大数据学习笔记之Flume(一):Flume入门
文章目录
- 1、Flume在集群中扮演的角色
- 2、Flume框架简介
- 3、安装配置FLume
- 3.1 flume-env.sh
- 4、Flume帮助命令
- 5、案例:
- 5.1、案例一:Flume监听端口,输出端口数据。
- 5.1.1、创建Flume Agent配置文件flume-telnet.conf
- 5.1.2、安装telnet工具
- 5.1.3、首先判断44444端口是否被占用
- 5.1.4、先开启flume监听端口
- 5.1.5、使用telnet工具向本机的44444端口发送内容。
- 5.2、案例二:监听上传Hive日志文件到HDFS
- 5.2.1 拷贝Hadoop相关jar到Flume的lib目录下
- 5.2.2 创建flume-hdfs.conf文件
- 5.2.3、执行监控配置
- 5.3、案例三:Flume监听整个目录
- 5.3.1 创建配置文件flume-dir.conf
- 5.3.2、执行测试
- 总结:
1、Flume在集群中扮演的角色
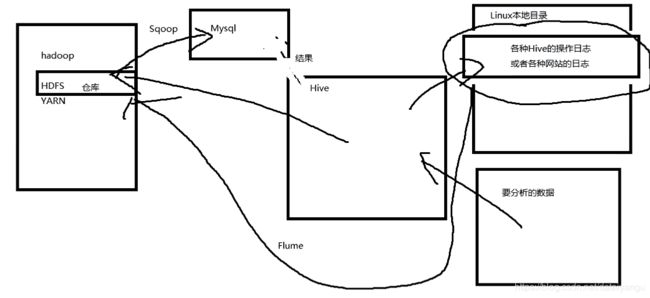
将hive产生的日从linux本地移到HDFS上
Flume、Kafka用来实时进行数据收集,Spark、Storm用来实时处理数据,impala用来实时查询。
2、Flume框架简介
1.1 Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。
1.2 Flume基于流式架构,容错性强,也很灵活简单,主要用于在线实时分析。
1.3 角色
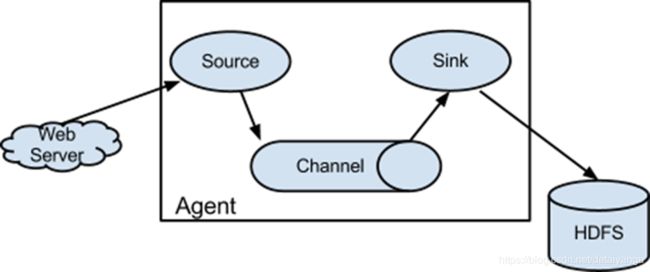
** Source
用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,这个有点类似于Java IO部分的Channel,总的来说就是指定数据的来源的
** Channel
用于桥接Sources和Sinks,类似于一个队列。
** Sink
从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)

工作原理

当数据产生的时候,会把数据流拆分成一个一个的事件,比如现在监控的是hive.log中的日志,当操作hive的时候,文件是在不停的刷新的,通过tail -f hive.log 向flume中传输大量的数据流,拆分成一个个的event,每个event又分为Header和Body,相当于http的header和body,header中包含了数据的来源,使用什么样的协议,body某个event中携带的数据。
比如某个时间段产生的数据流,一次采集到的“123 123 123 123”,分为若干个event比如:“123(event) 123(event) 123(event) 123(event)”,一个123就是一个event,source负责把拆分好的event放到对了channel(先进先出)里面,现出来的event对接到sink,sink拿到event之后进行解码处理,解码之后放在想放在的地方,比如hdfs或者linux本地的另一个位置
fliume还能抓包
flume除了监听文件之外,还能监听端口,数据产生和消费的地方,都是要经过端口的,flume监听端口,只要端口中有数据往来,就把端口中所有监听到的数据,收集过来。
1.4 传输单元
** Event
Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地
1.5 传输过程
source监控某个文件,文件产生新的数据,拿到该数据后,
将数据封装在一个Event中,并put到channel后commit提交,
channel队列先进先出,sink去channel队列中拉取数据,然后写入到hdfs或者HBase中。
3、安装配置FLume
直接下载解压即可
mv flume-enc.sh.template flume-env.sh
3.1 flume-env.sh
配置Java的环境变量
export JAVA_HOME=/opt/..../jdk1.8.0_121
4、Flume帮助命令
$ bin/flume-ng
5、案例:
5.1、案例一:Flume监听端口,输出端口数据。
5.1.1、创建Flume Agent配置文件flume-telnet.conf
# Name the components on this agent
//为当前的agent去一个名称叫a1,也可以叫agent1,只是一个名字
//下面是分别为三个角色取名字
//整个为agent sources sinks channels 取别称,分别为a1 r1 k1 c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
//原数据的数据类型是怎么来的netcat
a1.sources.r1.type = netcat
//绑定本地的主机
a1.sources.r1.bind = localhost
//产生数据的数据源的端口
a1.sources.r1.port = 44444
# Describe the sink
//sink的类型是logger类型,就是在终端可以打印出来,相当于一个解过码的字符串
//在流里面的数据如果直接打印的话是不可视的,100101101
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
//指定在传输的过程中,即数据在channel阶段,数据以什么样的形式流转,或者以什么样的形式保存
//以内存的形式流转或保存,好处是特别快,坏处是容易丢数据,因为内存中的数据一断电就没有了
a1.channels.c1.type = memory
//在内存中进行转储的时候,最多接受的event是1000个
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
//连接操作,source所对应的channel是c1,sink对应的channel是c1
//注意sources对应的channels,sources可以对应多个channel,但是sink只能对应一个
//如下图
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

5.1.2、安装telnet工具
$ sudo rpm -ivh telnet-server-0.17-59.el7.x86_64.rpm
$ sudo rpm -ivh telnet-0.17-59.el7.x86_64.rpm
5.1.3、首先判断44444端口是否被占用
$ netstat -an | grep 44444
5.1.4、先开启flume监听端口
//bin/flume-ng agent指定agent角色的目录,--conf conf/ 指定agent的配置目录,
//--name a1 agent名字,--conf-file conf/flume-telnet.conf指定具体的是哪个配置文件
//-Dflume.root.logger==INFO,console配置当前监听到的内容,往哪个地方展示,即是否开启调试模式
$ bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/flume-telnet.conf -Dflume.root.logger==INFO,console
5.1.5、使用telnet工具向本机的44444端口发送内容。
$ telnet localhost 44444
5.2、案例二:监听上传Hive日志文件到HDFS
5.2.1 拷贝Hadoop相关jar到Flume的lib目录下
share/hadoop/common/lib/hadoop-auth-2.5.0-cdh5.3.6.jar
share/hadoop/common/lib/commons-configuration-1.6.jar
share/hadoop/mapreduce1/lib/hadoop-hdfs-2.5.0-cdh5.3.6.jar
share/hadoop/common/hadoop-common-2.5.0-cdh5.3.6.jar
5.2.2 创建flume-hdfs.conf文件
在flume的conf目录下创建
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
//将原来的netcat写成exec
//exec用一个可执行的命令,监控某个文件作为source
a2.sources.r2.type = exec
//这里的目录就是hive的目录,在本配置文件的末尾有相关的图片
//注意不要写成hive.log.2017-07-21这种,这种已经不会发生变化了,只有hive.log才会发生变化
a2.sources.r2.command = tail -f /opt/modules/cdh/hive-0.13.1-cdh5.3.6/logs/hive.log
// /bin/bash -c 的作用相当于``
//举个栗子 echo data 会输出data这个字符串 echo `data` 会输出日期
//等同于 echo /bin/bash -c data ,输出执行data这个命令。
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
//将sink设置为hdfs类型
a2.sinks.k2.type = hdfs
//抽取的文件上传到hdfs系统中的目录,以格式化的时间创建目录,会根据时间动态改变
a2.sinks.k2.hdfs.path = hdfs://192.168.122.20:8020/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = events-hive-
#是否按照时间滚动文件夹,是否按照时间创建文件夹分类
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹,单位默认是1分钟
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳,默认false
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件,多久进行一次滚动
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小,多大的文件进行一次滚动
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关,多少个事件进行一次滚动,很多时候,很多个事件就是一句话
#所以一般设置为0,不根据event的数量生成文件
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数,最小备份数,即上面有三种生成新的文件的规则,那是不是需要三个文件呢?,hdfs自带冗余,所以这里是1,不是3,除了hdfs还有磁盘阵列等文件存储系统也是带冗余的
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
![]()
在hive中配置了log4j的话,到相应的目录页下会有日志,hive.log是当天的日志,过了今天之后这个日志就会变成后面的形式
5.2.3、执行监控配置
$ bin/flume-ng agent --conf conf/ --name a2 --conf-file conf/flume-hdfs.conf

在被监控的hive里面做一些事情

在hdfs中查看

tmp文件表示,文件还在滚动,生成真正的文件之后会变成真正的文件的格式
将文件下载下来,就是刚才hive的相关操作,中间有个报错,不要在意这些细节,是因为重新创建库了,因为没有做if exist判断
5.3、案例三:Flume监听整个目录
5.3.1 创建配置文件flume-dir.conf
$ cp -a flume-hdfs.conf flume-dir.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
// 这里需要进行修改
a3.sources.r3.type = spooldir
//command换成spoolDir 监控的目录是/opt/modules/cdh/apache-flume-1.5.0-cdh5.3.6-bin/upload
a3.sources.r3.spoolDir = /opt/modules/cdh/apache-flume-1.5.0-cdh5.3.6-bin/upload
//保存文件的时候,是否要保存文件的绝对路径
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
//如果监控的目录里面有符合这个正则表达式的,就不上传这个文件
//什么情况下回用到呢?
//一种情况:
//比如在upload文件夹里面,有一个框架正在往里面写日志,比如叫nginx.log.temp,如果已经写完了
//就变成了nginx.log,也就是说nginx.log.temp是一直在变动的,是不希望上传的,
//在flume中为了区别已经上传的文件和未上传的文件,已经上传的会自动在文件的末尾加上.COMPLETED作为区分
//但是这个文件正在用着,如果在往里面写的过程整,在后面加上了.COMPLETED,name不是temp结尾了,
//就不能继续往里面写入了
//另一种情况:
//加入现在nginx.log.temp里面写着123456,然后上传了,这个时候里面又写了789,这个时候再次上
//传,就会变成123456123456789,上传了两次123456,也就是hdfs里面会有很多重复的
//这个时候就需要includePattern(上传包含了正则表达式的) 和 ignorePattern (不上传包含正则表达式的)
//所有的.tmp结尾的文件都不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://192.168.122.20:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
往当前的目录复制点文件

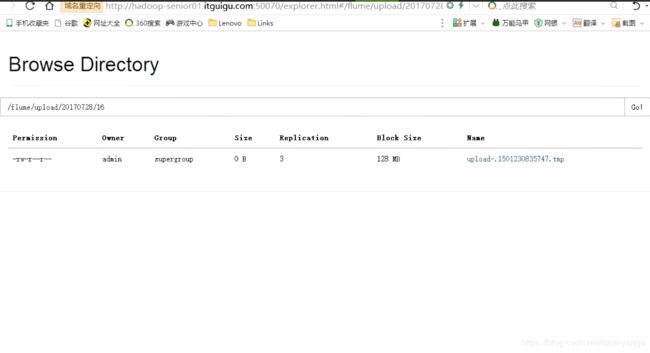
下载下来看一看

发现很快就上传上去了,为什么这么快?每六百秒扫描一次当前的目录,当前目录只要有变化就会上传。
注意:如果拷贝一个.tar.gz结尾的很大的文件,比如说一个g,上传上去需要多久?
答案是不会上传,因为flume上传的是日志文件,flume是监控数据实时变化的,流式数据。
那有的人说直接将.tar.gz结尾的文件修改后缀,注意,在被监控的文件夹下面直接修改文件的类型会报错的,
注意:不要直接在被监控的文件夹里面直接创建文件,比如vi aaa.sh,是无效的,flume监控的是直接从其他的文件拷贝过来的完结的文件,而不是在当前的被监控的文件里面创建文件。
所以上的例子应该在外面将后缀改为日志小文件格式,然后拷贝到当前被监控的目录中,就可以被监控并上传了。
5.3.2、执行测试
$ bin/flume-ng agent --conf conf/ --name a3 --conf-file conf/flume-dir.conf &
总结:
在使用Spooling Directory Source
注意事项:
1、不要在监控目录中创建并持续修改文件
2、上传完成的文件会以.COMPLETED结尾
3、被监控文件夹每600毫秒扫描一次变动
作业:
1、实现hive.log日志实时上传到HDFS,同时实现Hadoop日志实时展示在控制台。