Dubbo入门到精通学习笔记(十):dubbo服务集群 、Dubbo分布式服务子系统的划分、Dubbo服务接口的设计原则
文章目录
- dubbo服务集群
- Dubbo服务集群部署
- Dubbo服务集群容错配置--集群容错模式
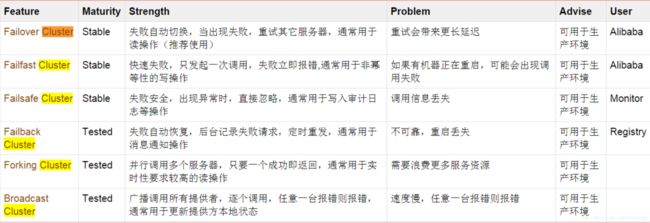
- 1、Failover Cluster 失败自动切换,当出现失败,重试其它服务器。`(缺省) 通常用于读操作,但重试会带来更长延迟。 可通过retries="2"来设置重试次数(不含第一次)。默认是retries="2"
- 2、Failfast Cluster
- 3、Failsafe Cluster
- 4、Failback Cluster
- 5、Forking Cluster
- Dubbo分布式服务子系统的划分
- 服务化的目标:
- 服务化的目标:
- 服务子系统的数量把控
- 服务子系统划分注意事项:
- Dubbo服务接口的设计原则
- 1、设计方式
- 2、接口类型
- 3、设计原则
dubbo服务集群
Dubbo服务集群部署
这里的集群部署说的是provider
以简易版支付系统中的部分服务为例:
用户服务:pay-service-user
交易服务:pay-service-trade

从上图已经看到hudson和dubbo的客户端已经将dubbo的服务布在了两个服务器上。
以pay-service-trade为例,搭建集群。(注意这个项目producer和consumer是在一个项目中,可能引起歧义)
新建任务==>pay-service-trade_71===>复制现有任务,要复制的任务名称是之前的pay-service-trade==>ok==>svn需要重新授权,ok==>ssh server >修改name,将原来的192.168.3.72_deu-provider-02改为192.168.3.71_deu-provider-01,其他的不变>save
记得把脚本拷贝到71机器
保存之后构建项目
在71机器上运行脚本,查看dubbo管理界面,发现这个服务部署在了两个机器上。
执行自己的查询业务,发现,没有问题,这个时候通过脚本关闭掉72(原来部署的机器)上的服务,只剩下71上的服务(刚刚配置的),发现还是能够执行自己的业务的。
同样将72启动,将71关掉,再次执行自己的业务,没有问题。
将71 72两个服务都关掉,就无法执行自己的业务了。tomcat报错没有rpc服务。
从而实现了服务节点的高可用
只需要把相同代码的程序,在不同ip的机器上部署,单独运行,就能实现集群部署,如果在同一个机器上部署,app的名字的端口需要修改
Dubbo服务集群容错配置–集群容错模式
标签:dubbo:service、dubbo:reference、 dubbo:consumer、dubbo:provider
dubbo:serviceserver端
dubbo:reference引用端
在项目中的dubbo的配置文件中对上面的标签进行设置
可以在以上标签上修改,但是后面dubbo:consumer、dubbo:provider力度比较粗,不建议在这两个标签使用。
属性:cluster
类型:string
是否必填:可选
缺省值:failover
作用:性能调优 集群方式:可选:failover/failfast/failsafe/failback/forking
兼容性:2.0.5以上版本
1、Failover Cluster 失败自动切换,当出现失败,重试其它服务器。`(缺省) 通常用于读操作,但重试会带来更长延迟。 可通过retries="2"来设置重试次数(不含第一次)。默认是retries=“2”
默认的
就想上面的71 72的例子就是如此
<dubbo:service retries="2" cluster="failover"/> 或:
<dubbo:reference retries="2" /> 或:
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
retries=“0”,就是不充实,只调一次
name="findFoo"在引用端能够指定方法。
cluster="failover"在这里配置不配置都可以,因为是默认值
2、Failfast Cluster
快速失败,只发起一次调用,失败立即报错。
通常用于非幂等性的写操作,比如新增记录。
假如写操作用(比如添加用户信息)1里面的Failover策略,第一次写进去了,然后在返回的过程中,超时了,这个时候消费端检测到服务超时了,又重试,第二次又写进去了,就会造成重复写的问题。
相当于第一种策略中的retries=“0”,只调用一次
以上情况就需要Failfast这种方式。
<dubbo:service cluster="failfast" /> 或:
<dubbo:reference cluster="failfast" />
第一种和第二种是dubbo中最常用的
3、Failsafe Cluster
失败安全,出现异常时,直接忽略。
通常用于写入审计日志等操作。
<dubbo:service cluster="failsafe" /> 或:
<dubbo:reference cluster="failsafe" />
dubbo服务中心就用的这种方式,日志可记可不记,如果因为某种特殊情况没有记录到也无所谓,业务继续运行,对我的业务没有影响。
4、Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。
通常用于消息通知操作。
<dubbo:service cluster="failback" /> 或:
<dubbo:reference cluster="failback" />
dubbo的注册中心,注册发现,如果失败了就不断的去触发,不断的去发现,直到成功为止,在业务中不会用到。
5、Forking Cluster
并行调用多个服务器,只要一个成功即返回。 通常用于实时性要求较高的读操作,但需要浪费更多服务资源。 可通过forks="2"来设置最大并行数。
<dubbo:service cluster=“forking" /> 或:
<dubbo:reference cluster=“forking" />
就像上面的例子如果用这种策略,同时向71 和 72发起交易查询业务, 谁先返回结果给我,就用谁的结果,容易出现资源浪费。
策略成熟度(官方)
一般用Failover即可,即默认的模式,因为 retries=0和Failfast的效果是一样的。
建议查询方法的 什么也不需要配置,如果是写入的方法配置retries=0
Dubbo分布式服务子系统的划分
服务化的目标:
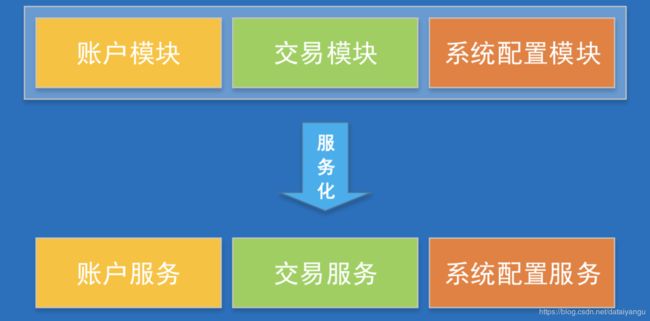
将系统中独立的业务模块抽取出来,按业务的独立性进行垂直划分,抽象出基础服务层。
服务化的目标:
基础服务为上游业务的功能实现提供支撑,基础服务应用本身无状态,可随着系统的负荷灵活伸缩来提供服务能力。
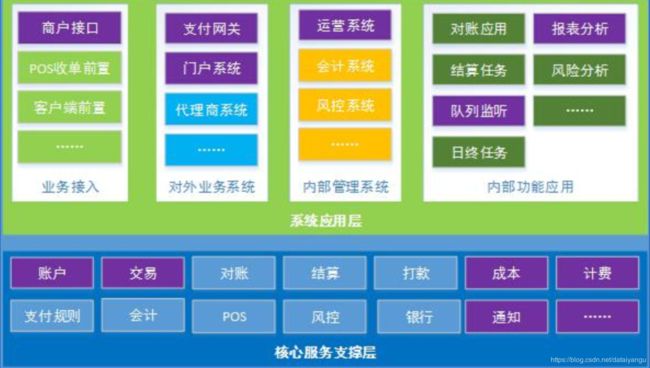
服务子系统的数量把控
过多:可能划分过细,破坏业务子系统的独立性
(如:支付订单、退款订单,用户、账户)
部署维护工作量大,独立进程占用内存多
过少:没能很好的解耦
开发维护不好分工
升级维护影响面大(举个栗子,如果将很多业务融合入在一个服务中的话,一个报错,需要停掉,这个时候其他的服务也无法正常运行。)
(以简易版支付系统服务的划分为例)
服务子系统划分注意事项:
不要出现A服务中的SQL需要链接查询到B服务中的表等情况, 这样在A服务与B服务进行垂直拆库时就会出错,数据库中的查询跨服务了。(很可能在编写程序的时候没有报错,但是将来将不同的服务部署到机器上的时候,就会出现错误了,所以在设计的时候就应该尽量避免)
服务子系统间避免出现环状的依赖调用(比如a调b,b调c,c调d,可能是因为某个表可以划分到另外一个服务中去,即这个服务需要调优。)
服务子系统间的依赖关系链不要过长(比如a调b,b调c,c调d。。。建议不要超过三个
,允许存在服务调服务,但是不能太长。比如一个支付功能通过多个服务完成,将支付这个操作完成的太细。)
尽量避免分布式事务(尽可能确保系统中的业务是紧密关联的,而且可以放在一起,避免将服务拆分的过细,还是上面支付的例子)
Dubbo分布式服务子系统的划分
服务子系统的划分是一个不断优化的过程
Dubbo服务接口的设计原则
1、设计方式
《第02节–使用Dubbo对传统工程进行服务化改造》
action(服务的消费端)、facade(服务的接口)、biz(业务逻辑层)、dao(dao层)
好的Dubbo服务接口设计,并非只是纯粹的接口服务化
2、接口类型
简单数据查询接口:action、facade、dao
带业务逻辑的数据查询接口:action、facade、biz、dao
简单的数据写入接口:action、facade、dao
带业务逻辑的数据写入接口:action、facade、biz、dao
同步接口
异步接口
3、设计原则
- 接口粒度:
服务接口尽可能大粒度,每个服务方法应代表一个功能,而不是 某功能的一个步骤,否则将面临分布式事务问题,Dubbo暂未 提供分布式事务支持。同时可以减少系统间的网络交互。
服务接口建议以业务场景为单位划分,并对相近业务做抽象, 防止接口数量爆炸。
不建议使用过于抽象的通用接口,如:Map query(Map), 这样的接口没有明确语义,会给后期维护带来不便。
- 接口版本:
每个接口都应定义版本号,为后续不兼容升级提供可能,
如:
- 接口兼容性:
服务接口增加方法,或服务模型增加字段,可向后兼容; 删除方法或删除字段,将不兼容,枚举类型新增字段也不兼容, 需通过变更版本号升级。
- 异常处理:
建议使用异常汇报错误,而不是返回错误码,异常信息能携带 更多信息,以及语义更友好。
如果担心性能问题,在必要时,可以通过override掉异常类的 fillInStackTrace()方法为空方法,使其不拷贝栈信息。
查询方法不建议抛出checked异常,否则调用方在查询时将过 多的try…catch,并且不能进行有效处理。
服务提供方不应将DAO或SQL等异常抛给消费方,应在服务实 现中对消费方不关心的异常进行包装,否则可能出现消费方无 法反序列化相应异常。
-
必要的接口输入参数校验,避免做无用功。
-
在Provider上尽量多配置Consumer端属性:
原因如下: 作服务的提供者,比服务使用方更清楚服务性能参数,如调用的超时时间, 合理的重试次数,等等 在Provider配置后,Consumer不配置则会使用Provider的配置值, 即Provider配置可以作为Consumer的缺省值。否则,Consumer会使用 Consumer端的全局设置,这对于Provider不可控的,并且往往是不合理的。
Provider上尽量多配置Consumer端的属性,让Provider实现者一开始就思 考Provider服务特点、服务质量的问题。
样例:

服务接口设计与服务子系统划分过程相互优化。