马蜂窝爬虫--往期创作整理
目录
1网站目标:
2网站分析
2.1第一步获取月份
2.2第二部根据月份获取城市url
2.3第三部根据top5景点链接获取景点信息
3所用技术
3.1爬取技术
3.1.1模仿浏览器请求数据包
3.1.2正则表达式提取关键信息,动态构建url请求
3.1.3Beautifulsoup大量获取
3.1.4Xpath精确定位
3.1.5url字典
3.2反扒技术
3.2.1Useragent轮转,PC,安卓,IOS
3.2.2IP代理池设置,免费代理ip获取
3.2.3虚假访问延迟
3.2.4绕开蜜罐
3.3存取技术
3.3.1Json文件存取
3.3.2Sheet分组Excel储存
3.3.3异常不中断爬取
4.原码连接
1网站目标:
Host:马蜂窝旅游网
内容:当季推荐,http://www.mafengwo.cn/mdd/filter-tag-140.html
任务:获取当季推荐所有页数的国家/城市,按国家/城市,获取Top5景点,按景点获取主要数据
2网站分析
2.1第一步获取月份
该网页信息根据月份进行分组,推荐适合当季的观光处,我们在浏览器谷歌浏览器右键检查,选择网络监视窗,重新加载,即可看到传送过来的数据包,不同月数和页数通过FormData传递参数。
依次点开各月份可以发现,月份属性从113开始以3为步长递增。我们可以将所有月份和页数储存在数组中,然后动态生成FormData,这个数据需要我们经常维护。
月份由主机系统时间确定,time.localtime可以获得一个本地时间的元组,第二位表示月份具体使用可以百度
所有月份:113,116,119,122,125,128,131,134,137,140,143,146
所有页数:1,2,3,
部分代码如下
class FengWo_crawler:
def __init__(self):
self.monthList = [113,116,119,122,125,128,131,134,137,140,143,146]
self.pageList = [1,2,3]
self.time = time.localtime(time.time())
self.monthNum = self.monthList[self.time[1]-1]

2.2第二部根据月份获取城市url
我们有了月份便可以获得当即推荐观光数据,数据为json数据包,可通过抓包获取。
Json文件的list键对应显示景点部分的html,已经变为字符串。我们可以先将字符串复制出,利用网上的html格式化工具,美化html,格式如下

这一部分可以通过BeautifulSoup类库获取所有li标签下面的a标签,从而获取链接。
链接内含有城市id,我们要获取的是城市的top5景点,可以从前一个链接提取城市id,然后组装为top5景点url
当即推荐国家城市url: http://www.mafengwo.cn/travel-scenic-spot/mafengwo/10183.html
城市id:10183
城市top5url: http://www.mafengwo.cn/jd/10183/gonglve.html

2.3第三部根据top5景点链接获取景点信息
有了top5景点页面,即可获得top5景点url,根据url获取景点详细信息页面,最后使用xpath进行精确爬取。


3所用技术
3.1爬取技术
3.1.1模仿浏览器请求数据包
直接请求数据包可以加快爬虫的速度,缺点是要设置繁琐请求头。项目中都是使用直接请求数据包的形式爬虫的,如下示例获取当季推荐国家/城市:
首先构建formData,将构建好的formData和url作为参数放入request请求中即可获得对于的json数据包,在将json中的list键对应的数据取出
headers为了模仿浏览器而设置的请求头。
Data是所请求数据的筛选条件,有不同请求目标决定是否可选
Proxies是设置代理IP,如设置{localhost:8080}即是本机,同不设置
Verify用于设置是否取消代理警报
我们获得json数据后将里面好的html数据的部分取出,然后使用BeautifulSoup类库解析,建后面章节
class FengWo_crawler:
def __init__(self):
self.headers = { ... ... }
def getCountryID(self):
for item in self.pageList:
form_data = 'tag%5B%5D=' + str(self.monthNum) + '&page=' + str(item)
... ...
req=requests.post(url=self.url_,data=form_data,headers=self.headers,proxies=self.proxies,verify=False).json()
......3.1.2正则表达式提取关键信息,动态构建url请求
还记得我们上述的国家城市url吗:
http://www.mafengwo.cn/travel-scenic-spot/mafengwo/10183.html
其中的10183即使地区id,我们要想办法将他提取出来,然后构建地区的景点信息。通过下面函数即可。
re是python的正则类库,‘\d+’标识只匹配数字且不限制位数,findall方法会匹配所有符合的结果并返回一个数组
在这里,getNum方法会将获得的地区ID储存在全局数组中,然后再利用getNewMddUrl函数构建地区的景点界面url
def getNum(self,url_str,):
pattern = re.compile(r'\d+')
m = pattern.findall(url_str)
return int(m[0])
def getNewMddUrl(self):
for cityId in self.CityID:
url = 'http://www.mafengwo.cn/jd/'+str(cityId)+'/gonglve.html'
self.mdd_urlList.append(url)
3.1.3Beautifulsoup大量获取
在3.1.1小结代码的后保部分,我们讲到了使用BeautifulSoup类库解析数据,这里详细讲解。
如下面这段代码,html参数是数据源,字符串,xml,html等格式皆可,后面的'html.parser'代表将要转换的目标格式,通过将无序文本转换为节点文本,我们可实现数据的精确提取。
Find_all()方法可匹配所有符合的结果,返回数组,可接收两个参数,’li’代表标签类型,也可进行补充描述,如class_ = ‘???’,注意,这里的class_后面多了一个要加一个下划线,其他属性亦可,如name=’***’,type=’***’
如下面的使用find就包含两个参数,不过find是只查找一个节点。
soup = BeautifulSoup(html, 'html.parser')
for li in soup.find_all('li'):
a = li.find('div',class_="img").find('a')
self.CityID.append(self.getNum(a['href']))
3.1.4Xpath精确定位
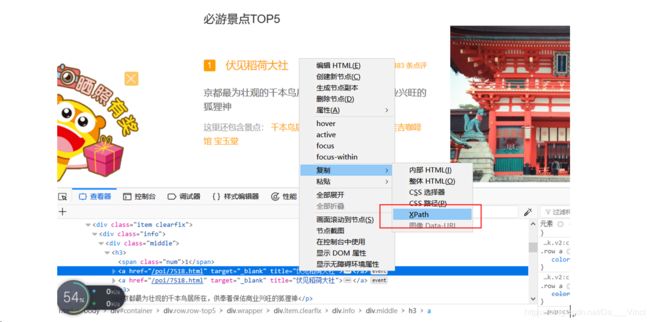
Xpath代表当前节点在文本中的路径,适合爬取固定模板显示的零散信息,主要在爬取景点界面的信息部分使用。
Xpath的写法很多,学起来有一定成本,这里的xpath由火狐浏览器提供,右键页面,查看元素,使用元素选择器,选择元素右键,即可复制xpath
例如这段代码:先是将文本转换为html文件,然后使用xpath获取title标签的text内容
html = req.text
html_ = etree.HTML(html)
a = html_.xpath('/html/head/title')[0].text
3.1.5url字典
如果想要更快的爬取,那就要使用多线程执行任务,这样url必须有一个集合来储存,具体结构,视情况而定。在本次任务,由于城市有很多景点,所以爬取景点内容适合使用多线程来执行。这里依旧是抓包爬取,可以减少诸如图片传输,可以加速爬虫。
这里我们观察两个日本景点的请求头,都是相同的键值即
Referer:http://www.mafengwo.cn/jd/10183/gonglve.html所以我们在爬取需要为不同城市的景点动态设置Referer,最后储存的结构如下
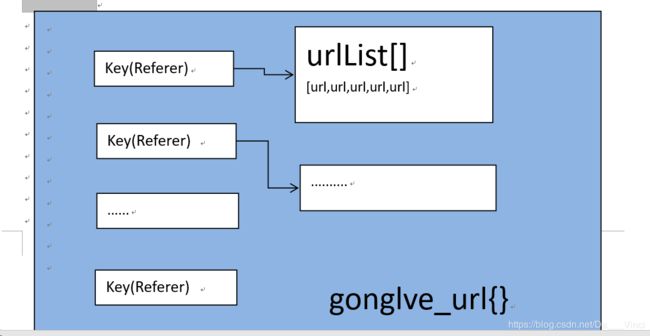
如下函数,我们将区域的url储存在LIst中,然后进行迭代,作为Top5城市url列表的Key键。
def getGonglveUrl(self):
for item in self.mdd_urlList:
... ...
list = []
try:
for div in soup.find('div',class_='row row-top5').find_all('div',class_='info'):
href = div.find('div',class_='middle').find('h3').find('a')['href']
list.append('http://www.mafengwo.cn'+href)
self.gonglve_url[item] = list
except:
print 'error'
#print self.gonglve_url


3.2反扒技术
3.2.1Useragent轮转,PC,安卓,IOS
爬虫很少会为被爬取的网站创造利益,反倒经常因为爬虫程序大量的访问造成服务器瘫痪,数据的大量采集也是网站经营者不愿意看到的,对于网站经营者来说,既要兼顾客户体验,又要防止爬虫,这是很头疼的,所以为了稳定的数据源,我们爬虫也应该适可而止。保证我们数据来源的同时,还要兼顾数据源服务器的性能。
在我们使用浏览器访问网站时,会有一串信息表示访问者的身份,识别身份应该是防止爬虫的第一关卡,我们可以伪造一段信息,加载光秃秃的request请求中。大部分信息如下。
'User-Agent'键是你的浏览器信息,包含了你的操作系统,浏览器内核等等。
*Url即是目标网站连接,必选
'Referer'键代表你是从那个页面进入这个你要访问的界面的,这个比较有趣,有时你直接复制链接访问某个网站的分页面就是让你进行验证码识别,如果我们不设置referer,也会遇到这种情况。
self.headers = {
'Accept': 'application/json,text/javascript,*/*;q=0.01',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Referer': 'http://www.mafengwo.cn/mdd/filter-tag-1400.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
这里我们可以做文章的地方就是 User-Agent,我们收集了大量useragent,随机取出,替换原来的header[‘referer’],每一个usergent都可以生成一个新的headers,即一个新的访问。
self.dict = UserAgent.MY_USER_AGENT
self.headers['User-Agent'] = random.sample(self.dict, 1)[0]
3.2.2IP代理池设置,免费代理ip获取
设置请求头让似乎让我们人多势众起来,不过这时候的程序仍然只是个笨拙的虫子,如果这是目标网站网络监测员正在工作,他会发现某一栋办公楼或学校宿舍内几十个用户在不断的访问自己的网站,因为他们的ip似乎是相同的,或者差不多,而且他们既不访问支付界面,也不是漫无目的的,而是有针对的访问特定界面,就此,爬虫与反爬上升为ip层面。
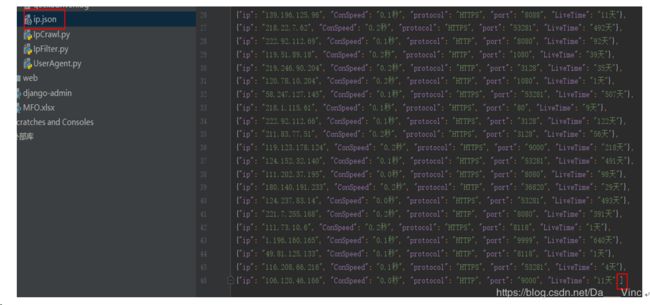
我们可以在请求中设置代理ip,代理ip可以代替我们访问目标网站,然后将获得的数据传递给我们,免费的代理ip可以从西刺网爬取,据说西刺为了防止爬取提供了一个txt文档,不过我没找到,我用的不多,只爬几页就够了。
如下截图,设置1就爬1页,爬虫中已经对ip进行预筛选,存活时间小于1天的不要,延迟大于200ms的不要。

当然程序还有不足之处。爬好的ip储存在json中,要手动为json加【】才能导出

这些ip代理毕竟是免费的,经过预筛选还会出现失效的ip,这是需要二次删选,即让它去ping一个网站,如果能ping通,那就能用。如下代码测试,查看ip的丢包率
def check_ip(self):
cmd = "ping -n 3 -w 3 %s" # 命令 -n 要发送的回显请求数 -w 等待每次回复的超时时间(毫秒)
p = sp.Popen(cmd %self.ip, stdin=sp.PIPE, stdout=sp.PIPE, stderr=sp.PIPE, shell=True) # 执行命令
lose_time = re.compile(u"丢失 = (\d+)", re.IGNORECASE)
out = p.stdout.read().decode("gbk") # 获得返回结果并解码
#print (out)
lose_time = lose_time.findall(out) # 丢包数
# 当匹配到丢失包信息失败,默认为三次请求全部丢包,丢包数lose赋值为3
if len(lose_time) == 0:
print "----------------LOST IP PACKET---------------------"
return False
else:
lose = int(lose_time[0])
if lose > 1:
return False
else:
return True
代理ip还有一个缺点就是慢~,这也降低了爬虫的威胁,如果想高速爬取,只有两个字:充钱
3.2.3虚假访问延迟
爬虫就是因为方位速度过快或频率固定,容易被识别出,我们可以速度低于某个阀值,就可避免被Forbidden,即是403。目标服务器积极拒绝。
如果使用免费代理ip,那么这里依旧基本不需要了,因为免费代理的服务堪忧,而且加上测试筛选的时间,已经是在延迟访问了,想要设置不难,只要使用time函即可,以秒为单位。建议加载request函数之前,这样在延迟时,加上cpu处理数据的时间更加随机了。
time.sleep(1)
req = requests.get(url=url,headers=self.headers_Common, proxies=self.proxies, verify=False)
3.2.4绕开蜜罐
蜜罐就是用来吸引我们这些小虫子的,有一些信息使用浏览器是无法看到的,如果你的request请求附带了这些信息,或者你在访问浏览器看不到的信息,那么你就进入了蜜罐。
比如一些隐藏的字段,标签,或者超出浏览器分辨率的信息。
请求头headers中并不是所有信息都是有用的,相反加的过多就会无法访问你,这个需要反复的尝才行,例如我们获得当季推荐城市列表的请求头,有很多是不可以添加的

3.3存取技术
3.3.1Json文件存取
在持久化和半持久化数据方面本项目都为json存取,如爬取的ip,以及抓取的数据包,使用json有两个处,比如他拥有和字典相媲美的键值结构,而且很擅长处理中文字段。
req = requests.post().json()
data1 = json.dumps(req, ensure_ascii=False)
value = json.loads(data1)
3.3.2Sheet分组Excel储存
我这里选择Excel进行储存是为了让程序更倾向办公化,不需要处理安装笨重的数据库,反锁的sql语句,以及各种键值问题。Excel备受职场的青睐,还有诸多数据透视,排序,筛选功能。
Python对Excel的支持主要为openpyxl类库,以及子类库openpyxl.workbook,在本项目先构建Workbook对象,然后咋每个区域中构建Workbook的create_sheet对象,然后将数据逐行写到create_sheet中,create_sheet即是Excel下面的标签页。
Workbook仅在程序开始时被创建,中间过程仅操作Sheet,最后保存Workbook。


def __init__(self):
......
self.outwb = Workbook()
self.wo = self.outwb.active
def getSheet(self,name,site):
careerSheet = self.outwb.create_sheet(name,site)
careerSheet.append(['名称', '电话', '网址', '用时参考', '交通', '门票', '开放时间', '景点位置', '概况'])
return careerSheet
def getPoi(self):
... ...
sheet = 0
for Key,Value in self.gonglve_url.items():
careerSheet = self.getSheet(self.SheetName[sheet],sheet)
self.headers_Common['Referer'] = Key
for url in Value:
... ...
careerSheet.append([A,B,C,D,E,F,G,H,I])
sheet = sheet+1
3.3.3异常不中断爬取
单凡涉及数据请求及xpath寻找时都使用了大量try{}except{}语句,例如有的景点就没有主页的信息,有的不需要乘坐铁路,就没有铁路信息,以及我们从url列表中依次访问时,并不是所有url都能100%访问成功,或者突然间我们被Forbidden了,这几需要我们把已经取到的数据保存下来,而不是控制台报错,退出程序,抛出异常。
def getGonglveUrl(self):
for item in self.mdd_urlList:
... ...
try:
for div in soup.find('div',class_='row row-top5').find_all('div',class_='info'):
href = div.find('div',class_='middle').find('h3').find('a')['href']
list.append('http://www.mafengwo.cn'+href)
self.gonglve_url[item] = list
except:
print 'error'
需要大家自行调整路径问题,如包,Model的引用,Excel储存位置等,视个人情况而异。

4.原码连接
https://github.com/GuoHongYuan/MaFengWoCrawler