Google News Personalization: Scalable Online Collaborative Filtering里 LSH详解
从文档相似度计算看LSH(Locality Sensitive Hashing)
Minhash
衡量两个用户之间的相似度可以用他们的交集来表示,也被称为Jaccard 相似度
用户uj看过的新闻对于用户ui来说有s(ui,uj)的吸引力。在计算的时候,可以使用LSH来缩减数据规模,其中LSH的思想就是相近的数据在哈希过程中更有可能产生冲突,具体解释如下:
我们来看一个寻找相似文档问题,给你一个文档库,寻找其中相似的文档(仅仅是内容上相似,语义层次的可以考虑隐式语义(LSA))。寻找相似文档可以分为三个步骤:
Shingling:将文档转化为一些集合。类似于中文分词。
Minhashing:在保留文档之间相似度的同时,将上一步得到庞大数据,转化为短些的签名(signatures)。将对集合的比较转化为签名的比较。
Locality-sensitive hashing:得到的签名集还是很大,通过LSH进一步缩减处理的数据量。只是比较存在很高概率相似的一些签名。

上面这个图是处理流程。每一步的输出分部是:字符串集,签名集合候选对。下面看看每一步的详细过程,因为MinHash非常有趣。
Shingling是按一个指定长度k,将文档分割为字符串集。我们将其称为k -shingle或者k -gram。举个例子k=2,doc = abcab,那么2-shingles = {ab, bc, ca}。字符串集也可以称为词袋。在这个例子里面,ab出现了2次,在这里我们不考虑权重,并不考虑一个字符串出现的次数。k的选取比较重要,如果太小,数据量很大,过大的话,匹配效果不好。
到此,第一步完成,我们得到了每个文档的字符串集合。要判断文档相似,就等价于判断集合的相似度。集合相似的一个重要办法就是Jaccard相似度。
Sim (C1, C2) = |C与C2|/|C1或C2|
我们将集合转化为一个矩阵来进行处理:矩阵的行是每个字符串,矩阵的列是每一个文档。所有的矩阵行就构成了所有文档字符串集合的一个并集,是集合空间。如果文档x里面有字符串y,那么(x,y) = 1,否则(x,y) = 0。现在得到了一个布尔矩阵。

如上图所示,Sim (C1, C2) = 2/5 = 0.4。需要注意的是:我们完全可以不采用0/1,二是字符串出现的次数来定义矩阵,另一个是这个矩阵是稀疏的,并且非常庞大。
现在进行第二步:签名。给每个列,即每个文档个一个签名。这个签名应该满足2个性质:
一是它要足够小,才能减少存储空间,减少计算代价。
二是它保持了相似度,也就是签名的相似度与现在列之间的相似度是一样的。Sim (C1, C2) =Sim (Sig(C1), Sig(C2))。
Minhashing首先假设,行是随机排列的,然后定义一个哈希函数h(C),哈希函数的值是列C在前面定义的随机排列中,第一个为值1行。后面给个例子就明白了。然后使用一定数量的相互独立的哈希函数来构成签名。

图中间是得到的布尔矩阵,左边是三个随机的行的排列。其中的值是行的编号。我们用行的排列数,在矩阵中找最先出现1的行。对于排列数1376254,在矩阵第一列中为1的有1354,然后取最小的1;在矩阵第二列中为1的有762,取最小的2;在矩阵第三列中为1的有154,取最小的1;在矩阵第四列中为1的有3762,取最小的2。这就得到了签名矩阵的第三行。同样的方法可以得到签名矩阵的第一行和第二行。
现在我们在布尔矩阵中计算第一列和第二列的Jaccard相似度:Sim (C1, C2) = 0/6 = 0,在签名矩阵中计算第一列和第二列的Jaccard相似度:Sim (C1, C2) = 0/3 = 0。在布尔矩阵中计算第二列和第四列的Jaccard相似度:Sim (C1, C2) = 3/4 = 0.75,在签名矩阵中计算第二列和第四列的Jaccard相似度:Sim (C1, C2) = 3/3 = 1。差别不是很大。事实上,如果将行的所有排列都拿来计算签名,那么h (C1) = h (C2) 的概率等于Sim (C1, C2)。签名的相似度等于列的相似度。谁帮忙证明一下?
如果将所有的行的排列数都拿来做签名,那不是又回到原来的规模了么?还有计算排列数的开销?的确,但是可以发现随着排列数的增加,签名相似度与行的相似度之间的误差越来越小,选择合适的排列数目就可以满足应用需求,通常我们取100个排列数。
计算排列数也是个不小的开销,我们可以用哈希函数近似处理。下面是一个参考算法:
for each row r
for each column c
if c has 1 in row r
for each hash function hi do
if hi (r ) is a smaller value than M (i, c ) then
M (i, c ) := hi (r );最后一步就是LSH。得到的签名数量还是很大,在在线实时应用中,不可能去一一比较。LSH筛选出有极高相似概率的候选对,进而减少比较的次数。LSH要寻找一个哈希函数f(x,y),它能够返回x,y是否是一个候选对。由于我们得到了签名矩阵,LSH就是将候选的列放到相同的Bucket中。
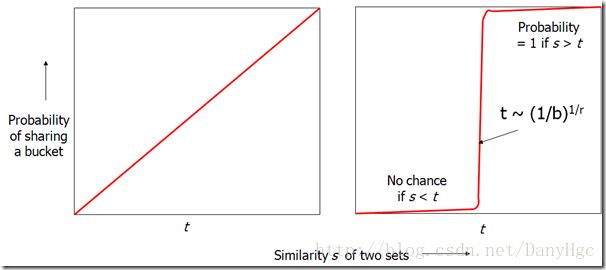
LSH选择一个相似度阀值s,如果两个列的签名相符度至少是s,那么就将它们放到同一个Bucket中。原理就这样简单,但是不是太粗糙了呢?
我们将矩阵的行分成b个Band(r行为一个Band):
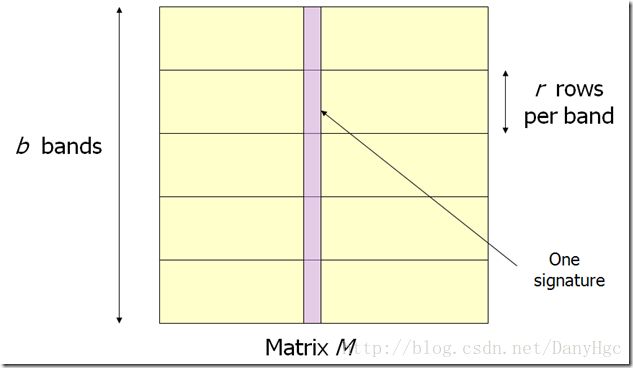
让后对每个Band做哈希,将她分区的列的一部分哈希到k个Bucket中。现在的候选对就是至少在1个Band中被哈希到同一个Bucket的列。分割之后的工作就是,调制参数b和r使尽可能可多的相似的对放到同一个Bucket,并且尽量减少不相似的对放到同一个Bucket中。

分割Band的目的是要得到很好的区分度效果。