大数据学习笔记之项目(一):离线平台项目测试
1、将项目软件工具包导入
2、项目思路:
2.1、读取HDFS数据进行ETL清洗操作,并将最终结果写入到HBase中
2.2、从HBase中读取数据,进行新增用户统计分析操作,并将结果写入到Mysql
3、细节实现
数据清洗:
如果把数据清洗全部都写到Maper的map方法里, 那这个map方法太冗余了,所以把比较公共的清洗放在LoggerUtil里面
3.1、LoggerUtil.java
3.1.1、主要作用:将字符串数据解析成HashMap键值对集合
3.1.2、重要细节:

为什么这里解析成hashmap
?左边是ip地址服务器时间戳uri,右边全部是带回来的数据,可以理解为get请求或者post请求带回来的数据,先用?分割,然后又用&分割,一个&代表一个键值对,键值对的键和值用=分割。
-
字符串的截取
-
不合法数据的过滤
- 字符串的解码(就是将%相关的字符串编码转换成可读类型的数据)
浏览器为了防止传输的内容和固定的形式冲突,所以把特殊符号进行%编码,假设在url中有这样的设置 xxx&a=b-c=d&在这b-c=d其实是一个值,但是因为有=所以可能有歧义,所以在键值对(不论是key还是value)里面如果出现了特殊字符,就会把特殊字符转换成%D这样的东西,这样就能保证不会出错了,在用的时候只需要进行解码就行了,因为是可逆的。
-
错误数据的Logger输出
3.2、AnalysisDataMapper.java
rowkey的生成规则:
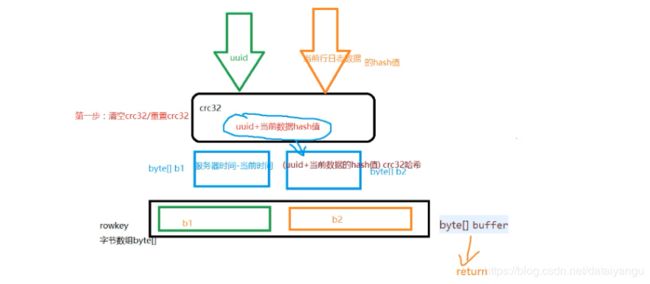
crc32哈希,是一种哈希算法
3.2.1、主要作用:开始清洗HDFS中的日志数据
3.2.2、重要细节:
-
开始清洗数据,首先使用LoggerUtil将数据转换成Map集合
-
将得到的存放原始数据的Map集合封装成事件以用于事件数据合法性的过滤(事件的封装依赖于一个枚举类,
使用事件的alias别名来区分匹配事件)
** 事件的封装要按照平台来区分
*** 平台区分完成后,按照事件类型来区分(例如en=e_l等) -
事件封装过程中涉及到事件数据完整性的清洗操作
-
数据输出:创建rowKey,创建Put对象,等待输出到HBase
3.3、AnalysisDataRunner.java
3.3.1、组装Job -
设置Mapper以及Mapper的输出Key和输出Value
-
设置Reducer的数量为0
-
配置输入路径(按照传入的时间读取指定HDFS时间文件夹中的数据)-data 2017-08-21 --> /event_logs/2017/08/21
-
设置输出(主要是按照传入时间,创建指定HBase表,以用于数据保存输出)
HBase表名要和时间有关系 – > event_logs20170821
HBaseAdmin创建表–>如果表存在,则删除重新创建
数据分析:
HBase –
HBaseInputFormat--TableMapper(DBOutputFormat)–mysql3.4、NewInstallUsersMapper.java
注意在浏览器中 % 是 %25

我们的数据中可能单独存在百分号,这个百分号单独存在不合理,如果有单独的%的话,意思是%25,如果是这样的话,意味着应该是%25,这里有两种做法:
1.将%换成%25,replace下,
2.这条数据既然出错了,我们就不要了
为什么要用“^A“分割,而不用“A”分割?因为单独用A会和实体内容混淆,当然^^也是可以的,只要分割的内容和我们实际的内容不会有冲突即可。

3.4.1、从Hbase中读取数据开始分析,输出Key的类型为总维度,输出Value的类型为Text(保存的是uuid)读取数据时,要验证数据有效性。
3.4.2、创建总维度对象,Text对象。
3.4.3、拼装维度
3.4.4、按照总维度聚合Text(uuid)
上面说了半天,维度是什么?
```java
str1[A,B,C,D]
str2[E,F,G,H]
str3[X,Y,Z]
for(A B C D){
for(E F G H){
for(X Y Z){
AEX
AEY
AEZ
AFX
...
}
}
}
```
如上,str1 str2 str3都是一个维度
或者
```java
List<时间维度> 3
List<品台维度> 3
List 2
List<浏览器维度> 2
```
3.5、NewInstallUserReducer.java
3.5.1、接受Mapper的数据,泛型分别为:StatsUserDimension, Text, StatsUserDimension, MapWritableValue
3.5.2、使用set集合去重uuid,并统计uuid的个数
3.5.3、将KPI名称和统计出来的个数做一个映射(使用MapWritableValue对象)
3.5.4、写出即可
3.6、NewInstallUserRunner.java:任务组装
3.6.1、ICollector.java:将数据最终插入到Mysql时用到的SQL语句的拼装接口
3.6.2、NewInstallUserCollector.java:拼装用于插入new_install_user表的SQL语句
3.6.3、BrowserNewInstallUserCollector.java:拼装用于插入browser_new_install_user表的SQL语句
3.6.4、IDimensionConverter.java:接口,通过维度对象(每个维度对象中保存着不同的维度数据),得到维度对应的维度id。
3.6.5、DimensionConverterImpl.java:接口的具体实现类
3.6.6、TransformerMySQLOutputFormat.java:自定义OutputFormat,用于将数据写入到Mysql中
* 自定义TransformerRecordWriter
Runner:
1 实例化Job Job.getIstance()
用户传递 -data 2015-12-20—>组装出:一系列HBase表名event_kigs20151201-event_logs20151231
InputFOrmat
HBaseInputFormate—>TableMapReduceUtil.initTableMapperJob
Mapper 上一步以做到
Reducer setReducerClass setOutputKeyClass setOutputValueClass
outputFormat — 自定义数、输出到mysql的outputFormat
2 提交任务等待结果
3 初始化方法的完善
INSERT INTo stats_user
platform dimension id
date dimension id
new install users
created
VALUES(?,?,?, ?)ON DUPLICATE KEY UPDATE new_install_users=?
2、根据传递出来的维度对象所封装的维度数据,反查维度表得到对应的维度id
3、如果反查,不存在,则创建一条新的记录,返回对应维度id
OutputForamt思路:
1、创建自定义 OutputForamt类,继承自 OutputForamt,泛型要和 Reduce的输出保持合法
2、创建 RecordWriter类的子类,覆写 write, close方法
3、在 getRecordwriter方法中,初始化JDBC的 Connection对象,传递给 Recordwriter构造器(因为在 RecodWriter类的 write方法中,要对 MYSQL进行操作)
4、组装Sq1语句
INSERT INTo stats user
created)
VALUES(?,?,?, ?)ON DUPLICATE KEY UPDATE new install_users=?
INSERT INTo stats device browser
platform dimension id
browser dimension_ id,
to回
031:48
VALUES(?,?, ?,?, ?)ON DUPLIC
0029:16