Hadoop 相关知识点(一)
作业提交流程(MR执行过程)
Mapreduce2.x
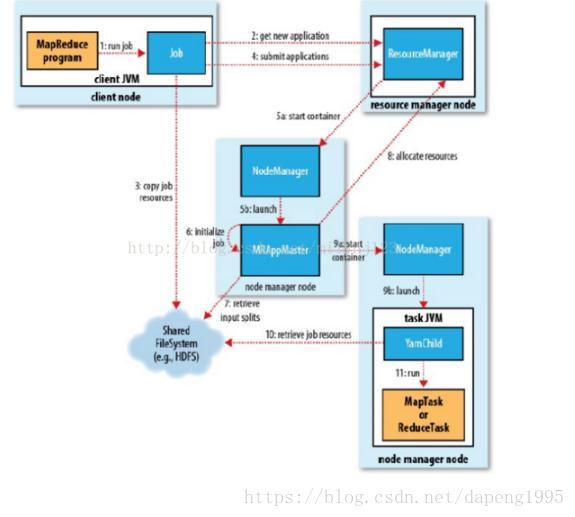
Client:用来提交作业
ResourceManager:协调集群上的计算资源的分配
NodeManager:负责启动和监控集群上的计算容器(container)
ApplicationMaster:协调运行MapReduce任务,他和应用程序任务运行在container中,这些congtainer有RM分配并且由NM进行管理
主要过程分析:
【作业的提交】
1. Job的submit()方法创建一个内部的Jobsubmiter实例,并且调用它的submitJobInternal()方法。(图中的第一步)
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
} 2.提交作业以后,waitForCompletion()每秒轮询作业的进度,如果发现自上次报告有所改变,便把进度报告提交到控制台
/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* JobTracker is lost
*/
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}3.JobSubmiter实现的作业提交流程:
首先,会向RM请求一个新的应用ID,用以MapReduce的作业ID(图中的步骤2),
接着检查作业的输出说明(例如:如果作业没有指定输出目录或者输出目录已经存在,作业人就不会提交,错误就会抛回给MapReduce)。
再接着,就是计算作业的输入分片。如果分片无法计算,例如输入分片不存在的话,作业就不会提交,错误就会抛回给MapReduce。
然后,讲作业所需要的资源(作业JAR文件,配置文件,计算所得的输入分片)复制到一个以作业ID命名的共享文件系统中(HDFS)。(对应步骤3)
再然后,调用资源的submitApplication()方法提交作业(步骤4)
protected void submitApplication(
ApplicationSubmissionContext submissionContext, long submitTime,
String user) throws YarnException {
//获得作业ID
ApplicationId applicationId = submissionContext.getApplicationId();
//构建一个app并放入applicationACLS
RMAppImpl application =
createAndPopulateNewRMApp(submissionContext, submitTime, user, false);
ApplicationId appId = submissionContext.getApplicationId();
if (UserGroupInformation.isSecurityEnabled()) {
try {
this.rmContext.getDelegationTokenRenewer().addApplicationAsync(appId,
parseCredentials(submissionContext),
submissionContext.getCancelTokensWhenComplete(),
application.getUser());
} catch (Exception e) {
LOG.warn("Unable to parse credentials.", e);
// Sending APP_REJECTED is fine, since we assume that the
// RMApp is in NEW state and thus we haven't yet informed the
// scheduler about the existence of the application
assert application.getState() == RMAppState.NEW;
this.rmContext.getDispatcher().getEventHandler()
.handle(new RMAppEvent(applicationId,
RMAppEventType.APP_REJECTED, e.getMessage()));
throw RPCUtil.getRemoteException(e);
}
} else {
// Dispatcher is not yet started at this time, so these START events
// enqueued should be guaranteed to be first processed when dispatcher
// gets started.
//触发app启动事件
this.rmContext.getDispatcher().getEventHandler()
.handle(new RMAppEvent(applicationId, RMAppEventType.START));
}
}【作业的初始化】
4.RM收到了调用它的submitApplication()消息后,就会将请求传递给YARN调度器,调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动 application Master的进程(步骤5a、5b),MapReduce的application Master是一个Java应用程序,它的主类是MRAppMaster。它将接受来自任务的进度和完成报告(步骤6),接下来,他将会接受来自共享文件系统的jar文件和计算好的分片信息(步骤7) , 然后对每一个分片创建一个map任务对象以及由mapreduce.job.recuces(通过作业的 setNumReduceTasks()方法设置)确定多个reduce任务对象。任务ID在此时分配。
application Master 必须确定如何构成MapReduce 的各个任务。如果作业很小,就选择和自己在同一个JVM上运行任务,与在同一个节点上运行任务相比,application Master判断在新的容器中分配和运行任务的开销运行他们的开销时,这样的任务称作为uberized,或者作为uber任务运行(小作业–少于10个map任务且只有一个reducer且输出大小小于一个HDFS块的作业)。
【作业的分配】
5、如果作业不适合作为uber任务运行,这个时候application Master就会为改作业的所有map任务和reduce任务向资源管理器请求资源容器(步骤8),这个请求也为指定了内存需求和CPU数。
【任务的执行】
6、一旦资源管理器的调度器分配了一个特定节点上的容器,application Master就会通过与节点管理器的通信来启动容器(步骤9a 、9b),就是相当于启动了任务,这个任务是由主类为YarnChild的一个java应用程序执行。在运行任务之前,要先将资源本地化,包括作业的配置,jar和所有来自分布式缓存的文件(10)。最后运行map任务或者reduce任务(11)。任务完成后,MRAppMaster进程会向ResourceManager 注销本次任务,代表任务完成,Yarn可以回收本次分配的全部资源,MRAppMaster进程也会结束。
hdfs的基本原理
简介: Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS体系结构中有两类节点,一类是NameNode,又叫”元数据节点”;另一类是DataNode,又叫”数据节点”。这两类节点分别承担Master和Worker具体任务的执行节点。总的设计思想:分而治之——将大文件、大批量文件,分布式存放在大量独立的服务器上,以便于采取分而治之的方式对海量数据进行运算分析。
原理:
1 分布式文件系统,它所管理的文件是被切块存储在若干台datanode服务器上。
2 hdfs提供了一个统一的目录树来定位hdfs中的文件,客户端访问文件时只要指定目录树的路径即可,不用关心文件的具体物理位置。
3 每一个文件的每一个切块,在hdfs集群中都可以保存多个备份(默认3份),在hdfs-site.xml中,dfs.replication的value的数量就是备份的数量。(副本放置:首先第一个放在运行客户端的节点上,其次第二个放在与第一个不同且随机另外选择的机架中的一个节点、 第三个放在与第二个副本同一机架且是随机另外选择的节点上)
4 hdfs中有一个关键进程服务进程:namenode,它维护了一个hdfs的目录树及hdfs目录结构与文件真实存储位置的映射关系(元数据).而datanode服务进程专门负责接收和管理"文件块"-block,默认大小为128M(可配置),(dfs.blocksize),(老版本的hadoop的默认block是64M的)。
hadoop的shuffle过程:

shuffle的过程
简单的概括:map()输出结果->内存(环形缓冲区,当内存大小达到指定数值,如80%,开始溢写到本地磁盘)
溢写之前,进行了分区partition操作,分区的目的在于数据的reduce指向,分区后进行二次排序,第一次是对partitions进行排序,第二次对各个partition中的数据进行排序,之后如果设置了combine,就会执行类似reduce的合并操作,还可以再进行压缩,因为reduce在拷贝文件时消耗的资源与文件大小成正比
内存在达到一定比例时,开始溢写到磁盘上
当文件数据达到一定大小时,本地磁盘上会有很多溢写文件,需要再进行合并merge成一个文件
reduce拷贝copy这些文件,然后进行归并排序(再次merge),合并为一个文件作为reduce的输入数据
Job Tracker:是Map-reduce框架的中心,他需要与集群中的机器定时通信heartbeat,需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
TaskTracker是Map-Reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
PS:Hadoop的shuffle过程就是从map端输出到reduce端输入之间的过程,这一段应该是Hadoop中最核心的部分,因为涉及到Hadoop中最珍贵的网络资源,所以shuffle过程中会有很多可以调节的参数,也有很多策略可以研究,这方面可以看看大神董西成的相关文章或他写的MapReduce相关书籍。
Shuffle过程浅析
2.1 Map端
(1)在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生
总结:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。
(2)写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行 排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
(3)最后将磁盘中的数据送到Reduce中。
补充:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!关于如何使用压缩,在本文第三部分会有介绍。
2.2 Reduce端
(1)Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从 JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从 JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
(2)Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,(如果指定combiner,则在合并期间运行它,会降低写入磁盘的数据量)然后后台线程会将他们合并成更大的、排好序的文件。复制完所有的map输出后,reduce端进入排序阶段(更恰当的说法是进入合并阶段,因为排序是在map端进行的),这个阶段将会合并map端输出,维持其排序顺序。
(3)Reducer的参数:最后将合并后的结果作为输入传入Reduce程序任务中。
总结:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。
参考文章
http://langyu.iteye.com/blog/992916
https://blog.csdn.net/clerk0324/article/details/52461135