Python网络爬虫与信息提取——bs4
| Beautiful Soup库解析器 | ||
| 解析器 |
使用方法 | 条件 |
| bs4的HTML解析器 | BeautifulSoup(mk, 'html.parser') | 安装bs4库 |
| lxml的HTML解析器 |
BeautifulSoup(mk,'xml') | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,' xml') | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,' htm5lib') | pip install htm151ib |
Beautiful Soup的基本元素
| Beautiful Soup的基本元素 | |
| 基本元素 | 说明 |
| Tag | 标签,最基本的信息组织单元,分别用<>和标明开头和结尾 |
| Name | 标签的名字,<>....的名字是'p', 格式: |
| Attributes | 标签的属性,字典形式组织,格式: |
| NavigableString | 标签内非属性字符串,<>...中字符串, 格式: |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print soup.a #Basic Python
print soup.a.name #a
print soup.a.parent.name #p
print soup.a.attrs #{u'href': u'http://www.icourse163.org/course/BIT-268001', u'class': [u'py1'], u'id': u'link1'}
print soup.a.attrs['class'] #[u'py1']
print type(soup.a.attrs) #
print type(soup.a) #
print soup.a.string #Basic Python
print soup.p #The demo python introduces several python courses.
print soup.p.string #The demo python introduces several python courses. newsoup = BeautifulSoup("this is not a comment
", "html.parser")
print newsoup.b.string #this is a comment
print type(newsoup.b.string) #
print newsoup.p.string #this is not a comment
print type(newsoup.p.string) # Beautiful Soup的遍历方法
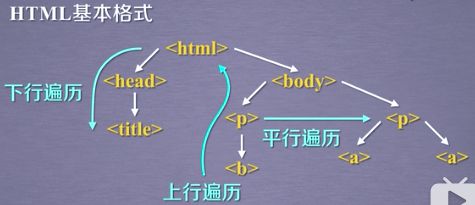
标签树的下行遍历
| 标签树的下行遍历 |
|
| 属性 | 说明 |
| .contents | 子节点的列表,将 |
| .children | 子节点的选代类型,与.contents类似, 用于循环遍历儿子节点 |
| .descendants | 子孙节点的选代类型,包含所有子孙节点,用于循环遍历 |
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
#down
print soup.head.contents #[This is a python demo page ]
print soup.body.contents #[u'\n', The demo python introduces several python courses.
, u'\n', Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\nBasic Python and Advanced Python.
, u'\n']
print len(soup.body.contents) #5
for child in soup.body.children: #遍历儿子节点
print child
for child in soup.body.descendants: #遍历子孙节点
print child
标签树的上行遍历
| 属性 | 说明 |
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
#up
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print soup.a.parent #Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Basic Python and Advanced Python.
for parent in soup.a.parents:
if parent is None:
print parent
else:
print parent.name
#p
#body
#html
#[document]
标签树的平行遍历(平行遍历发生在同一个父节点下的各节点间)
| 属性 | 说明 |
| .next_ sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一 个平行节点标签 |
| .next_ siblings | 选代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous siblings | 迭代类型,返回按照HTML文本顾序的前续所有平行节点标签 |
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print soup.a.next_sibling # and
print soup.a.next_sibling.next_sibling #Advanced Python
print soup.a.previous_sibling #Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
for sibling in soup.a.next_sibling: #遍历后序节点
print sibling
for sibling in soup.a.previous_sibling: #遍历前序节点
print sibling
基于bs4库html的格式化与编码
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print soup.prettify()
print soup.a.prettify()
三种信息标记形式的比较
| XML | 最早的通用信息标记语言,可扩展性好,但繁琐。 |
Internet 上的信息交互与传递。 |
| JSON |
信息有类型,适合程序处理(js),较XML简洁。 |
移动应用云端和节点的信息通信,无注释。 |
| YAML | 信息无类型,文本信息比例最高,可读性好。 |
移动应用云端和节点的信息通信,无注释。 |
信息提取的一般方法
方法一:完整解析信息的标记形式,再提取关键信息。
XML JSON YAML
需要标记解析器
例如: bs4库 的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐,速度慢。
方法二:无视标记形式,直接搜索关键信息。
搜索
对信息的文本查找函数即可。
优点:提取过程简洁,速度较快。
缺点:
提取结果准确性与信息内容相关。
| <> .find_ all(name, attrs, recursive, string,**kwargs) |
|
| 返回一个列表类型,存储查找的结果。 | |
| name | 对标签名称的检索字符串。 |
| attrs | 对标签属性值的检索字符串,可标注属性检索。 |
| recursive | 是否对子孙全部检索,默认True。 |
| string | <>...中字符串区域的检索字符串。 |
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
for link in soup.find_all('a'):
print link.get('href')
#http://www.icourse163.org/course/BIT-268001
#http://www.icourse163.org/course/BIT-1001870001
print soup.find_all(['a', 'b']) #[The demo python introduces several python courses., Basic Python, Advanced Python]
print soup.find_all(id='link1') #找出所有id为link1的字符串
print soup.find_all(True)
import re
soup.find_all(id=re.compile('link')) #找出所有id含有link的字符串
r = requests.get("https://www.python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print soup.find_all(string = 'Basic Python') #仅找出'Basic Python'字符串
print soup.find_all(string=re.compile('Python')) #找出含有Python的所有字符串
实例:中国大学排名定向爬虫
def gethtmltext(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print r.text
return r.text
except:
print "error"
return ""
def fillunivlist(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
print tr
tds = tr('td')
ulist.append([tds[0].string, tds[1].string])
def printunivlist(ulist, num):
print "{:^10}\t{:^6}\t{:^10}".format("排名", "学校", "总分")
for i in range(num):
u = ulist[i]
print "{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2])
def main():
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html'
html = gethtmltext(url)
fillunivlist(uinfo, html)
printunivlist(uinfo, 20)
if __name__ == "__main__":
main()