这是一个跨平台的播放器ijkplayer,iOS上集成看【如何快速的开发一个完整的iOS直播app】(原理篇)。
为了学习ijkplayer的代码,最好的还是使用workspace来集成,关于worksapce我有一篇简单介绍iOS使用Workspace来管理多项目。这样可以点击函数名查看源码,也可以设置断点,修改源码测试等等。
主架构

每个类型的数据流构建各自的packet和frame缓冲区,读取packet后根据类型分到不同的流程里。在最后显示的时候,根据pts同步音视频播放。
prepareToPlay
使用ijkPlayer只需两部:用url构建IJKFFMoviePlayerController对象,然后调用它的prepareToPlay。因为init时构建的一些东西得到使用的时候才明白它们的意义,所以先从prepareToPlay开始看。

上图是调用栈的流程,最终起关键作用的就是read_thread和video_refresh_thread这两个函数。
-
read_thread负责解析URL,把数据拿到 -
video_refresh_thread负责把内容显示出来 - 中间步骤在
read_thread运行后逐渐开启
上述两个方法都是在新的线程里运行的,使用了
SDL_CreateThreadEx这个方法,它开启一个新的pthread,在里面运行指定的方法。
解码部分
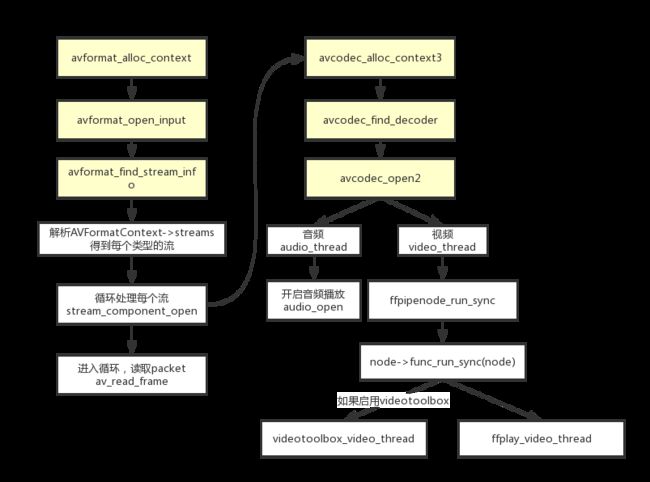
- 淡黄色背景的是ffmpeg库的函数,这几个是解码流程必须的函数。
- 先获取分析流,对每个类型流开启解码器。
stream_component_open函数这里做了一点封装。 - 读取packet之后,根据packet类型分到不同的packetQueue里面去:
if (pkt->stream_index == is->audio_stream && pkt_in_play_range) { packet_queue_put(&is->audioq, pkt); } else if (pkt->stream_index == is->video_stream && pkt_in_play_range && !(is->video_st && (is->video_st->disposition & AV_DISPOSITION_ATTACHED_PIC))) { packet_queue_put(&is->videoq, pkt); } else if (pkt->stream_index == is->subtitle_stream && pkt_in_play_range) { packet_queue_put(&is->subtitleq, pkt); } else { av_packet_unref(pkt); }packet_queue_put是ijkplayer封装的一个缓冲区PacketQueue的
的入队方法。PacketQueue是采用链表构建的循环队列,每个节点循环使用,一部分节点空闲,一部分使用中。就像一队卡车来回运货,有些车是空的,有些是装满货的,循环使用。 -
video_thread和audio_thread的作用把packet缓冲区里的packet解码成frame,装入frame缓冲区。 -
video_thread那里有个大坑,就是执行到node->func_run_sync(node)之后就是函数指针,要绕一大圈才能找到真正的函数。因为解码涉及到平台不同,iOS里还有VideoToolbox的解码,所以这里做了个解耦处理。-
node->func_run_sync(node)的node来源于ffp->node_vdec -
ffp->node_vdec来源于pipeline->func_open_video_decoder(pipeline, ffp) - 而
pipeline来源于最开始init播放器的时候的_mediaPlayer = ijkmp_ios_create(media_player_msg_loop);安卓平台可能就不是这个函数了。也就是pipeline从播放器初始化的时候就不一样了,然后node就不同了,node的func_run_sync也跟着不同了。 - iOS里面做了VideoToolbox和ffmpeg解码的区分。
-
解码packet得到frame并入队frameQueue

-
get_video_frame实际调用decoder_decode_frame,而这个函数在其他流解码时也是走这个。 -
decoder_decode_frame调用packetQueue的方法获取最早的packet,然后调用各自的解码函数得到frame - packetQueue里面是空的时候,如果立马返回,然后又来一次循环,很可能循环了N多次还没有得到新的packet。视频帧率一般好的也就60帧,一秒60次,而
get_video_frame这种while循环一秒能几次?这里如果不阻塞线程等待新的packet入队,会占用大量cpu。 -
queue_picture把得到的frame加入到frameQueue里面去。
这里不仅仅是做了入队处理,还把AVFrame转化成了一个自定义类型SDL_VoutOverlay:
当关系到播放的时候,又回到了上层,所以这里又要做平台适配问题。struct SDL_VoutOverlay { int w; /**< Read-only */ int h; /**< Read-only */ Uint32 format; /**< Read-only */ int planes; /**< Read-only */ Uint16 *pitches; /**< in bytes, Read-only */ Uint8 **pixels; /**< Read-write */ int is_private; int sar_num; int sar_den; SDL_Class *opaque_class; SDL_VoutOverlay_Opaque *opaque; void (*free_l)(SDL_VoutOverlay *overlay); int (*lock)(SDL_VoutOverlay *overlay); int (*unlock)(SDL_VoutOverlay *overlay); void (*unref)(SDL_VoutOverlay *overlay); int (*func_fill_frame)(SDL_VoutOverlay *overlay, const AVFrame *frame); };SDL_VoutOverlay在我的理解里,更像是一个中间件,把AVFrame里面的视频信息都转化到这个中间件里,不管之后你用什么方式去播放,不必对AVFrame造成依赖。这样将播放功能和解码功能接触联系了。我发现在c编程里,函数指针几乎起着protocol+delegate/interface的作用。
到这,数据流开启了,packet得到了,frame得到了。read_thread的任务结束了。然后就是把frame显示出来的事了。
显示部分
- 视频的显示函数是
video_refresh_thread,在第一张图里 - 音频的播放函数是
audio_open,在第二张图里,这时是已经解析到了音频流并且获得了音频的格式后。这么做,我的理解是:音频和视频不同,视频播放最终都是要转成rgb,得到样显示的时候再转;而音频采样率、格式、数这些可以设置成和源数据一样,就不需要转换了,所以需要先获取了音频源数据的格式,再开启音频播放。
视频播放
video_refresh_thread

video_refresh_thread就是不断的显示下一帧,如果距离下一帧还有时间,就用av_usleep先暂停会。-
video_refresh内部:- 先获取最早的frame,计算和下一帧的时间(vp_duration)
- 红色部分就是重点,用来处理音视频同步的。根据同步的方式,获取修正过后的下一帧时间。
- 如果时间没到直接跳过退出
video_refresh,进入av_usleep暂停下。代码里有点坑的是,这里写的是goto display;,而display代码块需要is->force_refresh这个为true才真的起作用,所以实际上是结束了,看起来有些误导。 - 确定要显示下一帧之后,才调用
frame_queue_next把下一帧推到队列关键位,即索引rindex指定的位置。 -
video_display2最终到了SDL_Vout的display_overlay函数。和前面一样,到了显示层,在这做了解耦处理,SDL_Vout对象是ffp->vout,也是在IJKFFMoviePlayerControllerinit里构建的。
对iOS,
SDL_Vout的display_overlay最终到了IJKSDLGLView的- (void)display: (SDL_VoutOverlay *) overlay函数。下面的内容就是在iOS里如何用OpenGLES显示视频的问题了。可以看看用OpenGLES实现yuv420p视频播放界面, ijkplayer里的显示代码有点复杂,貌似是为了把OpenGL ES部分再拆分出来做多平台共用。
音频播放
音频和视频的逻辑不一样,视频是搭建好播放层(OpenGLES的view等)后,把一帧帧的数据 主动 推过去,而音频是开启了音频队列后,音频队列会过来跟你要数据,解码层这边是 被动 的把数据装载进去。
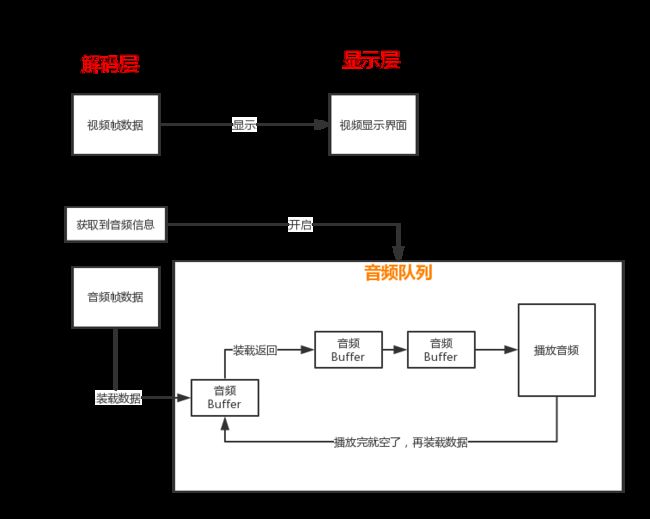
- 音频Buffer就像卡车一样,用完了,就再回来装载音频数据,然后回去再播放。如此循环。
- 音频有两部分:1. 开启音频,这部分函数是
audio_open2. 装载音频数据,这部分函数是sdl_audio_callback。 - 不管开启音频还是填充音频buffer,都做了解耦处理,音频队列的部分是iOS里的AudioQueue的运行逻辑。
audio_open
必须先说几个结构体,它们是连接界面层和显示层的纽带。
- SDL_Aout
typedef struct SDL_Aout_Opaque SDL_Aout_Opaque;
typedef struct SDL_Aout SDL_Aout;
struct SDL_Aout {
SDL_mutex *mutex;
double minimal_latency_seconds;
SDL_Class *opaque_class;
SDL_Aout_Opaque *opaque;
void (*free_l)(SDL_Aout *vout);
int (*open_audio)(SDL_Aout *aout, const SDL_AudioSpec *desired, SDL_AudioSpec *obtained);
......
一些操作函数,开始、暂停、结束等
};
SDL_Aout_Opaque在这(通用模块)只是typedef重定义了下,并没有实际的结构,实际定义根据各平台而不同,这也是解耦的手段之一。open_audio之后它的值才设置,在iOS里:
struct SDL_Aout_Opaque {
IJKSDLAudioQueueController *aoutController;
};
.....
//aout_open_audio函数里
opaque->aoutController = [[IJKSDLAudioQueueController alloc] initWithAudioSpec:desired];
这个值用来存储IJKSDLAudioQueueController对象,是负责音频播放的音频队列的控制器。这样,一个重要的连接元素就被合理的隐藏起来了,对解码层来说不用关系它具体是谁,因为使用它的操作也是函数指针,实际被调用的函数平台各异,到时这个函数内部就可以使用SDL_Aout_Opaque的真身了。
- SDL_AudioSpec
typedef struct SDL_AudioSpec
{
int freq; /**采样率 */
SDL_AudioFormat format; /**音频格式*/
Uint8 channels; /**声道 */
Uint8 silence; /**空白声音,没数据时用来播放 */
Uint16 samples; /**一个音频buffer的样本数,对齐成2的n次方,用来做音视频同步处理 */
Uint16 padding; /**< NOT USED. Necessary for some compile environments */
Uint32 size; /**< 一个音频buffer的大小*/
SDL_AudioCallback callback;
void *userdata;
} SDL_AudioSpec;
- 这个结构体基本就是对音频格式的描述,拿到了我们要播放的音频格式,显示层可能可以播也可能不能播,所以需要沟通一下:把源音频格式传给显示层,然后显示层根据自身情况返回一个两者都接受的格式回来。所以也就需要一个用于描述音频格式的通用结构,
SDL_AudioSpec就出来了。 - 音频3大样:采样率(freq)、格式(format)、声道(channels)。格式是自定义复合类型,这个后面使用到的时候再说。
- samples 这个其实是用来做音视频频同步的,因为音频队列的这种架构,填充音频Buffer的时候,音频还没有播放,而解码层只接触到填充任务,所以它得不到正确的播放时间和音频pts的差值。有了一个音频Buffer的样本数,除以采样率就是一个音频Buffer的播放时间,就可以估算正在装载的音频Buffer在未来的播放时间。音视频同步的问题以后单独说,比较复杂(如果我能都摸清楚的话-_-)。
- callback 这个是填充音频Buffer的回调方法,前面说填充任务是被动的,所以显示层得知道如何告诉解码层要填充音频数据了,这个callback就负担着这个任务。显示层一个音频Buffer空了,就只管调用这个callback就好了。
IJKSDLAudioQueueController
再说audio_open,它实际调用了SDL_Aout的open_audio函数,在iOS里,最终到了ijksdl_aout_ios_audiounit.m文件的aout_open_audio,关键就是这句:
opaque->aoutController = [[IJKSDLAudioQueueController alloc] initWithAudioSpec:desired];
重点转到IJKSDLAudioQueueController这个类。如果对上图里audioQueue的处理逻辑理解了,就比较好办。
-
AudioQueueNewOutput 构建一个用于播放音频的audioQueue
extern OSStatus AudioQueueNewOutput( const AudioStreamBasicDescription *inFormat, AudioQueueOutputCallback inCallbackProc, void * __nullable inUserData, CFRunLoopRef __nullable inCallbackRunLoop, CFStringRef __nullable inCallbackRunLoopMode, UInt32 inFlags, AudioQueueRef __nullable * __nonnull outAQ)- inCallbackProc 这个就是用来指定audioQueue需要装载AudioBuffer的时候的回调函数。
- inUserData 就是传给回调函数的参数,这种东西比较常见。
- inCallbackRunLoop 和inCallbackRunLoopMode就是回调函数触发的runloop和mode。
- inFlags无意义保留位置。
- AudioQueueRef 就是新构建的audioQueue
- AudioStreamBasicDescription是音频格式的描述,这个就是前面说的
SDL_AudioSpec对应的东西,需要根据传入的SDL_AudioSpec生成AudioQueue的格式:
extern void IJKSDLGetAudioStreamBasicDescriptionFromSpec(const SDL_AudioSpec *spec, AudioStreamBasicDescription *desc) { desc->mSampleRate = spec->freq; desc->mFormatID = kAudioFormatLinearPCM; desc->mFormatFlags = kLinearPCMFormatFlagIsPacked; desc->mChannelsPerFrame = spec->channels; desc->mFramesPerPacket = 1; desc->mBitsPerChannel = SDL_AUDIO_BITSIZE(spec->format); if (SDL_AUDIO_ISBIGENDIAN(spec->format)) desc->mFormatFlags |= kLinearPCMFormatFlagIsBigEndian; if (SDL_AUDIO_ISFLOAT(spec->format)) desc->mFormatFlags |= kLinearPCMFormatFlagIsFloat; if (SDL_AUDIO_ISSIGNED(spec->format)) desc->mFormatFlags |= kLinearPCMFormatFlagIsSignedInteger; desc->mBytesPerFrame = desc->mBitsPerChannel * desc->mChannelsPerFrame / 8; desc->mBytesPerPacket = desc->mBytesPerFrame * desc->mFramesPerPacket; }格式是默认的kAudioFormatLinearPCM,但是采样率(mSampleRate)和声道(mChannelsPerFrame)是直接从
SDL_AudioSpec拷贝过来。mFormatFlags比较复杂,有许多参数需要设置,比如是否有符号数:#define SDL_AUDIO_MASK_SIGNED (1<<15) #define SDL_AUDIO_ISSIGNED(x) (x & SDL_AUDIO_MASK_SIGNED)就是在
spec->format的第16位上保存这个标识,使用&的方式取出来。使用标识位的方式,把多个信息存在一个值里面,其实在枚举里面也是这个手段。位运算和枚举这里有我对枚举的一点认识。SDL_AUDIO_BITSIZE是计算这个音频格式下单个样本的大小,注意单位是比特,这个宏也就是把spec->format最低的8位取了出来,在之前构建spec->format的时候这个值就被存进去了。默认是使用s16也就是“有符号16比特”的格式,定义是这样的:
#define AUDIO_S16LSB 0x8010 /**< Signed 16-bit samples */,16位上是1,所以是有符号,低8位是0x10,也就是16。这只是ijkplayer自定义的一种复合类型,或说传递手段,并不是一种标准。 AudioQueueStart 开启audioQueue没啥好说的
-
分配几个AudioBuffer
for (int i = 0;i < kIJKAudioQueueNumberBuffers; i++) { AudioQueueAllocateBuffer(audioQueueRef, _spec.size, &_audioQueueBufferRefArray[i]); _audioQueueBufferRefArray[i]->mAudioDataByteSize = _spec.size; memset(_audioQueueBufferRefArray[i]->mAudioData, 0, _spec.size); AudioQueueEnqueueBuffer(audioQueueRef, _audioQueueBufferRefArray[i], 0, NULL); }这里的重点是size的问题,AudioBuffer该多大?假如你希望1s装载m次AudioBuffer,那么1s装载的音频数据就是m x AudioBuffer.size。而音频播放1s需要多少数据?有个公式:1s数据大小 = 采样率 x 声道数 x 每个样本大小。所以AudioBuffer.size = (采样率 x 声道数 x 每个样本大小)/ m。再看ijkplayer里求
_spec.size的代码//2 << av_log2这么搞一下是为了对齐成2的n次方吧。 wanted_spec.samples = FFMAX(SDL_AUDIO_MIN_BUFFER_SIZE, 2 << av_log2(wanted_spec.freq / SDL_AoutGetAudioPerSecondCallBacks(ffp->aout))); ..... void SDL_CalculateAudioSpec(SDL_AudioSpec * spec) { ..... spec->size = SDL_AUDIO_BITSIZE(spec->format) / 8; spec->size *= spec->channels; spec->size *= spec->samples; }spec->samples是单个AudioBuffer的样本数,而不是采样率,注意除以了SDL_AoutGetAudioPerSecondCallBacks,这个就是1s中装载AudioBuffer的次数。 -
装载回调
IJKSDLAudioQueueOuptutCallback和装载之后AudioQueueEnqueueBufferstatic void IJKSDLAudioQueueOuptutCallback(void * inUserData, AudioQueueRef inAQ, AudioQueueBufferRef inBuffer) { @autoreleasepool { .... (*aqController.spec.callback)(aqController.spec.userdata, inBuffer->mAudioData, inBuffer->mAudioDataByteSize); AudioQueueEnqueueBuffer(inAQ, inBuffer, 0, NULL); } }在这里接力,调用
spec.callback,从这又回到解码层,那边把AudioBuffer装满,AudioQueueEnqueueBuffer在把AudioBuffer推给AudioQueue入队播放。
sdl_audio_callback填充AudioBuffer
整体逻辑是:循环获取音频的AVFrame,填充AudioBuffer。比较麻烦的两个点是:
- 装载AudioBuffer的时候,装满了但是音频帧数据还省一点的,这一点不能丢
- 获取音频帧数据的时候可能需要转格式
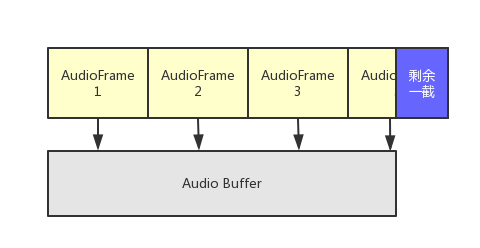
因为剩了一截,那么下一次填充就不能从完整的音频帧数据开始了。所以需要一个索引,指示AudioFrame的数据上次读到哪了,然后从这开始读。
while (len > 0) {
//获取新的audioFrame
if (is->audio_buf_index >= is->audio_buf_size) {
audio_size = audio_decode_frame(ffp);
if (audio_size < 0) {
is->audio_buf = NULL;
is->audio_buf_size = SDL_AUDIO_MIN_BUFFER_SIZE / is->audio_tgt.frame_size * is->audio_tgt.frame_size;
} else {
is->audio_buf_size = audio_size;
}
is->audio_buf_index = 0;
}
len1 = is->audio_buf_size - is->audio_buf_index;
if (len1 > len)
len1 = len;
if (!is->muted && is->audio_buf && is->audio_volume == SDL_MIX_MAXVOLUME)
memcpy(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1);
else {
memset(stream, 0, len1);
}
len -= len1;
stream += len1;
is->audio_buf_index += len1;
}
-
len代表当前AudioBuffer剩余的填充量,因为len -= len1;每次循环都会减去这次的填充量 -
audio_buf_size是当前的AudioFrame总的数据大小,audio_buf_index是这个AudioFrame上次读到的位置。所以memcpy(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1);这句填充函数里,从audio_buf+audio_buf_index的位置开始读。 -
len1开始是当前的AudioFrame剩余的数据大小,如果超过了AudioBuffer剩余的填充量(len),就只填充len这么多。 - 如果不可填充,就插入0:
memset(stream, 0, len1)。
audio_decode_frame获取音频帧数据
-
frame_queue_nb_remaining没有数据,先睡会av_usleep (1000); -
frame_queue_peek_readable读取新的音频帧,frame_queue_next调到下一个位置。 - 转换分3部:
- 设置转换参数
3个转换前的音频参数,3个转换后的参数,都是3大样:声道、格式、采样率。is->swr_ctx = swr_alloc_set_opts(NULL, is->audio_tgt.channel_layout, is->audio_tgt.fmt, is->audio_tgt.freq, dec_channel_layout, af->frame->format, af->frame->sample_rate, 0, NULL);- 初始化转换
swr_init(is->swr_ctx) < 0 - 转换操作
const uint8_t **in = (const uint8_t **)af->frame->extended_data; uint8_t **out = &is->audio_buf1; int out_count = (int)((int64_t)wanted_nb_samples * is->audio_tgt.freq / af->frame->sample_rate + 256); int out_size = av_samples_get_buffer_size(NULL, is->audio_tgt.channels, out_count, is->audio_tgt.fmt, 0); ..... av_fast_malloc(&is->audio_buf1, &is->audio_buf1_size, out_size); ...... len2 = swr_convert(is->swr_ctx, out, out_count, in, af->frame->nb_samples);in是frame->extended_data,就是原始的音频数据,音频数据时存放在extended_data里而不是data里。
out是is->audio_buf1的地址,转换完后,数据直接写到了is->audio_buf1里。
av_fast_malloc是重用之前的内存来快速分配内存,audio_buf1是一个重复利用的中间量,在这里装载数据,在播放的时候用掉数据。所以可以利用好之前的内存,不必每次都构建。 - 不管是否转换,数据都到了
is->audio_buf,填充AudioBuffer的时候就是用的这个。
最后
把主流程和某些细节写了一遍,这个项目还有一些值得说的问题:
- 音视频同步
- AVPacket和AVFrame的内存管理和坑
- 缓冲区的构建和操作,这应该是有一种最佳实践的,而且这是一个很通用的问题。
- 平台各异的显示层和核心的解码层是怎么连接到一起又互相分离的。