达观数据技术实践:知识图谱和Neo4j浅析

在当前大数据行业中, 随着算法的升级, 特别是机器学习的加入,“找规律”式的算法所带来的“红利”正在逐渐地消失,进而需要一种可以对数据进行更深一层挖掘的方式,这种新的方式就是知识图谱。
下面我们来聊一下知识图谱以及知识图谱在达观数据中的实践。
NO.1 什么是知识图谱
知识图谱(Knowledge Graph)是一种用点来代替实体,用边代替实体之间关系的一种语义网络。通俗来说,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络,它提供了站在关系的角度去分析问题的视角。站在这个角度我们可以从“找规律”的维度上升到“理解”的维度, 这也就是为什么有人说知识图谱是 AI 的未来。
“达观数据是一家人工智能公司”这句话在机器看来只不过是一连串的字符, 但是在我们人看来却可以分成主谓宾三部分,即主语“达观数据”谓语“是”宾语“人工智能公司”。 那么有没有一种数据的组织形式让机器看到这句话时不再是一个字符串, 而是一个具有类似主谓宾可以“理解”的结构呢?当然,这就是知识图谱要干的事情。
知识图谱可以表示成一个实体关系网络图,实体是包含信息的个体,画出来叫节点;关系是两个实体间的联系,画出来叫边。借用上面的例子“达观数据是一家人工智能公司”,“达观数据”和“人工智能公司”是两个实体,“是”即这两个实体之间的关系。
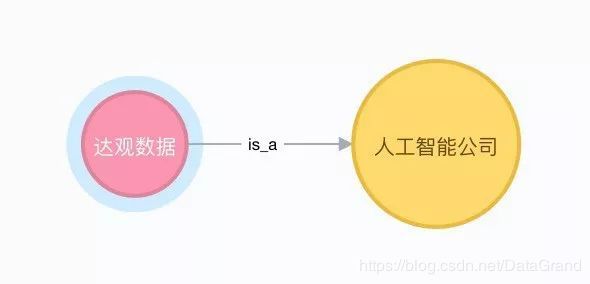 图 1 知识图谱表示实体关系网络图
图 1 知识图谱表示实体关系网络图
NO.2 应用场景
知道了什么是知识图谱,那么知识图谱有什么用处呢?这里我举两个例子:知识图谱在搜索引擎中的作用以及在银行风控系统中的应用。
1 知识图谱在搜索引擎中的应用
有时候我们在使用搜索引擎时, 我们的搜索词(Query)往往看起来更像是一个问题,比如“张三是从哪里毕业的”,这时我们需要搜索引擎直接给出我想要的结果,而不是一个网页排名(page rank) 。比如我在 google 中搜索“扎克伯格的妻子是谁”, 我需要是扎克伯格的妻子普莉希拉・陈的详细信息而不是一些包含了她信息的网页。我们先看下 google 的结果:
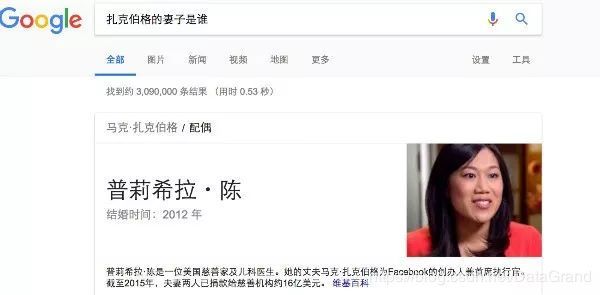 图 2 google 中搜索“扎克伯格的妻子是谁”
图 2 google 中搜索“扎克伯格的妻子是谁”
那么Google是怎么做到的呢?其实早在2012年Google 就已经在搜索中加入了知识图谱,用户可以通过Google 构建的知识图谱直接查询到结果,这种方式极大地提升了用户体验。然而对于 Google 来说处理起来也比较便捷,首先将“扎克伯格的妻子是谁” 这个 Query通过自然语言处理技术(NLP)处理成“扎克伯格”实体和”has_wife" 的关系,从已经构建好的知识图谱中查询, 然后将查询结果返回给用户。
然而就是这样的一个改动,从用户使用的角度来看已经从普通的搜索引擎变成了智能问答的系统,用户体验上升了一个层次。
2 知识图谱在隐含关系挖掘中的应用
马克斯·韦伯曾说“人是悬挂在自我编织的意义之网上的动物”,这句话从侧面说明人与人之间的关系是很复杂的,我们是否可以将复杂的人际关系进行一次挖掘呢?
首先人际关系实际形如一张网, 既然是网那么它一定具有一个特性,即网上两个相邻节点之间的路径损坏,并不一定影响整张网。比如 一张网(无向图)中相邻的 A 节点到 B 节点的路径“坏了”, 有极大可能找到另一条从 A 到 B 的路径,而不影响整张网。那么网的这个特性应该怎样应用到数据挖掘上来呢?我们来看一个知识图谱在银行风控系统中的例子
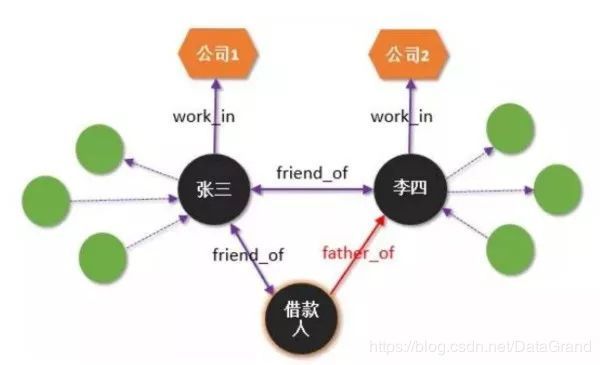 图 3 知识图谱在银行风控系统中的应用
图 3 知识图谱在银行风控系统中的应用
我们可以根据借款人借款时填写的关系构建知识图谱, 如图借款人跟张三是朋友关系,跟李四是父子关系。当我们试图把借款人的信息添加到知识图谱里的时候,“一致性验证”引擎会触发。引擎首先会去读取张三和李四的关系,从而去验证这个“三角关系”是否正确。很显然,朋友的朋友不是父子关系,所以存在着明显的风险。这里的隐含关系挖掘可以借用通用的关系挖掘引擎,也可以自己实现隐含关系的挖掘引擎。通用关联关系的挖掘由于其通用性,通常难以保证对关系挖掘的正确性,通常是自己配置规则来确保关系挖掘的准确性。对隐含关系的挖掘技术目前是知识图谱研究的前沿方向, 如果有兴趣,可以查阅相关论文。
知识图谱在银行风控中的作用还有很多,比如对失联借款人两度,甚至多度的关系挖掘来找到借款人等。 由此可见在“关系”越复杂的情况下,知识图谱越是能发挥它的作用。
知识图谱还有很多其他应用场景,这里就不一一列举了,如果您感兴趣的话,参见《知识图谱的应用》。
NO.3 图谱的构建
既然知识图谱这么有用,那么怎样才能构建自己的知识图谱,怎样将传统的数据转化成知识图谱呢?
传统数据主要分成两种,格式化数据和非格式化数据。格式化数据转化成知识图谱时需要将格式化的数据映射成实体关系组,从而构建知识图谱。而非格式化的数据转化时比较复杂,通常采用算法抽取和程序抽取两种方式。
1 算法抽取方式
通过自然语言处理(NLP)技术对文本进行命名实体识别(NER),从非格式化的文本中识别出专有名词和有意义的短语并进行分类。比如上例中从“达观数据是一家人工智能公司”这段文本中识别出”达观数据”和“人工智能公司”这两个实体以及“是”这个从属关系,这样我们就可以通过”达观数据” “是” “人工智能公司” 这个实体组来构建知识图谱。由于目前NER识别技术还不够成熟,通常我们会对NER 识别的实体进行人工矫正,确保所识别实体的准确性。
2 程序抽取方式
在处理实体识别非格式化数据的过程中我们经常会碰到半格式化的数据,比如一段简历的文本,文本中经常会包含,姓名:XXX,公司名:XXX 等格式,遇到这样的半格式化文本,我们也可以采用正则等方式来抽取,确保知识图谱构建的完整性和准确性。
NO.4 存储与性能
知识图谱是基于图的数据结构,通常用图数据库进行存储,我们先来看一下图数据库排行(部分)。
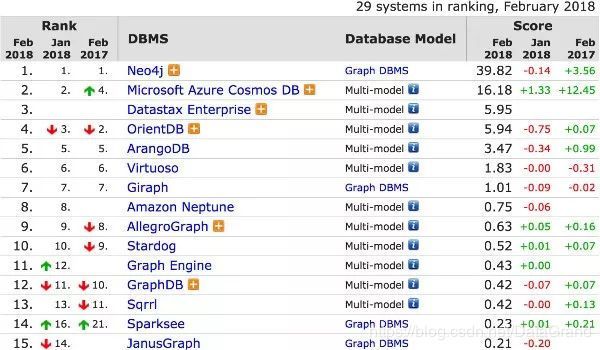 图 4 知识图谱的存储以及neo4j 的性能测试
图 4 知识图谱的存储以及neo4j 的性能测试
通过排行榜可以看出 Neo4j 数据库遥遥领先,实际上neo4j 已经是当前业界分析知识图谱的主流数据库。那么怎样将 neo4j 图数据库应用到项目中去,以及怎样优化 neo4j 图数据库呢?首先我们来看一下 neo4j 的性能表现:

测试内容: 节点数分别在1万, 10万, 100万,1000万情况下,在节点设置索引和不设置索引的情况下查找节点的平均延时。测试结果如下:
 图 5 查找节点平均延时的测试结果
图 5 查找节点平均延时的测试结果
通过上面的测试可以看出,当节点(Node)的数量超过1000万时,在不设置索引的情况下,平均查询延时已经超过了6秒,说明此时 neo4j 已经明显“吃不消”了,显然这样的延时这在实际的项目应用中是完全不可接受的。但是我们发现设置索引之后查询时间明显降下来了,那么是不是设置的索引越多越好呢?我们看下在1000万节点的情况下有索引和无索引插入延时测试:
 图 6 1000万节点情况下有索引和无索引的插入测试结果
图 6 1000万节点情况下有索引和无索引的插入测试结果
由上图测试结果可以看出: 在千万级数据的情况下有索引插入比无索引插入要慢30%, 所以索引并不是越多越好, 那么除此之外 neo4j 还有哪些地方可以优化呢?
NO.5 数据库优化
neo4j 不使用schema,所以从理论上来说 neo4j 可以存储任何形式的数据。但由于neo4j 是通过键值对(Key-Value) 的双向列表来保存节点和关系的属性值,所以neo4j仅适用于存储实体关系和实体简单的属性。在实际应用中一个实体通常会包含众多的属性,如果将这些属性全部存储到 neo4j 中,neo4j 的查询将变得异常的慢, 而在实际的应用场景下,经常会遇到高并发的情况。这时候单节点的 neo4j 就会显得力不从心。那么在项目实战中怎样更好的利用 neo4j 来抵御高并发呢?
1 高可用架构
neo4j HA(High Availability)即neo4j 的高可用特性,不过这个特征只能在neo4j 企业版中可用。neo4j HA使用多台neo4j从数据库设置替代单台neo4j主数据库的容错架构,这种架构可以在一台实体机故障的情况下使数据库具备完善读写操作的能力,由于 neo4j HA 采用主从数据同步, 而且写操作也可以在从库中执行(经测试这种方式不如主节点写入可靠)因此采用neo4j HA 比单台neo4j数据库拥有更多的读取负载处理能力。
如果你使用的不是 neo4j 企业版,那么你可能需要自己动手来构建 neo4j 集群以此来实现高可用架构了。当然你可以采用Neo4j+DRBD(Distributed Replicated Block Device)+ Keepalived 方式来构建自己的neo4j 集群, 通过 DRBD 来备份单点上的 neo4j 图库数据,通过Keepalived 来管理你的集群。除此之外你还可以通过 zookeeper 来管理你的集群节点,自己实现将主节点数据修改的Cypher 语句元操作同步到从节点(类似 MySQL 的binlog)来实现主从同步,从而达到读写分离。当然不管你采用方式一还是方式二,都会增大开发和维护成本。
2 增加缓存
应用缓存:在实际应用的过程中读写图库时经常会遇到查询一些不常修改的数据, 比如需要频繁查询用户所属的国家信息,而国家的属性更改的频率比较低,而且用户的国籍信息不会经常变动,这时我们可以通过添加应用缓存(如:redis, leveldb等),将查询的结果缓存起来,减少直接访问图库的频次,减小图库的读取压力。
数据库缓存:由于neo4j 执行一次查询操作之后,会将数据缓存到内存中,执行相同的查询操作 neo4j 直接返回内存中缓存的数据结果。如果是执行随机查询,则后一次结果会覆盖前一次的查询数据,内存缓存的配置可以通过修改配置文件中dbms.query_cache_size参数进行调整。所以说执行语句时尽可能的利用已有数据的缓存,减少 Cache-Miss 情况的发生。
3 索引查询优化
查询优化:由于 neo4j 会将查询结果缓存到内存中,所以不需要的查询结果尽量不要放到内存,比如 下面的cypher 语句:
![]()
语句1比语句2 更好,因为后者会将所有的节点和关系的属性加载到内存,然后计算 count 值,而前者只会将必要的属性加载到内存求count值。
索引优化:我们知道数据库索引实际上是在数据之外维护了特定算法的数据结构(如 B+Tree),比如图7为了加快 Col2的查询构建一个二叉树,使原来的“顺序”查找,变成“二分查找”,从而将查询复杂度降低为 o(logn),而且索引还会利用访问局部性原理,充分利用操作系统的页缓存,加快查找的速度。
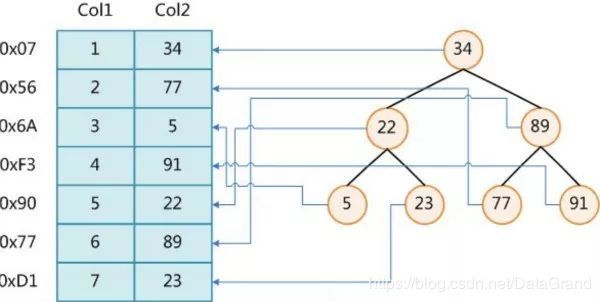 图 7 数据库索引原理介绍
图 7 数据库索引原理介绍
由于增加索引会让图库维护在维护数据的同时还会维护一份额外的数据结构,更新数据时会造成额外的开销,这也印证了上面测试的插入数据时无索引比有索引快的结论。
Neo4j 1.4以后的版本引入了自动索引(automatic index),可以在config/neo4j.properties中配置自动创建索引,也可以通过语句CREATE INDEX ON :Label(PropertyName)手动创建索引,从而提高查询的效率。
4 Neo4j和KV(Key Value)数据库联合使用
由于 neo4j 的节点和关系的属性是通过Key-Value 的双向列表来保存的,所以这种数据结决定了 neo4j 中存储的节点不能包含太多的属性值。但是在实际应用中经常会碰到一些实体拥有大量的属性,必要时还需要通过这些属性的值来查询实体进而查找实体拥有的关系。这时候可以将 neo4j 数据库和KV 数据库(如:MongoDB)进行联合使用,比如在 neo4j 节点的属性中存储MongoDB 中的 objectId。
这样既可以充分利用 neo4j 的特性来进行关系查询又可以通过 KV 数据库的特性来进行属性到实体的查询。通常在图库和 KV 数据库联合使用时, 特别是经常需要通过属性来查询实体时需要设置 neo4j schema Index,即将neo4j中与 KV 数据库关联的值设置索引。
NO.5 总结与展望
知识图谱和Neo4j还有很多有趣的特性,鉴于篇幅这里不再赘述。自Google在2012年推出知识图谱技术以来,知识图谱迎来了飞速的发展。由于知识图谱在关系“理解”方面的优势,目前已经在各大互联网公司和传统企业的项目中落地,并取得了良好的效果。
正是由于知识图谱对数据理解和传统方式不一致,给传统的数据挖掘算法带来了挑战。相信随着人们对知识图谱的关注度越来越高,在知识图谱领域将会涌现更多更成熟的构建、存储和挖掘理念,相信在不远的将来知识图谱将会在更广泛的领域内为大家服务。