PaddlePaddle学习--recognize_digits 数字识别 逐行代码解析
百度 AIStudio 最详细教程 paddlepaddle 数字识别官网文档
自己学习 逐行代码解析
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Usage : recognize_digits
任务描述:使用paddlepaddle训练手写字识别模型
1、使用数据MNIST;
2、paddlepaddle平台;
3、时间 2周
验收:MNIST训练模型及其效果、CNN原理串讲
PaddlePaddle训练一次模型完整的过程可以如下几个步骤:
定义网络结构-->导入数据---->调用模型---->训练模型---->保存模型---->测试结果
Time : 2019/7/14 16:36
Author : feng
email : [email protected]
File : train.py
"""
# 将python3中的print特性导入当前版本
from __future__ import print_function
import os
# argparse 是python自带的命令行参数解析包,可以用来方便地读取命令行参数
import argparse
# PIL: Python Imaging Library,是Python平台的图像处理标准库
from PIL import Image
# NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
import numpy
# 导入paddle模块
import paddle
import paddle.fluid as fluid
# 可视化
from visualdl import LogWriter
def parse_args():
"""
:desc: 解析命令行参数
:return:返回参数列表
"""
parser = argparse.ArgumentParser("mnist")
# 是否连续评估日志
parser.add_argument('--enable_ce', action='store_true', help="if set,run the task with continuous evaluation logs.")
# 是否使用gpu
parser.add_argument('--use_gpu', type=bool, default=False, help="Whether to use GPU or not.")
# epochs数量
parser.add_argument('--num_epochs', type=int, default=5, help="number of epochs")
# batch size
parser.add_argument('--batch_size', type=int, default=64, help="size of batch")
args = parser.parse_args()
return args
def loss_net(hidden, label):
"""
:desc: 定义交叉熵代价损失函数,分类问题一般使用这个
:param hidden: 隐藏层
:param label: 标签
:return:
"""
# 预测函数,对输入全连接后激活输出
# input为输入,size为节点个数,cct激活函数为softmax
prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
# 交叉熵损失函数:使用预测值和实际标签计算损失
loss = fluid.layers.cross_entropy(input=prediction, label=label)
# 平均损失
avg_loss = fluid.layers.mean(loss)
# 使用预测值作为输入和标签计算准确率
acc = fluid.layers.accuracy(input=prediction, label=label)
return prediction, avg_loss, acc
def softmax_regression(img, label):
"""
:desc: softmax回归模型,对输入进行全连接方式获取特征,然后直接通过softmax函数计算多个类别的概率
所以img作为模型的输入,既是损失函数的输入
:param img: 输入层 图片
:param label: 标签
:return: 损失函数结果
"""
return loss_net(img, label)
def multilayer_perceptron(img, label):
"""
:desc: 多次感知模型,采用最简单的两层神经网络,只有输入和输出层,为了达到更好的拟合效果,在中间加两个隐藏层
:param img: 输入层图片
:param label: 图片标签
:return: 损失函数结果
"""
# 输入层+2个隐藏层
hidden1 = fluid.layers.fc(input=img, size=200, act='tanh')
hidden2 = fluid.layers.fc(input=hidden1, size=200, act='tanh')
return loss_net(hidden2, label)
def convolutional_neural_network(img, label):
"""
:desc: 卷积神经网络CNN,LeNet-5,输入的二维图像,先经过两次卷积层到池化层,再经过全连接,最后使用softmax函数分类最为输出
:param img: 输入图像
:param label: 图像标签
:return: 损失函数结果
"""
# 第1次卷积+池化
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img, # 输入图像的格式为【N,C,H,】
filter_size=5, # 滤波器大小(H,W)
num_filters=20, # 滤波器的数量,它与输出的通道相同
pool_size=2, # 池化层的大小(H,W)
pool_stride=2, # 池化层步长
act="relu") # 激活函数用rulu
# Batch Normalization批标准化,在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布。
conv_pool_1_bn = fluid.layers.batch_norm(conv_pool_1)
# 第2次卷积+池化
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1_bn,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act='relu')
return loss_net(conv_pool_2, label)
def train(args, nn_type, save_dirname=None, model_filename=None, params_filename=None):
"""
:desc: 训练函数
:param args: 命令行参数
:param nn_type: 训练用的模型类型
:param save_dirname:保存路径
:param model_filename:模型名称
:param params_filename:
:return:
"""
# 是否使用GPU,默认是False
if args.use_gpu and not fluid.core.is_compiled_with_cuda():
return
# 定义启动程序和主程序
startup_program = fluid.default_startup_program() # 此函数可以获取默认或全局startup program(启动程序)
main_program = fluid.default_main_program() # 此函数用于获取默认或全局main program(主程序)
# 定义train_reader和test_reader读取器
batch_size = args.batch_size
if args.enable_ce:
# paddle.batch()返回一个reader
# paddle.dataset.mnist.train()MNIST训练数据集的creator。
# 它返回一个reader creator, reader中的每个样本的图像像素范围是[-1,1],标签范围是[0,9]。
# 返回:训练数据的reader creator 返回类型:callable
# paddle.dataset.mnist.test() 返回:测试数据的reader creator
train_reader = paddle.batch(paddle.dataset.mnist.train(), batch_size=batch_size)
test_reader = paddle.batch(paddle.dataset.mnist.test(), batch_size=batch_size)
startup_program.random_seed = 90
main_program.random_seed = 90
# 非连续性评估
else:
# paddle.reader.shuffle(reader,buf_size) 读取buf_size大小的数据自动做shuffle,让数据打乱,随机化
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.train(), buf_size=500), batch_size=batch_size)
# 测试集就不用打乱了
test_reader = paddle.batch(
paddle.dataset.mnist.test(), batch_size=batch_size)
# 定义占位输入层和标签层
# 图像是28*28的灰度图,所以输入的形状是[1,28,28](灰度图是1通道,彩图3通道shape=[3, 28, 28]),
# 理论上应该还有一个维度是Batch,PaddlePaddle帮我们默认设置,可以不设置Batch
img = fluid.layers.data(name='img', shape=[1, 28, 28], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
# 根据参数选择使用的模型类型
if nn_type == 'softmax_regression':
net_conf = softmax_regression
elif nn_type == 'multilayer_perceptron':
net_conf = multilayer_perceptron
else:
net_conf = convolutional_neural_network
# 调用模型,返回预测值、损失函数和准确率
prediction, avg_loss, acc = net_conf(img, label)
# 定义优化器
# learning_rate (float|Variable)-学习率,用于更新参数
# Adam: (adaptive moment estimation)是对RMSProp优化器的更新.利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率.
# 优点:每一次迭代学习率都有一个明确的范围,使得参数变化很平稳.
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
# 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣,同时利用损失函数来提升算法模型.
# 这个提升的过程就叫做优化(Optimizer)
optimizer.minimize(avg_loss)
# 指明Executor的执行场所 cpu or gpu
place = fluid.CUDAPlace(0) if args.use_gpu else fluid.CPUPlace()
# 执行器,Executor 实现了一个简易的执行器,所有的操作在其中顺序执行。
exe = fluid.Executor(place)
# 仅运行一次startup program
# 不需要优化/编译这个startup program
exe.run(startup_program)
# DataFeeder 负责将reader(读取器)返回的数据转成一种特殊的数据结构,使它们可以输入到 Executor 和 ParallelExecutor 中。
# reader通常返回一个minibatch条目列表。在列表中每一条目都是一个样本(sample), 它是由具有一至多个特征的列表或元组组成的。
feeder = fluid.DataFeeder(feed_list=[img, label], place=place)
epochs = [epoch_id for epoch_id in range(args.num_epochs)]
# 定义测试程序
# Set for_test to True when we want to clone the program for testing.
test_program = main_program.clone(for_test=True)
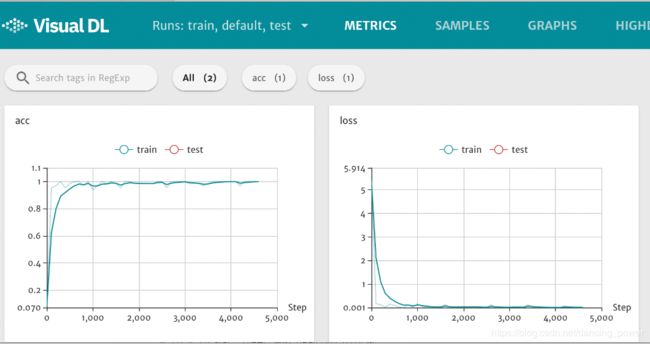
# 创建 LogWriter 对象
log_writer = LogWriter("./log", sync_cycle=20)
# 创建 scalar 组件,模式为 train
with log_writer.mode("train") as logger:
train_acc = logger.scalar("acc")
train_loss = logger.scalar("loss")
# 创建 scalar 组件,模式设为 test, tag 设为 acc
with log_writer.mode("test") as logger:
test_acc = logger.scalar("acc")
test_loss = logger.scalar("loss")
# 运行程序后,在命令行中执行
# visualdl --logdir ./log --host 0.0.0.0 --port 8080
# 接着在浏览器打开 http://0.0.0.0:8080,即可查看以下折线图。
# lists里元素为一个原组(epoch_id, avg_loss_val, acc_val)
lists = []
# 步长为100
step = 0
# 分epoch执行
print("开始分epoch训练...")
for epoch_id in epochs:
print("Epoch %d" % epoch_id)
for step_id, data in enumerate(train_reader()):
train_loss_v, train_acc_v = exe.run(main_program, feed=feeder.feed(data), fetch_list=[avg_loss, acc])
if step % 100 == 0:
print("Pass %d, Epoch %d, Cost %f, Acc:%f" % (step, epoch_id, train_loss_v[0], train_acc_v[0]))
# 向名称为 acc 的图中添加模式为train的数据
train_acc.add_record(step, train_acc_v[0])
# 向名称为 loss 的图中添加模式为train的数据
train_loss.add_record(step, train_loss_v[0])
step += 1
# 每一个epoch后测试
avg_loss_val, acc_val = train_test(exe, acc, avg_loss, train_test_program=test_program,
train_test_feed=feeder,
train_test_reader=test_reader)
print("Test with Epoch %d, avg_cost: %s, acc: %s" % (epoch_id, avg_loss_val, acc_val))
# 添加到list
lists.append((epoch_id, avg_loss_val, acc_val))
# 向名称为 acc 的图中添加模式为test的数据
test_acc.add_record(epoch_id, acc_val)
# 向名称为 loss 的图中添加模式为test的数据
test_loss.add_record(epoch_id, avg_loss_val)
# 保存每一个epoch模型
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname, ["img"], [prediction], exe,
model_filename=model_filename,
params_filename=params_filename)
if args.enable_ce:
print("kpis\ttrain_cost\t%f" % metrics[0])
print("kpis\train_cost\t%s" % avg_loss_val)
print("kpis\ttest_acc\t%s" % acc_val)
# 找到训练误差最小的一次结果
best = sorted(lists, key=lambda list: float(list[1]))[0]
print('Best pass is %s, testing Avgcost is %s' % (best[0], best[1]))
print('The classification accuracy is %.2f%%' % (float(best[2])*100))
def train_test(exe, acc, avg_loss, train_test_program, train_test_feed, train_test_reader):
"""
:desc:训练后用测试集测试
:param exe:
:param acc:
:param avg_loss:
:param train_test_program: 测试集训练程序
:param train_test_feed: 一种特殊的数据结构,使它们可以输入到 Executor
:param train_test_reader: 读取器
:return:
"""
acc_set = []
avg_loss_set = []
# exe是一个执行器,Executor可以接收传入的program,并根据feed map(输入映射表)和fetch_list(结果获取表)
# 向program中添加feed operators(数据输入算子)和fetch operators(结果获取算子)
# fetch_list提供program训练结束后用户预期的变量(或识别类场景中的命名)
for test_data in train_test_reader():
acc_np, avg_loss_np = exe.run(program=train_test_program,
feed=train_test_feed.feed(test_data),
fetch_list=[acc, avg_loss])
acc_set.append(float(acc_np))
avg_loss_set.append((float(avg_loss_np)))
# 计算 acc and loss 均值
acc_val_mean = numpy.array(acc_set).mean()
avg_loss_val_mean = numpy.array(avg_loss_set).mean()
return avg_loss_val_mean, acc_val_mean
def infer(args, save_dirname=None, model_filename=None, params_filename=None):
"""
:desc: 使用训练后的模型推断给定图像结果
:param args:
:param save_dirname: 模型存放地址
:param model_filename:
:param params_filename:
:return:
"""
# 如果找不到模型存放地址,就不用进行了
if save_dirname is None:
return
# 执行器
place = fluid.CUDAPlace(0) if args.use_gpu else fluid.CPUPlace()
exe = fluid.Executor(place)
# 加载图像
def load_image(file):
im = Image.open(file).convert('L')
im = im.resize((28, 28), Image.ANTIALIAS)
im = numpy.array(im).reshape(1, 1, 28, 28).astype(numpy.float32)
im = im / 255.0 * 2.0 - 1.0
return im
# 图片位置
cur_dir = os.path.dirname(os.path.realpath(__file__))
tensor_img = load_image(cur_dir + '/img/infer_3.png')
inference_scope = fluid.core.Scope()
# scope_guard 修改全局/默认作用域(scope), 运行时中的所有变量都将分配给新的scope
# load_inference_model 从指定目录中加载预测模型(inference model)。通过这个API,您可以获得模型结构(预测程序)和模型参数。
with fluid.scope_guard(inference_scope):
[inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(
save_dirname, exe, model_filename, params_filename)
results = exe.run(inference_program, feed={feed_target_names[0]: tensor_img}, fetch_list=fetch_targets)
# argsort函数返回的是数组值从小到大的索引值
lab = numpy.argsort(results)
# lab[0][0][-1]???
print("Inference result of image/infer_3.png is: %d" % lab[0][0][-1])
def main():
print("main函数开始")
# 获取命令行参数
args = parse_args()
print("参数args: %s" % args)
# 模型类型
# nn_type1 = 'softmax_regression'
# nn_type1 = 'multilayer_perceptron'
nn_type1 = 'convolutional_neural_network'
print("选用模型: %s" % nn_type1)
# 保存模型用到的变量
model_filename1 = None
params_filename1 = None
save_dirname1 = "recognize_digits_" + nn_type1 + ".inference.model"
print("开始训练模型...")
train(args, nn_type=nn_type1, save_dirname=save_dirname1, params_filename=params_filename1)
print("使用训练的模型,推断给定图像数字...")
infer(args, save_dirname=save_dirname1, model_filename=model_filename1, params_filename=params_filename1)
if __name__ == '__main__':
main()
测试图片:

训练输出:
开始分epoch训练...
Epoch 0
Pass 0, Epoch 0, Cost 5.376715, Acc:0.078125
Pass 100, Epoch 0, Cost 0.162992, Acc:0.953125
Pass 200, Epoch 0, Cost 0.121706, Acc:0.968750
Pass 300, Epoch 0, Cost 0.021870, Acc:1.000000
Pass 400, Epoch 0, Cost 0.141030, Acc:0.953125
Pass 500, Epoch 0, Cost 0.099030, Acc:0.984375
Pass 600, Epoch 0, Cost 0.025974, Acc:1.000000
Pass 700, Epoch 0, Cost 0.007782, Acc:1.000000
Pass 800, Epoch 0, Cost 0.114920, Acc:0.968750
Pass 900, Epoch 0, Cost 0.018453, Acc:1.000000
Test with Epoch 0, avg_cost: 0.06353178786684442, acc: 0.9811902866242038
Best pass is 0, testing Avgcost is 0.06353178786684442
The classification accuracy is 98.12%
Epoch 1
Pass 1000, Epoch 1, Cost 0.165972, Acc:0.937500
Pass 1100, Epoch 1, Cost 0.054720, Acc:0.968750
Pass 1200, Epoch 1, Cost 0.014743, Acc:1.000000
Pass 1300, Epoch 1, Cost 0.020369, Acc:0.984375
Pass 1400, Epoch 1, Cost 0.008707, Acc:1.000000
Pass 1500, Epoch 1, Cost 0.021007, Acc:0.984375
Pass 1600, Epoch 1, Cost 0.126579, Acc:0.953125
Pass 1700, Epoch 1, Cost 0.004719, Acc:1.000000
Pass 1800, Epoch 1, Cost 0.005161, Acc:1.000000
Test with Epoch 1, avg_cost: 0.039876993983771925, acc: 0.9871616242038217
Best pass is 1, testing Avgcost is 0.039876993983771925
The classification accuracy is 98.72%
Epoch 2
Pass 1900, Epoch 2, Cost 0.034053, Acc:0.984375
Pass 2000, Epoch 2, Cost 0.044924, Acc:0.984375
Pass 2100, Epoch 2, Cost 0.023464, Acc:0.984375
Pass 2200, Epoch 2, Cost 0.046066, Acc:0.984375
Pass 2300, Epoch 2, Cost 0.028819, Acc:0.984375
Pass 2400, Epoch 2, Cost 0.004922, Acc:1.000000
Pass 2500, Epoch 2, Cost 0.003063, Acc:1.000000
Pass 2600, Epoch 2, Cost 0.118440, Acc:0.953125
Pass 2700, Epoch 2, Cost 0.007253, Acc:1.000000
Pass 2800, Epoch 2, Cost 0.003940, Acc:1.000000
Test with Epoch 2, avg_cost: 0.027864804686067342, acc: 0.9905453821656051
Best pass is 2, testing Avgcost is 0.027864804686067342
The classification accuracy is 99.05%
Epoch 3
Pass 2900, Epoch 3, Cost 0.003744, Acc:1.000000
Pass 3000, Epoch 3, Cost 0.015700, Acc:1.000000
Pass 3100, Epoch 3, Cost 0.032559, Acc:0.984375
Pass 3200, Epoch 3, Cost 0.019687, Acc:0.984375
Pass 3300, Epoch 3, Cost 0.015848, Acc:0.984375
Pass 3400, Epoch 3, Cost 0.122988, Acc:0.968750
Pass 3500, Epoch 3, Cost 0.024033, Acc:0.984375
Pass 3600, Epoch 3, Cost 0.013739, Acc:1.000000
Pass 3700, Epoch 3, Cost 0.001703, Acc:1.000000
Test with Epoch 3, avg_cost: 0.026104776151899555, acc: 0.9905453821656051
Best pass is 3, testing Avgcost is 0.026104776151899555
The classification accuracy is 99.05%
Epoch 4
Pass 3800, Epoch 4, Cost 0.005494, Acc:1.000000
Pass 3900, Epoch 4, Cost 0.001251, Acc:1.000000
Pass 4000, Epoch 4, Cost 0.009453, Acc:1.000000
Pass 4100, Epoch 4, Cost 0.003899, Acc:1.000000
Pass 4200, Epoch 4, Cost 0.066883, Acc:0.968750
Pass 4300, Epoch 4, Cost 0.017166, Acc:1.000000
Pass 4400, Epoch 4, Cost 0.004706, Acc:1.000000
Pass 4500, Epoch 4, Cost 0.007804, Acc:1.000000
Pass 4600, Epoch 4, Cost 0.008806, Acc:1.000000
Test with Epoch 4, avg_cost: 0.014653858707311987, acc: 0.9952229299363057
Best pass is 4, testing Avgcost is 0.014653858707311987
The classification accuracy is 99.52%
使用训练的模型,推断给定图像数字...
Inference result of image/infer_3.png is: 3Visualdl 可视化损失函数 loss和准确率acc