Spark学习: Spark-Scala-IntelliJ开发环境搭建和编译Jar包流程
使用scala编写spark脚本的话,可以直接在spark-shell中运行,如果要提交整个脚本的话,就必须将scala脚本编译成Jar包,然后通过spark-submit 提交Jar包给spark集群,当需要重复利用脚本的话一般是需要编译成Jar包的,所以后面会介绍下怎么将scala编译成Jar包,前面则会介绍下怎么搭建spark-scala的开发环境,同时使用IntelliJ Idea编写scala脚本。
一 环境搭建
平台:Mac book 64位 OS X ver10.11.3 (windows和linux可借鉴,可能有点小区别)
依次安装如下软件:
1、Java
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
任选一个即可,本文选用的版本
JDK8ver 1.8都可以
将下载文件解压即可,在控制台输入Java –version出现如下字样安装成功。
如果安装了控制台却出不来以上结果,可按照第3步scala的环境配置操作一样添加Java环境变量。
2、spark
下载地址:http://spark.apache.org/downloads.html
本文选用的版本
1.5.1(Oct 02 2015)
Pre-Built forHadoop 1.X
将下载文件解压即可,pre-build已经事先编译好了
3、Scala
下载地址:http://www.scala-lang.org/download/all.html
本文选用的版本
2.10.6(为避免编译错误,最好不要选取2.11以上的,存在冲突)
解压到合适文件夹,记得将scala添加到环境变量里,如下:
首先在控制台输入 open~/.bash_profile,添加如下文本:
# 根据自己的scala地址修改下添加
export SCALA_HOME=/Users/krzhou/software/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH
添加完后在控制台输入 source ~/.bash_profile 重新读入环境生效
4、IntelliJ IDEA
下载地址:https://www.jetbrains.com/idea/
选用free版本,按流程安装即可,当到了需要选装插件的环节,添加scala插件即可。
其中不激活的话就先选evaluate for free
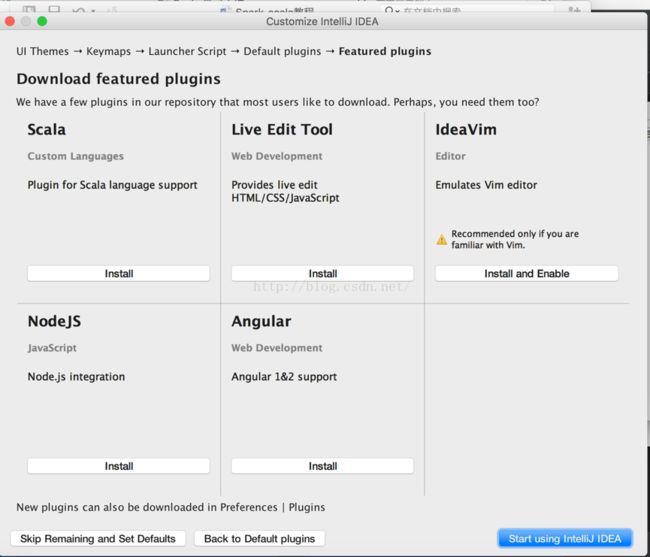
在default plugins的时候默认即可,feature plugins的时候记得选scala插件安装
二 构建项目
要使用Idea编写spark脚本需要在scala项目中添加spark/scala的Jar包。
首先创建项目
点击菜单栏File-New-project…-scala-scala,点击next,修改参数如下:

Project SDK是java文件夹的lib,Scala SDK是scala文件夹的lib。
导入Jar包:
① 导入scala 包
点击File-Project Structure-Libraries,点击+号-scala SDK,添加scala文件夹里lib里的scala-compiler.jar/scala-library.jar/scala-reflect.jar(这一步貌似不是必须的,因为前一步里已经导入了scala的SDK了)
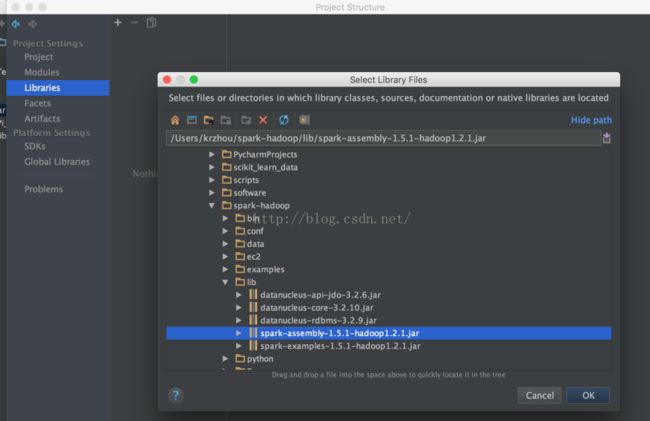
② 导入spark包
点击+号-Java,添加spark文件夹lib里的spark-assembly-1.5.1-hadoop1.2.1.Jar
创建脚本
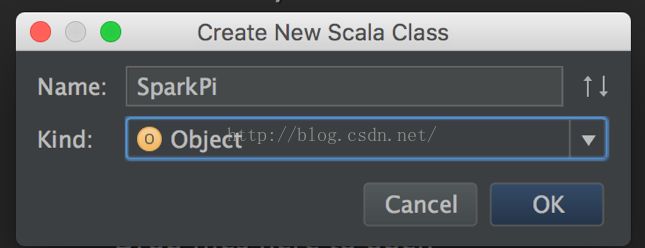
右键SparkPi_Test里的src, 创建Scala class

添加如下文本:(scala脚本):
/** Computes an approximation to pi*/
import scala.math.random
import org.apache.spark._
object SparkPi {
defmain(args:Array[String]){
valconf = newSparkConf().setAppName("Spark Pi").setMaster("local")
valspark = newSparkContext(conf)
valslices = if(args.length > 0) args(0).toInt else 2
valn = math.min(100000L * slices,Int.MaxValue).toInt // avoid overflow
valcount = spark.parallelize(1 until n, slices).map { i =>
valx = random * 2 - 1
valy = random * 2 - 1
if(x*x + y*y < 1) 1 else0
}.reduce(_+ _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
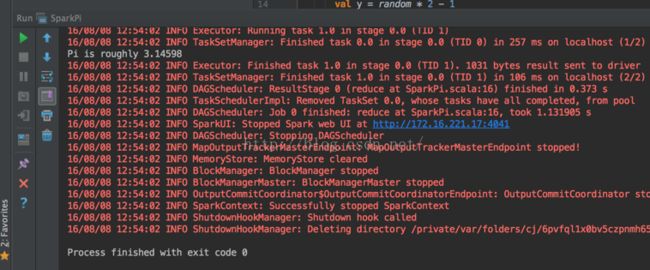
}点击菜单栏的Run-run SparkPi运行,
出现如下结果表示运行成功,显示Pi的值约为3.14598
三 编译Jar包
接下来将第二步编写的项目编译成可执行的Jar包。
点击File-project structure-Artifacts,点击+号添加如下
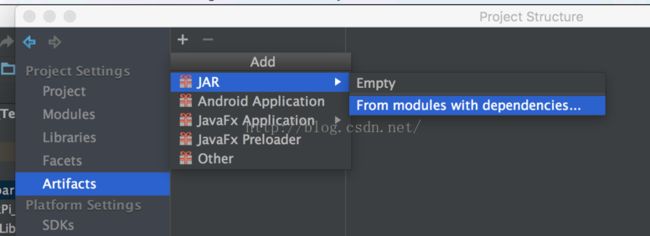
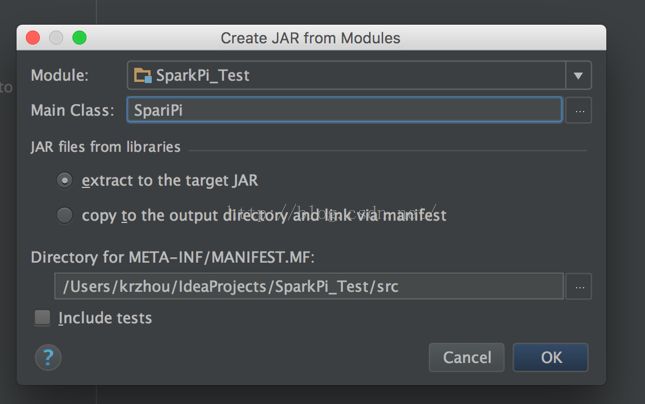
输入Main class名字SparkPi(跟运行的主程序名字保持一致),点击ok
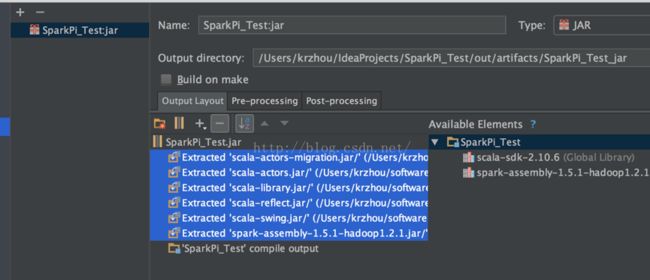
勾选所有的Extracted的Jar包,点击—号去掉,并勾选build on make
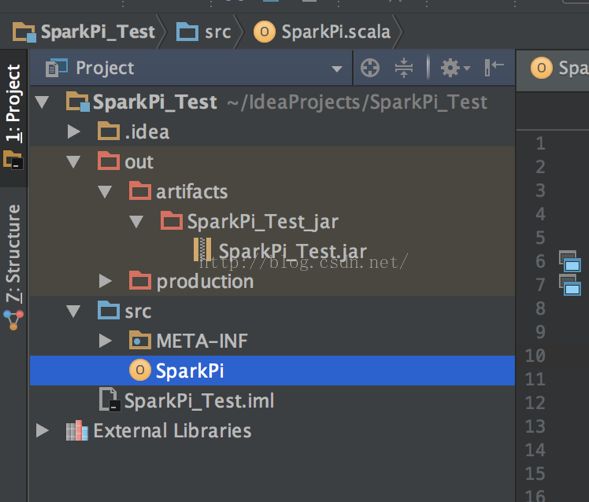
点击菜单栏build-build Artifacts-build,当左边目录下出现如下的SparkPi_Test.jar的jar包时,编译成功。
最后在控制台使用
/Users/krzhou/spark-hadoop/bin/spark-submit SparkPi_Test.jar --class SparkPi
提交查看运行结果:
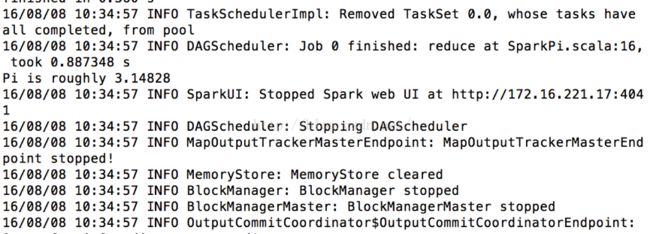
如图:Pi is roughly 3.14828,运行成功。
以上只是介绍了一种编译Jar包的方式,应该还有使用sbt等辅助工具的方式,暂时还不是很了解。
如果有不足的地方,欢迎一起讨论!