如何将GPU性能提升4-5倍?创新奇智提出基于NVRAM TPS的Helper Warp方法 | 技术头条...

「2019 Python开发者日」明日开启,扫码咨询 ↑↑↑
作者 | 张发恩等人
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】近日,在 2019 年第 56 届设计自动化大会(DAC,英文全称 ACM/IEEE Design Automation Conference,是电子设计自动化和嵌入式系统领域的顶级会议),创新奇智 CTO 张发恩等人联合发布了一篇论文《Efficient GPU NVRAM Persistence with Helper Warps》。该论文首次提出一种方法,通过在 GPU 上使用 NVRAM 存储的有效并且易于使用的事务处理系统,在特定应用场景下,GPU 性能获得了 4~5 倍的提升。

上周,AI科技大本营记者现场走进创新奇智,张发恩为 AI科技大本营记者讲解了这项最新的研究成果。张发恩谈到在人工智能时代,算法、算力与数据是三个最重要的要素。科学家和工程师将 GPU 应用于人工智能模型训练和推理后,带来了巨大的算力提升。但在某些场景下,GPU 性能并没有完全发挥,如何进一步提升 GPU 性能已成为众多AI公司的重要关注点。
所以,在这篇论文中,张发恩团队首次提出一种方法,通过在 GPU 上使用 NVRAM 存储的有效并且易于使用的事务处理系统,在特定应用场景下,让 GPU 性能获得了 4~5 倍的提升。这篇论文也被 2019 年第 56 届设计自动化大会接收。(ACM / IEEE Design Automation Conference,简称 DAC,是电子设计自动化和嵌入式系统领域的顶级会议。)
论文地址:
https://dac.com/content/2019-dac-accepted-papers
论文解读

摘要
非易失性随机存取存储器(NVRAM)是近年来出现的一种用于弥补主存和外部存储设备之间性能差距的存储器。为了利用 NVRAM 的非挥发性,程序应该允许持久化存储,这意味着在断电事件期间必须保持一致性。利用高度的并行性,GPU 的设计具有高吞吐量。然而,与 DRAM 相比,NVRAM 具有更低的写入带宽,按照原样使用 NVRAM 可能会产生次优的总体系统性能。为了解决这个问题,作者提出使用 Helper Warp(本文中将简单译为辅助调度单位)将持久性移出事物执行的关键路径,从而减轻延迟的影响。在带宽限制为 1.6GB/s 和 12GB/s 的情况下,该机制分别实现了 4.4 倍和 1.5 倍的加速,并且预计即使在 NVRAM 带宽高达数百 GB/s 的某些情况下,也将保持速度优势。
介绍
非易失性随机存取存储器(NVRAM)作为一种很有前途的 DRAM 替代品,在过去的几年里逐渐成熟起来。NVRAM 具有大容量和持久性,因此可以启用和证明诸如事物内存之类的新编程范例。
可字节寻址的持久存储设备(如NVRAM)有几种不同的使用方式。在最简单的形式中,它可以作为 DRAM 或者缓存的大容量临时替代。这种类型的系统在 CPU 和 GPU 上都讨论过,但是没有利用它们的持久性。另一种更复杂的方法是使用 NVRAM 作为持久数据存储,使其成为事务处理系统(TPS)的一个组成部分。TPS 的体系结构通常包括两层:并发协议层,它可能表现为事务内存或者锁定机制,负责检测和解决事务之间的完整性;日志层,以日志的形式执行写操作,以实现持久性,从而在断电事件期间保持数据完整性。在 CPU上,这种 TPS 系统可以涉及硬件、软件和编程语言级别的变化;在 GPU 上是落后于 CPU 的,因为在 GPU 上存在基于事务内存的工作但在当前时刻不存在基于 NVRAM 的 TPS 系统。
尽管 NVRAM 的存储密度较大,但它提供的带宽比 DRAM 的缓存要少。因此,需要很好地管理带宽引起的延迟,以避免性能下降。为了减轻带宽差距带来的损失,需要采用软硬件结合方法。
本文主要有以下三点贡献:
(1)在这篇工作中作者首次提出了在 GPU 上使用 NVRAM 存储的有效并且易于使用的事务处理系统。
(2)作者提出使用 Helper Warp,利用 GPU 的闲置计算资源来缓解写入带宽的限制。
(3)作者建立了一种在不同的程序下能够自适应地启用 Helper Warp(辅助调度单位)达到最佳性能的机制。
高效的 GPU NVRAM 持久性支持
事务处理通常由并发控制和持久性日志记录两部分组成。论文研究的系统采用软件事务内存(STM)进行并发控制。作者提出的 STM 算法采用了快速冲突检测以及重做日志记录,并解决与全局所有权记录的冲突。写/读集跟踪的粒度是一个32位机器字。对较大数据的访问被视为多个 32 位机器字。该算法不区分读与写,并通过支持线程 ID 较低的事务来解决冲突。具体的算法步骤如图 2 所示。

图2:论文中使用的 STM 算法
在上述 TM 算法中,对 NVRAM 的写入发生在成功提交期间。在默认的严格的 Persis-tency 模型下,事务必须等待 persist操作完成之后才能声明提交成功。这将 NVRAM 写延迟添加到事务执行的关键路径上,从而增加时间开销。为了解决这个问题,论文作者提出了一个 commit 过程,它利用 Helper Warp 将延迟移出关键路径。
作者提出的方法使用辅助调度单位来分离事务的提交和持久步骤。辅助调度单位负责处理事务的持久性部分,使持久操作能够与事务的其余部分异步完成。图3 显示了添加了辅助调度单位的总体提交协议。
带有辅助调度单位的高效日志系统
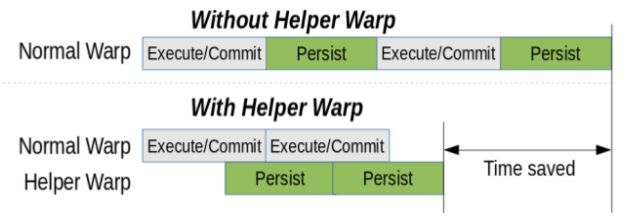 图3:论文提出框架中的事务时间线
图3:论文提出框架中的事务时间线
每个线程块中都有一个辅助调度单位,它通过每个线程块共享内存与正常调度单位通信。此外,每个流多处理器(SM)都有一个带宽监控窗口,用于跟踪运行时的瞬时带宽占用情况。图4 演示了作者提出的框架,它包括内存拓扑和添加的部分。易失性 RAM 和非易失性RAM之间的联系类似于最近的 AMD Vega 框架,该框架旨在支持异构内存框结构,如 SSD 和 DRAM。
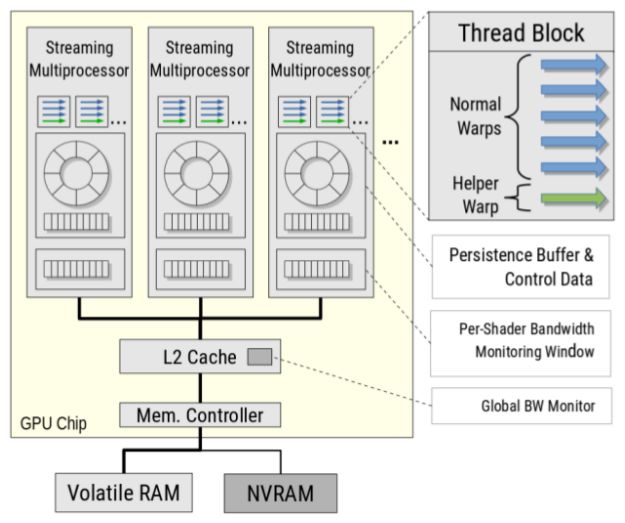
图4:总体系统框架
系统评估
图6 展示了使用实验设置的基准测试的运行时间,包括启用和禁用辅助调度单位。这些线表示运行时间随着 NVRAM 带宽限制而变化的趋势。绿色和红色的线和点分别表示启用和禁用辅助调度单位的运行时间。随着带宽的降低,两种配置的运行时间都会增加。不过,没有辅助调度单位的运行时间最终会增长得更快,并超过启用辅助调度单位的运行时间。这两条运行时间存在交叉点。H1 的交叉点高达 484GB/s(这意味着即使在易失性RAM带宽下,辅助调度单位的性能也会更好),而BVH1的交叉点则低至11.75GB/s。
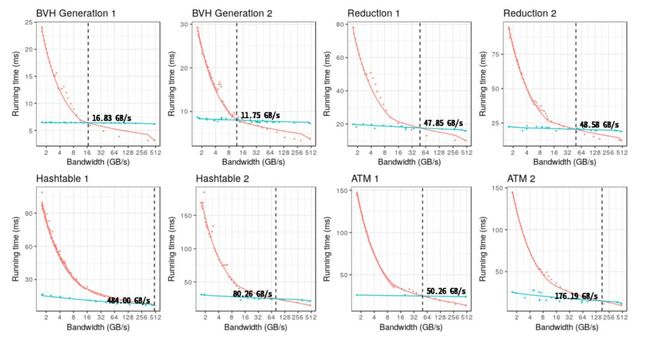
图6:基准测试的总体运行时间,启用了辅助调度单位(绿色)和禁用了辅助调度单位(红色)
图7 展示了基准测试 A1 中第 0 块中事务的提交时间线。可以看出,当持久性带宽限制为 1.6GB/s 时,连续提交会出现很大的差距。由于不同块之间的行为是相似的,这种差异将直接转化为更长的总体运行时间。有了辅助调度单位,差距明显减小,从而大大缩短了基准测试的运行时间。
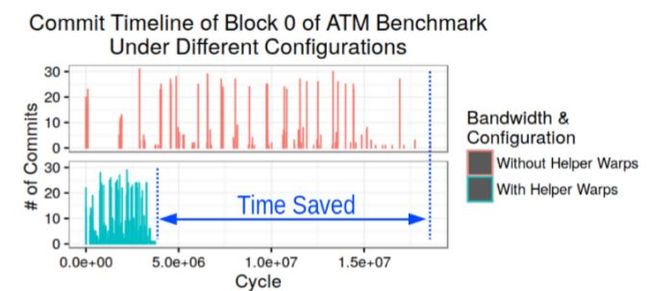
图7:基准测试A1的块级事务提交时间线
图8 展示了线程块 0 中事务执行时间的细分情况,其中辅助调度单位静态地打开和关闭。由于带宽有限造成的每个 sistence 阶段的延迟会导致“caso-cade”效应,使得其他提交事务的时间比带有辅助带调度单位的时间长。这是由于调度单位级别的差异和持有所有权记录使得提交事务需要等待冗长的持久性操作的完成。这也增加了中止率。通过启用辅助调度单位,持久性可以更快地完成,并且“级联”效应得到了缓解。
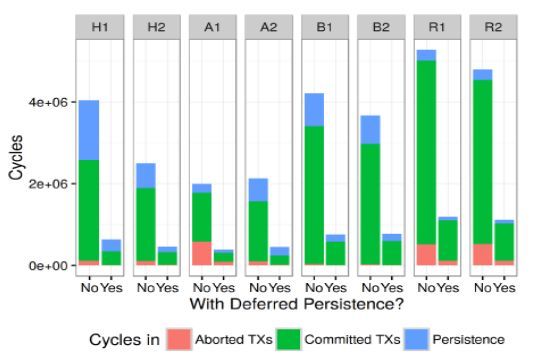
图8:基于元数据TM的事务平均执行时间的细分
图9 显示了辅助调度单位在操作中的切换以响应不断变化的持久性带宽。总的来说,切换显著减少了 H1 内核的时间,与总是关闭辅助调度单位相比运行时间提高了 20%,与总是打开辅助调度单位相比运行时间提高了 6%。

图9:基准测试B1+H1的持续带宽趋势,带有辅助调度单位的自适应切换(上图)和3种配置的运行时间细分(下图)
与 BVH 基准测试相反,其他一些基准测试将观察到提交带宽高于大多数程序执行的阈值,比如 A2。其持久性带宽趋势可以在图10(顶部)中观察到。对于这个基准测试,始终静态地打开或关闭辅助调度单位会导致轻微的性能损失,如图10(底部),这是由于切换所涉及的开销造成的。

图10:基准测试A2的持续带宽趋势,关闭辅助调度单位(顶部)和3种配置的运行时间细分(底部)
结论
在本文中,作者观察到事务 GPU 程序的性能下降来源于 NVRAM 的带宽限制,这种限制导致了长时间的持久性延迟。当 NVRAM 用作主存的临时替代品时,延迟将直接添加到事务的关键路径上,从而使事务的运行时间更长。此外,这种延迟可能会影响位于相同调度单位的其他线程,从而导致整个基准测试的运行时间更长。
作者提出了 Helper warp 这个概念,它由位于片上共享内存中的提交缓冲区组成,事务提交将被重定向到该缓冲区。这将从关键路径中移除时间开销,使持续性操作更快。作者还提出了一种方法,使辅助器仅在需要最好性能时才使用。在某些情况下,阈值可能高达每秒数百 GB。这包括今天和不久的将来可用的 NVRAM 带宽范围。
作者介绍
张发恩,创新奇智CTO、联合创始人,创新工场人工智能工程院首席架构师。毕业于中国科学院软件研究所,曾任百度主任研发架构师、百度云计算事业部技术委员会主席、百度云计算事业部大数据和人工智能首席架构师,还曾在 Google 和微软担任研发职务。在 IT 行业拥有十年以上的技术研发和管理经验,涉及企业级软件、室内地图定位与导航、互联网搜索引擎、全领域知识图谱、大数据分析与存储、机器学习、深度学习等众多领域。工作期间获得 10 余项美国专利,30 余项中国专利。

张发恩,创新奇智CTO、联合创始人,创新工场人工智能工程院首席架构师
(本文为 AI大本营整理文章,转载请微信联系 1092722531)
◆
倒计时1天
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。目前大会倒计时 1 天,更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
抵制996!Python之父发声背后,这个社区一呼百应!
39个国外SCI抢发6万篇中国英文论文?然而,真正的问题是……
什么是网络爬虫?有什么用?怎么爬?终于有人讲明白了
“重构”黑洞:26岁MIT研究生的新算法 | 人物志
程序员 996 再上热搜,黑名单增至 84 家!
京东“地震”
V神玩起freestyle! 5位以太坊核心大咖在悉尼的演讲精华全在这了!| 直击EDCON
为什么给黑洞拍照需要这么长时间?
刺激!我31岁敲代码10年,明天退休!
![]()
❤点击“阅读原文”,了解「2019 Python开发者日」