学习Hive和Impala必看经典解析
Hive和Impala作为数据查询工具,它们是怎样来查询数据的呢?与Impala和Hive进行交互,我们有哪些工具可以使用呢?
我们首先明确Hive和Impala分别提供了对应查询的接口:
(1)命令行shell:
1、Impala:impala shell
2、Hive:beeline(早期hive的命令行版本是hive shell,现在基本不使用)
(2)Hue Web UI:
1、Hue里面提供了 Hive查询编辑器
2、Hue里面提供了Impala查询编辑器
3、Hue里面提供了元数据管理器,可以直接对元数据进行访问。
(3)提供了JDBC和ODBC支持
下面进行具体介绍:
一、Impala
(1)使用Impala shell
Impala shell是类似于MySQL的交互式工具,可以直接在终端启动Impala shell,但是Impala shell在哪里启动很有讲究。Impala本身是分布式的架构,它的Impalad是在每个slave节点中的。那么Impala按照如下这种情况直接执行的话肯定是在slave节点中运行的。
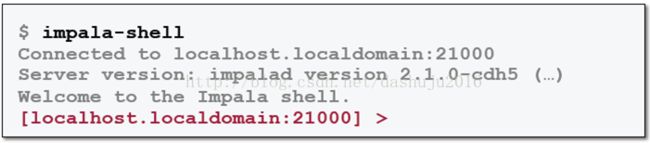
如果不是在slave节点中运行的话,可以指定它的server,像如下这种方式,通过—i的参数,指定21000端口执行。

Impala shell和所有的SQL一样,输入分号作为语句的结束,使用quit命令退出shell。如果需要查看帮助的话使用impala-shell --help查看完整的选项列表。因为任何的工具它的参数都是很多的,一定要习惯和学会使用帮助去找到自己想要的一些参数,然后去解决一些复杂数据的分析和处理。
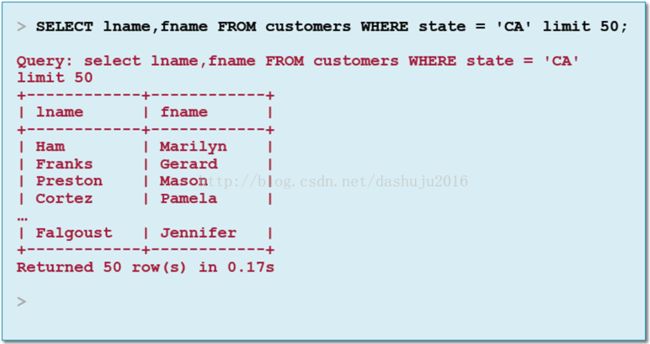
在Impala shell里面执行查询的示例:
(2)Impala与操作系统进行交互
在Impala里面,我们有时候需要去执行一些Linux的命令,比如查询日期,远程连接,访问目录数据等,我们不需要退出Impala shell,直接操作就可以,比如:

但是Impala不直接支持HDFS命令,但是可以使用shell运行hdfs dfs命令去创建一个目录,如下:

(3)从命令行运行Impala查询,可以不用登陆Impala shell就可以执行,如:
1、使用-f选项来执行包含查询的文件

2、使用-q选项直接在命令行运行查询

3、使用-o来将结果输出到文件

二、Hive
(1)启动beeline
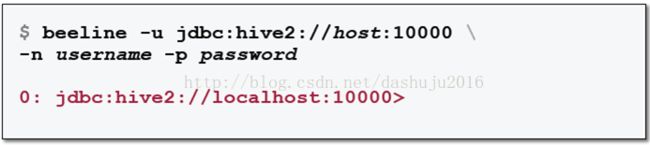
Hive shell是Hive早期版本,现在使用Beeline shell,跟Impala shell相似,但是它是基于JDBC和ODBC,如果需要使用Beeline的话,需要去启动Hive2,通过为Hive2服务器指定URL来启动Beeline,这个时候还需要根据需要指定用户名和密码,如下:
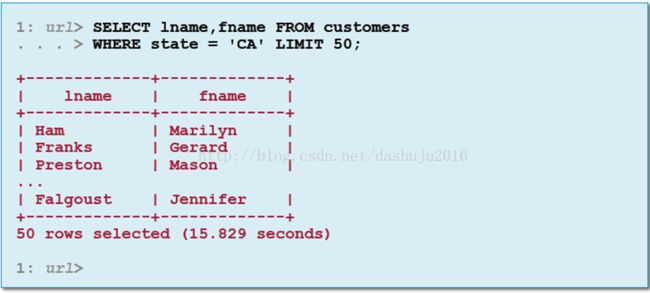
(2)在Beeline执行查询
和SQL一样以分号结束,执行查询和Impala shell类似,但结果格式有少许不同,如:
(3)使用Beeline
和其他工具有一些不同,执行查询都是正常的SQL输入,但是如果是一些管理的命令,比如进行连接,中断,退出,执行Beeline命令需要带上“!”,不需要终止符。常用命令介绍:
1、!connect url – 连接不同的Hive2服务器
2、!exit – 退出shell
3、!help – 显示全部命令列表
4、!verbose –显示查询追加的明细
示例:

(4)从命令行执行Hive查询
1、使用-f选项来执行包含HiveQL代码的文件

2、使用-e选项直接在命令行运行HiveQL

3、使用--silent来阻止通知的消息输出,也可以和-e或-f选项一起使用

三、Hue
(1)通过Hue访问Hive和Impala,它们各自都有editors,在Hue的query editors里面我们可以找到Hive和Impala的一些工具,
如下:
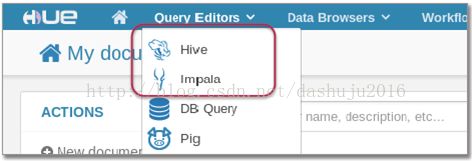
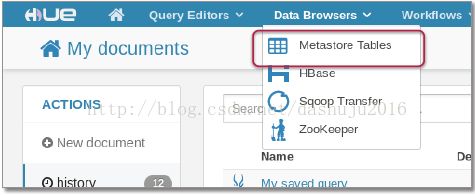
以及元数据库我们可以在Data Browsers里面可以看到它的一些工具,如:
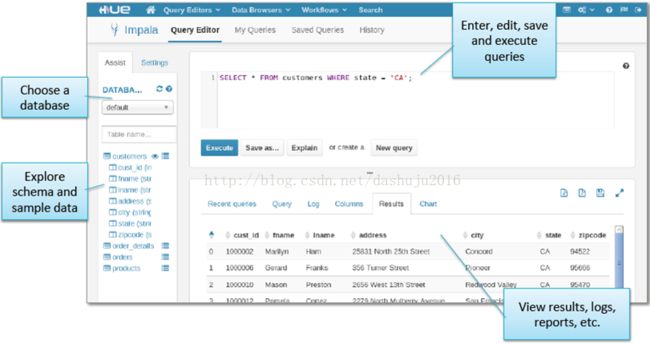
(2)Hue查询编辑器,查询Impala和Hive查询编辑器几乎相同,具体操作示意:
与Impala和Hive进行交互,以上就是我们可以利用和使用的工具,但是在实际的操作中我们还需要加强自己的实战能力才能更好的去掌握和理解。大数据作为当下还在不断完善发展的技术,需要每一位想要从事和已经从事它的人员不断去学习和积累,更需要去交流和分享,共同进步。“大数据cn”、“大数据时代学习中心”是我平时自己在自主学习过程中找到微信服务号,里面介绍的关于大数据的知识以及大数据发展的一些行业知识都很不错,平常大家可以看看。