代表一个数字图像。所以使用的时候需要读取图像集中的一行数组,对应的标签集里面同一行的数字就是这图像所代表的数字。
我是参考这位老哥的博客的代码(https://blog.csdn.net/weixin_40522523/article/details/82823812 ),具体如下,如果有不明白的,他的博客中已经解释得非常清楚,就不赘述了。
import numpy as np
#读取图片文件
def read_image(path):
with open(path, 'rb') as f:
magic, num, rows, cols = unpack('>4I', f.read(16))
img = np.fromfile(f, dtype=np.uint8).reshape(num, 784)
return img
#读取标签文件
def read_label(path):
with open(path, 'rb') as f:
magic, num = unpack('>2I', f.read(8))
lab = np.fromfile(f, dtype=np.uint8)
return lab
#调用例子
img=read_image(
"C:\\t10k-images-idx3-ubyte\\"
"t10k-images.idx3-ubyte")
label = read_label(
"C:\\t10k-labels-idx1-ubyte\\"
"t10k-labels.idx1-ubyte")
建立网络
接下来我们建立一个三层的bp神经网络用于训练我们的数据,当然这个网络也可以用于其他地方,只要修改隐藏层数、节点数等参数就可以了。
首先需要给出初始权重,我用的是均值为0,标准方差为输入节点数目的开方的正态分布,然后就是一个根据误差不断修正链接权重的过程。
修正j,k节点之间权重公式:
Δ w j , k = α ∗ E k ∗ s i g m o i d ( O k ) ∗ ( 1 − s i g m o i d ( O k ) ) ⋅ O j T \Delta w_{j,k}=\alpha *E_k*sigmoid(O_k)*(1-sigmoid(O_k))\cdot O_j^T Δwj,k=α∗Ek∗sigmoid(Ok)∗(1−sigmoid(Ok))⋅OjT
α \alpha α是学习率
E k E_k Ek是误差
s i g m o i d sigmoid sigmoid是激活函数
O k O_k Ok是k点输入
O j T O_j^T OjT是j点输出的转置
具体代码如下:
class neuralNetwork:
#初始化
def __init__(self,inputnodes,hiddennodes,outputnodes,learninggrate):
self.inodes=inputnodes#输入层节点
self.hnodes=hiddennodes#隐藏层节点
self.onodes=outputnodes#输出层节点
self.lr=learninggrate#学习率
#链接权重矩阵
self.wih=np.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes))#input和hidden的权重矩阵
self.who=np.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes))#hidden和output的权重矩阵
pass
#训练
def train(self,inputs_list,targets_list):
inputs = np.array(inputs_list, ndmin=2).T
targets=np.array(targets_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.Sigmoid(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.Sigmoid(final_inputs)
#误差
output_errors=targets-final_outputs
hidden_errors=np.dot(self.who.T,output_errors)
#优化权重
self.who+=self.lr*np.dot((output_errors*final_outputs*(1.0-final_outputs)),np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)),
np.transpose(inputs))
pass
#查询
def query(self,inputs_list):
inputs=np.array(inputs_list,ndmin=2).T
#把输入的list转换成numpy的array才能通过numpy模块进行矩阵运算。
#numpy.array()的第一个参数为被转换的数组,ndmin参数为转换后的维数。
#假设inputs_list的长度为len,通过np.array(inputs_list, ndmin=2)这
# 条语句会被复制并转换为一个大小为(1,len)的矩阵。转置以后便是一个大小为(len,1)的矩阵
hidden_inputs=np.dot(self.wih,inputs)
hidden_outputs=self.Sigmoid(hidden_inputs)
final_inputs=np.dot(self.who,hidden_outputs)
final_outputs=self.Sigmoid(final_inputs)
return final_outputs
训练数据
我们使用MNIST的t10k-images.idx3-ubyte和t10k-labels.idx1-ubyte来训练
首先给出初始值
input_nodes=28*28
hiddden_nodes=200
output_nodes=10
learning_rate=0.1
n=neuralNetwork(input_nodes,hiddden_nodes,output_nodes,learning_rate)
然后开始训练,我们输出节点共有10个代表0-9,10个数字,输入节点有28*28个代表一张图像784个像素值,所以我们只要输入一张图片的像素值,然后得到输出节点的10个值,每个值代表对应的数字的可能性有多高,只要选取可能性最高的点所在节点,就是我们这个网络对这个图像识别出来的数字了。
所以在训练时,如果训练样本标签是0,那么创建出来的目标数组的第一个节点的值应该大于其他节点的值,我们就要手动把目标数组设置为类似与[1,0,0,0,0,0,0,0,0,0]的样子。
在这里我使用的最大值是0.99,最小值是0.01,所以我甚至的数组应该是[0.99,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01]。
我们训练图像集中的数组是0-255的,为了后续计算需要先进行归一化。
inputs = img / 255.0 * 0.99 + 0.01
好了现在开始训练:
l=len(label)
for record in range(0,l):
targets=np.zeros(output_nodes)+0.01
targets[label[record]]=0.99
n.train(inputs[record],targets)
再把权重矩阵作为训练模型保存下来
import _pickle as cpickle
with open('testwih.pickle', 'wb') as f:
cpickle.dump([n.wih], f,0)
f.close()
with open('testwho.pickle', 'wb') as f:
cpickle.dump([n.who], f,0)
f.close()
测试模型
只要把权重矩阵放入函数中,得到的值与标签中比对一下就清楚了。
代码如下:
l_test = len(label_test)
for record in range(0, l_test):
g = query(wih,who,inputs_test[record])
label_get = np.argmax(g)
if (label_get == label_test[record]):
score += 1
score /= l_test
print("正确率=", score)
结果:
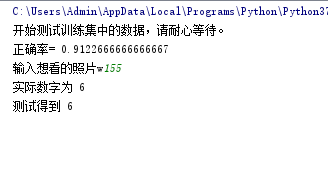

好了,就是这样,详细代码可以在这里下载:
https://download.csdn.net/download/czq_0768/11250387 。里面有训练代码、测试代码和两个保存的训练权重矩阵。