Tensorflow学习之搭建神经网络
搭建神经网络
一、基本概念
基于Tensorflow的NN:用张量表示数据,用计算图搭建神经网络回话执行计算图,优化线上的权重(参数),得到模型。
张量:就是多维数组(列表),用“阶”表示张量的维度。
0阶张量就是一个数;
1阶张量是xia向量,表示一个一维数组,V=[1,2,3];
2阶张量就是矩阵。表示一个二维数组,m=[[1,2,3], [4,5,6], [7,8,9]]
判断张量是几阶的,就是通过张量右边的方括号数量
数据类型:Tensorflow 的数据类型有tf.float32、tf.int32等
![]()
最终打印出来的结果表示这是一个名称为 ”add:0“ 的张量,shape=(2,)表示一位数组长度为2,dtype=float32 表示数据类型为浮点型。
计算图(Graph):搭建神经网络的计算过程,是承载一个或多个计算节点的一张图,只搭建网络,不运算
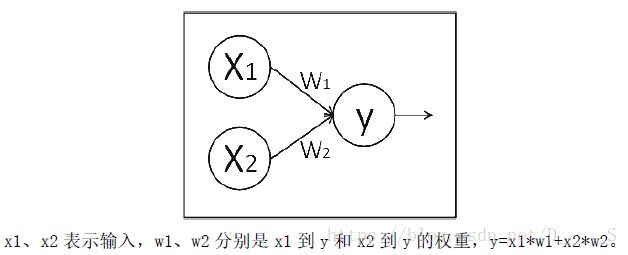
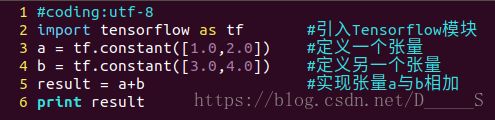
实现上诉j计算图:


此结果中打印出的y是一个张量,后用会话ji's计算出了结果:1.0*3.0+2.0*4.0=11.0
注:更改vim的配置,在 vim~/.vimrc中写入:
set ts = 4 表示用Tab键等效为四个空格
set nu 表示使vim显示行号
在vim编辑器中运行Session()会话时有时会出现warning,是因为有的电脑可以支持加速指令,但是运行代码时并没有启动这些指令。可以把这些warning暂时屏蔽掉。方法为:进入主目录下的bashrcwe文件
![]()
在bashrc文件中加入 export TF_CPP_MIN_LOG_LEVEL=2。这个命令可以控制python程序显示提示信息,在Tensorflow中一般预设值为‘0’(显示所有信息)或者‘1’(不显示info),‘2’表示不显示warning,‘3’表示不显示error。
最后用来改执行修改后的文件。
神经网络的参数:是指神经元线上的权重w,用变量表示,一般会先随机生成这些参数。生成参数的方法是让 w = tf.Variable,把生成的方式写在括号里。神经网络常用的生成随机数/数组的函数有:


二、神经网络的搭建
神经网络的实现过程:
1、准备数据集,提取特征,作为输入喂给神经网络(Neural Network,NN)
2、搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
3、大量特征数据喂给NN,迭代优化NN参数
4、使用训练好的模型预测和分析
三、前向传播
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出。
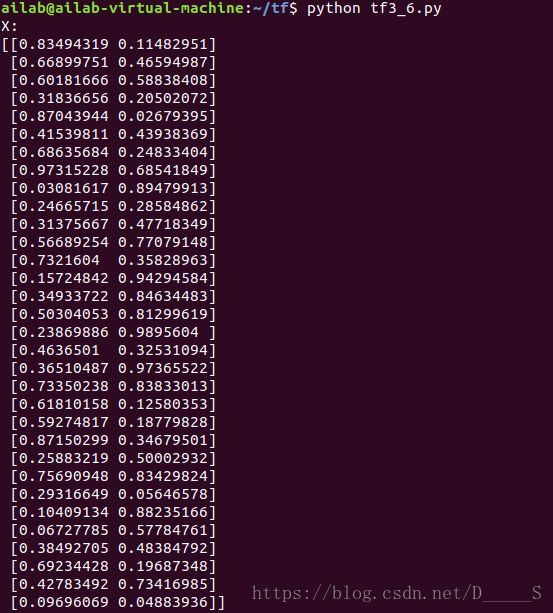
假如生产一批零件,体积为x1,重量为x2,体积和重量就是选择的特征,把它们喂入神经网络,当体重和重量这组数据经过神经网络后会得到一个输出。假设输入的特征值是:体重0.7,重量0.5

变量初始化、计算图节点运算都要用会话实现
with tf.Session() as sess:
sess.run()变量初始化:在 sess.run 函数中用 tf.global_variables_initializer() 汇总所有待优化变量。
init_op = tf.global_variables_initializer()
sess.run(init_op)计算图节点运算:在 sess.run 函数中写入待运算的节点
sess.run(y)用 tf.placeholder 占位,在 sess.run 函数中用 feed_dict 喂数据
喂一组数据:
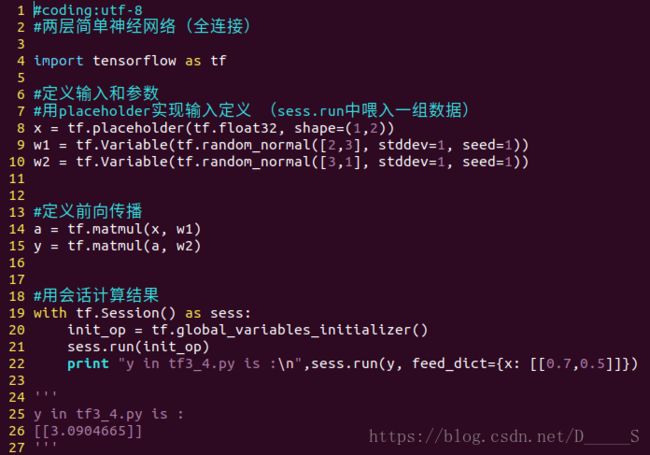
x = tf.placeholder(tf.float32, shape=(1, 2))
sess.run(y, feed_dict = {x: [[0.5,0.6]]})喂多组数据:
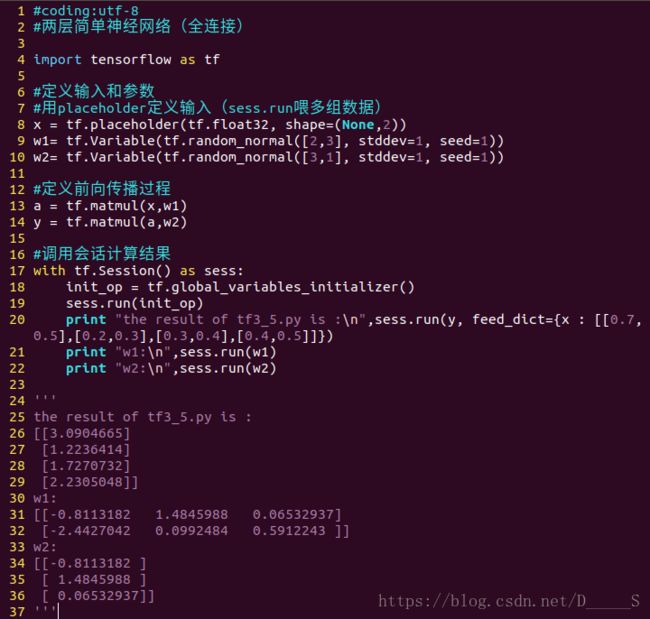
x = tf.placeholder(tf.float32, shape=(None, 2))
sess.run(y, feed_dict = {x: [[0.1,0.2], [0.2,0.3], [0.3,0.4], [0.4,0.5]]})下面是一个实现神经网络前向传播过程的列子:
(1)喂入一组数据
(2)喂入多组数据
四、反向传播
反向传播:训练模型参数,在所有参数上用梯度下降,使NN模型在训练数据上的损失函数最小。
损失函数(loss):计算得到的预测值y与已知答案y_的差距。
均方误差法(MSE):求前向传播计算结果与已知答案之差的平方再求平均。
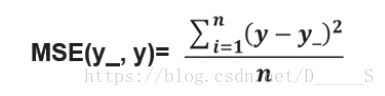
函数表示为:
loss_mse = tf.reduce_mean(tf.square(y_ - y))反向传播训练方法:以减小 loss 值为优化目标,有梯度下降、momentum优化器、adam优化器等优化方法。
函数表示为
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
train_step = tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)学习率:决定每次参数更新的幅度。优化器都需要学习率参数,学习率太大会出现震荡不收敛,学习率太小,会出现收敛速度慢。一般选用0.01、0.001。
五、搭建神经网络的八股
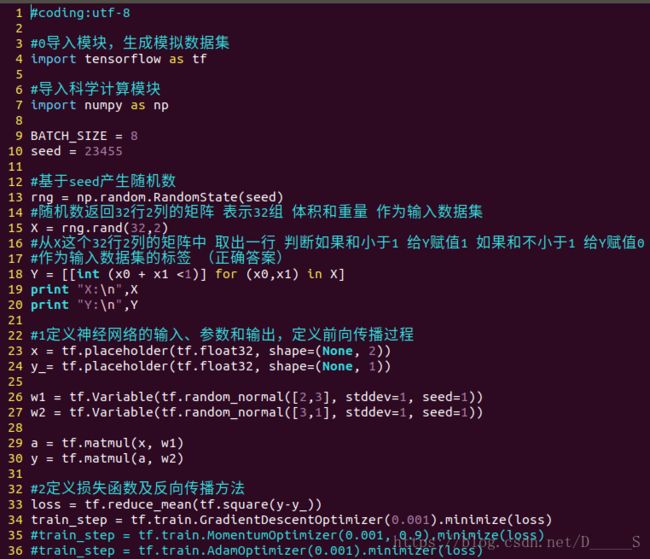
0.导入模块,生成模拟数据集
import
常量定义
生成数据集
1.前向传播:定义输入、参数和输出
x = y_ =
w1= w2=
a = y =
2.反向传播:定义损失函数、反向传播方法
loss =
train_step =
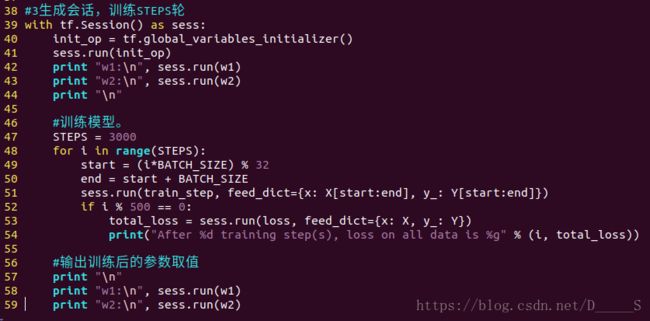
3.生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initilizer()
sess.run(init_op)
STEPS = 3000
for i in range (STEPS):
start =
end =
sess.run(train_step, feed_dict:)
举例:随机产生32组生产处的零件的体积和重量,训练3000轮,每500轮输出一次损失函数。