新手科普 | 探索机器学习模型,保障账户安全
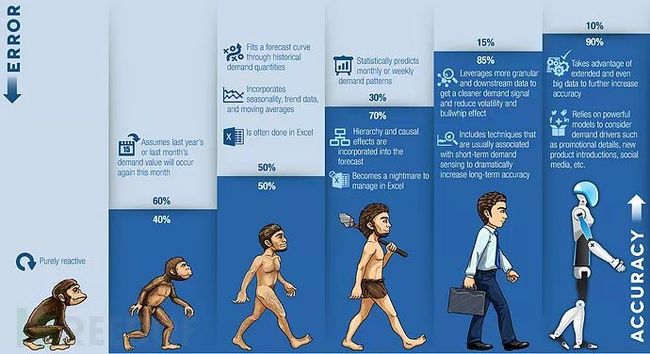
账号安全往往是企业首先需要保障安全的数据之一,薅羊毛、账号泄露,背后的原因都是账号保护的缺失。
本文转自FreeBuf.COM
但如何保障账户安全往往是企业需要面临的难题,而随着攻击者的手段越来越高超,网站需要找到行之有效的方法保护账号安全,本篇文章就以Uber团队的账号安全建设为例,给大家讲讲如何用机器学习保障账号安全。
传统的保护账户安全的方法是对你的系统和分析员进行训练,让他们从正常的用户行为中找出异常行为,一旦能找出异常,就可以加以屏蔽。
但在实际操作中,识别异常登录往往非常困难,并且黑客可以使用钓鱼等手段获取到正常用户的密码信息用于登录,因此,工程师采用了多层防御保护这些账号。
本文以Uber团队建设账号保护系统的思路为例。这套保护系统包含传统的判断因素,包括速率限制,以及启发式特征规则,系统会应用机器学习模型。分析师能够部署规则快速响应特定攻击,相反,如果使用速率限制和机器学习,影响到的范围会更大。
在开始介绍之前,我们先介绍一下机器学习的种类,机器学习可以分成下面几种类别:
监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类。
半监督学习介于监督学习与无监督学习之间。
增强学习通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
而深度学习则是机器学习拉出的分支,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。
机器学习模型
对于Uber来说,想要建造一个机器学习模型是个挑战,因为攻防双方在不断对抗,骗子会想尽办法更换攻击模式对付模型。
下面的是Uber制作的两个模型,用于识别可疑的登陆行为。一旦识别出异常,Uber就会让用户使用双因素认证验证身份。如果登陆行为特别可疑,还可以主动去进行一些操作保护用户,比如重置密码、通知用户等。
半监督模型
前文提到,机器学习的学习方法多种多样,有监督学习、无监督学习。而半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作。

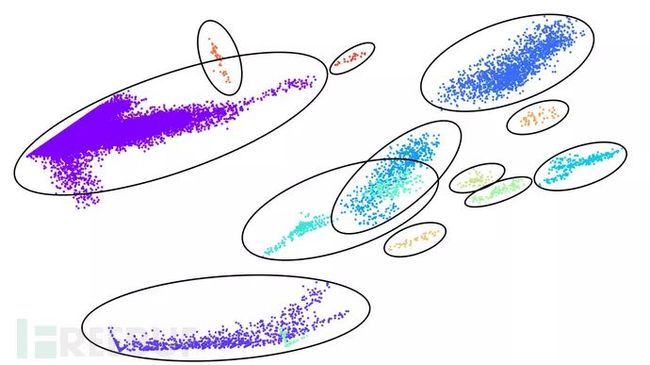
检测异常登录的一种方法是检查攻击者登陆的特征,比如IP地址等。黑客的条件参差不齐,有些只会用到几个IP进行攻击,有些则会用到上万。常见的拥有那些IP的人是web host服务商,tor代理,或者是一些被病毒入侵的个人设备组成的僵尸网络(参考Mirai)。
这是Uber使用的基于IP地址的聚类模型,他们用到PCA降维到二维,使得数据更加方便可视。图片中的点都是IP地址。上下两张图显示的分别是2016年年中和2017年年终的登陆情况,这些聚类的特征其实已经很不同了,这是因为攻防对抗导致攻击者在一年时间里对登陆特征进行了改变。
Uber使用了半监督方法将可疑IP归类到一起。对于每个IP都会加上标签。随后根据算法区分好坏IP的效率对特征进行调整。
这里有一点需要注意,最好使用攻击者难以控制的特性,这样能够让模型更加准确。另外,Uber选用了10个影响较大的特征,然后使用DBSCAN聚类算法寻找IP聚类。
一旦机器学习模型返回聚类特征,分析人员就可以对每个聚类计算某些特定的指标,识别出这个聚类是好是坏。这样的话,其实分析员不需要实现对所有IP加上标签。如果有一些新的聚类中的标签不足以判断IP的好坏,Uber就会提示进行双因素认证,或者通过人工审核来判断。
无监督学习
半监督方法需要事先对样本加上标签,并且防御是被动的,必须等到攻击者发动进攻才可以进行防御。相比之下,无监督学习方法不需要进行标签,也就能够更主动地防御攻击。Uber只会使用正常用户的用户行为训练模型,然后把其他任何不一致的行为判断为异常。除非攻击者是发动针对性攻击(对于一般的攻击者而言这需要资金),否则他们不知道正常用户的用户行为,因此很难绕过检测模型。
比如,某个用户之前去过巴西,那他去印度的概率就不是特别大。安全团队建立了一个深度学习模型学习城市之间的关系。模型会把用户之前旅行过的地方和购买食物的订单作为输入数据,模型会预测下一次用户会去哪些地方。
对于大型数据以及高维度的数据集,深度学习的效果要好得多。因此深度学习相比传统的机器学习更加适合解决这类问题。神经网络相比传统的机器学习拥有的参数更多,因此要想充分训练,就需要喂入更多的数据。除此之外,传统的机器学习很难处理长度不均的数据,而深度学习有循环神经网络层,例如LSTM(Long Short-Term Memory,长短期记忆网络),更擅长处理这些数据。
Uber团队从调查了代表城市的embedding,这是一个低维度映射,用城市之间的距离代表用户在城市之间旅行的可能性。如果仅仅使用经纬度的话,不能捕捉到用户在城市之间旅行的趋势。 团队将自然语言处理(NLP)中常用的word2vec算法应用于算法,以便通过经纬度以外的信息洞察城市间的关系。随后团队使用内部GPU基础架构,通过数亿个训练集训练该模型。


小结
本文介绍了使用半监督学习和无监督学习算法识别异常用户的方法。特别是无监督学习,具有更广的通用性,能够识别各种设备产生的异常用户。
但实际上保卫账户安全的斗争远远没有结束,在今年8月举办的2017腾讯安全国际技术峰会上,腾讯安全部总经理杨勇提到,黑产在此方面的技术投入也是极大的。黑产也在应用AI技术,他们甚至有应用神经网络的验证码识别系统,准确率能够达到惊人的95%,覆盖了市面上80%的验证码。这就需要互联网公司不断提升壁垒,跟上节奏,用最新的技术保障用户安全。
参考来源:Uber Security
https://medium.com/uber-security-privacy/uber-machine-learning-account-security-3aaadef11e45
译文地址
http://www.freebuf.com/articles/rookie/150179.html
一百天人工智能工程师学习计划——全程实战案例,从机器学习原理到推荐系统实现,从深度学习入门到图像语义分割及写诗机器人,再到专属GPU云平台上的四大工业级实战项目。100天内完美掌握人工智能工程师必备技能。

☞ 点击阅读原文,查看详细课程信息。