linux 多核启动
Linux kernel启动的过程概览
init/main.c:start_kernel()
|
\|/
init/main.c:rest_init
{
……
kernel_thread(kernel_init, NULL, CLONES_FS | CLONE_SIGHAND)
……
cpu_idle()
}
|
\|/
init/main.c:kernel_init//从上面代码可以看出,kernel_init是一个内核线程
|
\|/
init/main.c:init_post //会在最后调用启动脚本
{
……
823 /*
824 * We try each of these until one succeeds.
825 *
826 * The Bourne shell can be used instead of init if we are
827 * trying to recover a really broken machine.
828 */
829 if (execute_command) {
830 run_init_process(execute_command);
831 printk(KERN_WARNING "Failed to execute %s. Attempting "
832 "defaults...\n", execute_command);
833 }
834 run_init_process("/sbin/init");
835 run_init_process("/etc/init");
836 run_init_process("/bin/init");
837 run_init_process("/bin/sh");
838
839 panic("No init found. Try passing init= option to kernel.");
……
}
我们再来看看内核启动多核的详细过程。
init/main.c:start_kernel()
|
\|/
init/main.c:rest_init
{
……
kernel_thread(kernel_init, NULL, CLONES_FS | CLONE_SIGHAND)
……
}
|
\|/
kernel_init
|
\|/
/* called by boot processor to activate the rest */
init/main.c: smp_init()
{
……
for_each_present_cpu(cpu) {
if (num_onlien_cpus() >= setup_max_cpus)
break;
if ( !cpu_online(cpu))
cpu_up(cpu);
}
/* Any cleanup work */
printk(KERN_INFO "Brought up %ld CPUs\n", (long)num_online_cpus());
smp_cpu_done(setup_max_cpus);
……
}
--------------------------------------------------------------
cpu_up = native_cpu_up是一个回调函数。
注册地方是在:arch/x86/kernel/smp.c
struct smp_ops smp_ops = {
……
.cpu_up = native_cpu_up,
……
}
--------------------------------------------------------------
|
\|/
arch/x86/kernel/smpboot.c:native_cpu_up(unsigned int cpu)
|
\|/
arch/x86/kernel/smpboot.c: do_boot_cpu(int apicid, int cpu)
|
\|/
wakeup_secondary_cpu_via_init(apicid, start_ip)
在启动多核的过程中有两个bitmap很重要,一个是cpu_callin_mask,另一个是cpu_callout_mask。
cpu_callin_mask代表某个cpu是否已经启动,它的某个bit被与之对应的cpu在启动后置位,标记已经启动。
cpu_callout_mask在do_boot_cpu中被置位,并在检查到对应cpu已经启动后重新清零。
我们下面来详细看看do_boot_cpu(int apicid, int cpu)与wakeup_secondary_cpu_via_init(apicid, start_ip)
- /*
- * NOTE - on most systems this is a PHYSICAL apic ID, but on multiquad
- * (ie clustered apic addressing mode), this is a LOGICAL apic ID.
- * Returns zero if CPU booted OK, else error code from
- * ->wakeup_secondary_cpu.
- */
- static int __cpuinit do_boot_cpu(int apicid, int cpu)
- {
- unsigned long boot_error = 0;
- unsigned long start_ip;
- int timeout;
- struct create_idle c_idle = {
- .cpu = cpu,
- .done = COMPLETION_INITIALIZER_ONSTACK(c_idle.done),
- };
- INIT_WORK_ON_STACK(&c_idle.work, do_fork_idle);
- alternatives_smp_switch(1);
- c_idle.idle = get_idle_for_cpu(cpu);
- /*
- * We can't use kernel_thread since we must avoid to
- * reschedule the child.
- */
- if (c_idle.idle) {
- c_idle.idle->thread.sp = (unsigned long) (((struct pt_regs *)
- (THREAD_SIZE + task_stack_page(c_idle.idle))) - 1);
- init_idle(c_idle.idle, cpu);
- goto do_rest;
- }
- if (!keventd_up() || current_is_keventd())
- c_idle.work.func(&c_idle.work);
- else {
- schedule_work(&c_idle.work);
- wait_for_completion(&c_idle.done);
- }
- if (IS_ERR(c_idle.idle)) {
- printk("failed fork for CPU %d\n", cpu);
- destroy_work_on_stack(&c_idle.work);
- return PTR_ERR(c_idle.idle);
- }
- set_idle_for_cpu(cpu, c_idle.idle);
- do_rest:
- per_cpu(current_task, cpu) = c_idle.idle;
- #ifdef CONFIG_X86_32
- /* Stack for startup_32 can be just as for start_secondary onwards */
- irq_ctx_init(cpu);
- #else
- clear_tsk_thread_flag(c_idle.idle, TIF_FORK);
- initial_gs = per_cpu_offset(cpu);
- per_cpu(kernel_stack, cpu) =
- (unsigned long)task_stack_page(c_idle.idle) -
- KERNEL_STACK_OFFSET + THREAD_SIZE;
- #endif
- early_gdt_descr.address = (unsigned long)get_cpu_gdt_table(cpu);
- initial_code = (unsigned long)start_secondary;
- stack_start.sp = (void *) c_idle.idle->thread.sp;
- /* start_ip had better be page-aligned! */
- start_ip = setup_trampoline();
- /* So we see what's up */
- announce_cpu(cpu, apicid);
- /*
- * This grunge runs the startup process for
- * the targeted processor.
- */
- atomic_set(&init_deasserted, 0);
- if (get_uv_system_type() != UV_NON_UNIQUE_APIC) {
- pr_debug("Setting warm reset code and vector.\n");
- smpboot_setup_warm_reset_vector(start_ip);
- /*
- * Be paranoid about clearing APIC errors.
- */
- if (APIC_INTEGRATED(apic_version[boot_cpu_physical_apicid])) {
- apic_write(APIC_ESR, 0);
- apic_read(APIC_ESR);
- }
- }
- /*
- * Kick the secondary CPU. Use the method in the APIC driver
- * if it's defined - or use an INIT boot APIC message otherwise:
- */
- if (apic->wakeup_secondary_cpu)
- boot_error = apic->wakeup_secondary_cpu(apicid, start_ip);
- else
- boot_error = wakeup_secondary_cpu_via_init(apicid, start_ip);
- if (!boot_error) {
- /*
- * allow APs to start initializing.
- */
- pr_debug("Before Callout %d.\n", cpu);
- cpumask_set_cpu(cpu, cpu_callout_mask);
- pr_debug("After Callout %d.\n", cpu);
- /*
- * Wait 5s total for a response
- */
- for (timeout = 0; timeout < 50000; timeout++) {
- if (cpumask_test_cpu(cpu, cpu_callin_mask))
- break; /* It has booted */
- udelay(100);
- }
- if (cpumask_test_cpu(cpu, cpu_callin_mask))
- pr_debug("CPU%d: has booted.\n", cpu);
- else {
- boot_error = 1;
- if (*((volatile unsigned char *)trampoline_base)
- == 0xA5)
- /* trampoline started but...? */
- pr_err("CPU%d: Stuck ??\n", cpu);
- else
- /* trampoline code not run */
- pr_err("CPU%d: Not responding.\n", cpu);
- if (apic->inquire_remote_apic)
- apic->inquire_remote_apic(apicid);
- }
- }
- if (boot_error) {
- /* Try to put things back the way they were before ... */
- numa_remove_cpu(cpu); /* was set by numa_add_cpu */
- /* was set by do_boot_cpu() */
- cpumask_clear_cpu(cpu, cpu_callout_mask);
- /* was set by cpu_init() */
- cpumask_clear_cpu(cpu, cpu_initialized_mask);
- set_cpu_present(cpu, false);
- per_cpu(x86_cpu_to_apicid, cpu) = BAD_APICID;
- }
- /* mark "stuck" area as not stuck */
- *((volatile unsigned long *)trampoline_base) = 0;
- if (get_uv_system_type() != UV_NON_UNIQUE_APIC) {
- /*
- * Cleanup possible dangling ends...
- */
- smpboot_restore_warm_reset_vector();
- }
- destroy_work_on_stack(&c_idle.work);
- return boot_error;
- }
- /*
- * Currently trivial. Write the real->protected mode
- * bootstrap into the page concerned. The caller
- * has made sure it's suitably aligned.
- */
- unsigned long __trampinit setup_trampoline(void)
- {
- memcpy(trampoline_base, trampoline_data, TRAMPOLINE_SIZE);
- return virt_to_phys(trampoline_base);
- }
可以从上面代码中看出do_boot_cpu会为编号为apicid的AP设定好它将要使用的stack以及它将要执行的代码start_eip,在完成这些后,通过发送IPI序列来启动AP,
并会将cpu_callout_mask的代表相应AP的位清零。
- static int __cpuinit
- wakeup_secondary_cpu_via_init(int phys_apicid, unsigned long start_eip)
- {
- unsigned long send_status, accept_status = 0;
- int maxlvt, num_starts, j;
- maxlvt = lapic_get_maxlvt();
- /*
- * Be paranoid about clearing APIC errors.
- */
- if (APIC_INTEGRATED(apic_version[phys_apicid])) {
- if (maxlvt > 3) /* Due to the Pentium erratum 3AP. */
- apic_write(APIC_ESR, 0);
- apic_read(APIC_ESR);
- }
- pr_debug("Asserting INIT.\n");
- /*
- * Turn INIT on target chip
- */
- /*
- * Send IPI
- */
- apic_icr_write(APIC_INT_LEVELTRIG | APIC_INT_ASSERT | APIC_DM_INIT,
- phys_apicid);
- pr_debug("Waiting for send to finish...\n");
- send_status = safe_apic_wait_icr_idle();
- mdelay(10);
- pr_debug("Deasserting INIT.\n");
- /* Target chip */
- /* Send IPI */
- apic_icr_write(APIC_INT_LEVELTRIG | APIC_DM_INIT, phys_apicid);
- pr_debug("Waiting for send to finish...\n");
- send_status = safe_apic_wait_icr_idle();
- mb();
- atomic_set(&init_deasserted, 1);
- /*
- * Should we send STARTUP IPIs ?
- *
- * Determine this based on the APIC version.
- * If we don't have an integrated APIC, don't send the STARTUP IPIs.
- */
- if (APIC_INTEGRATED(apic_version[phys_apicid]))
- num_starts = 2;
- else
- num_starts = 0;
- /*
- * Paravirt / VMI wants a startup IPI hook here to set up the
- * target processor state.
- */
- startup_ipi_hook(phys_apicid, (unsigned long) start_secondary,
- (unsigned long)stack_start.sp);
- /*
- * Run STARTUP IPI loop.
- */
- pr_debug("#startup loops: %d.\n", num_starts);
- for (j = 1; j <= num_starts; j++) {
- pr_debug("Sending STARTUP #%d.\n", j);
- if (maxlvt > 3) /* Due to the Pentium erratum 3AP. */
- apic_write(APIC_ESR, 0);
- apic_read(APIC_ESR);
- pr_debug("After apic_write.\n");
- /*
- * STARTUP IPI
- */
- /* Target chip */
- /* Boot on the stack */
- /* Kick the second */
- apic_icr_write(APIC_DM_STARTUP | (start_eip >> 12),
- phys_apicid);
- /*
- * Give the other CPU some time to accept the IPI.
- */
- udelay(300);
- pr_debug("Startup point 1.\n");
- pr_debug("Waiting for send to finish...\n");
- send_status = safe_apic_wait_icr_idle();
- /*
- * Give the other CPU some time to accept the IPI.
- */
- udelay(200);
- if (maxlvt > 3) /* Due to the Pentium erratum 3AP. */
- apic_write(APIC_ESR, 0);
- accept_status = (apic_read(APIC_ESR) & 0xEF);
- if (send_status || accept_status)
- break;
- }
- pr_debug("After Startup.\n");
- if (send_status)
- printk(KERN_ERR "APIC never delivered???\n");
- if (accept_status)
- printk(KERN_ERR "APIC delivery error (%lx).\n", accept_status);
- return (send_status | accept_status);
- }
一段wakeup_secondary_cpu_via_init执行的log
- 656 CPU17: has booted.
- 657 WP output: cpu :18
- 658 ------native_cpu_up cpu:18, apicid:18----------
- 659 ------------in 3 do_boot_cpu------- #18
- 660 Asserting INIT.
- 661 Waiting for send to finish...
- 662 Deasserting INIT.
- 663 Waiting for send to finish...
- 664 #startup loops: 2.
- 665 Sending STARTUP #1.
- 666 After apic_write.
- 667 Startup point 1.
- 668 Waiting for send to finish...
- 669 Sending STARTUP #2.
- 670 After apic_write.
- 671 Startup point 1.
- 672 Waiting for send to finish...
- 673 in the cpu_init())
- 674 After Startup.
- 675 Before Callout 18.
- 676 After Callout 18.
- 677 cpu is: 12
- 678 in the enable_x2apic()
- 679 ------in x2apic_phys_get_apic_id-----
- 680 CPU#18 (phys ID: 18) waiting for CALLOUT
- 681 CALLIN, before setup_local_APIC().
- 682 ------3------
- 683 Stack at about ffff88021f953f44
- 684 ------in x2apic_phys_get_apic_id-----
- 685 CPU18: has booted.
wakeup_secondary_cpu_via_init是与硬件相关的代码,它的主要作用是通过发送INIT-INIT-Startup IPI序列来将AP从halted的状态唤醒并让它开始执行代码start_eip所指向的代码。
Startup IPI会有一个域来指定需要执行代码的地址:apic_icr_write(APIC_DM_STARTUP | (start_eip >> 12), phys_apicid);
如果想彻底搞清楚一段代码,请去看Intel文档。
start_secondary是AP会执行的代码,这段代码通过smp_callin来将设定cpu_callin_mask来告诉BSP它已经启动。start_secondary最后是idle循环。
- /*
- * Activate a secondary processor.
- */
- notrace static void __cpuinit start_secondary(void *unused)
- {
- /*
- * Don't put *anything* before cpu_init(), SMP booting is too
- * fragile that we want to limit the things done here to the
- * most necessary things.
- */
- vmi_bringup();
- cpu_init();
- preempt_disable();
- smp_callin();
- /* otherwise gcc will move up smp_processor_id before the cpu_init */
- barrier();
- /*
- * Check TSC synchronization with the BP:
- */
- check_tsc_sync_target();
- if (nmi_watchdog == NMI_IO_APIC) {
- disable_8259A_irq(0);
- enable_NMI_through_LVT0();
- enable_8259A_irq(0);
- }
- #ifdef CONFIG_X86_32
- while (low_mappings)
- cpu_relax();
- __flush_tlb_all();
- #endif
- /* This must be done before setting cpu_online_mask */
- set_cpu_sibling_map(raw_smp_processor_id());
- wmb();
- /*
- * We need to hold call_lock, so there is no inconsistency
- * between the time smp_call_function() determines number of
- * IPI recipients, and the time when the determination is made
- * for which cpus receive the IPI. Holding this
- * lock helps us to not include this cpu in a currently in progress
- * smp_call_function().
- *
- * We need to hold vector_lock so there the set of online cpus
- * does not change while we are assigning vectors to cpus. Holding
- * this lock ensures we don't half assign or remove an irq from a cpu.
- */
- ipi_call_lock();
- lock_vector_lock();
- __setup_vector_irq(smp_processor_id());
- set_cpu_online(smp_processor_id(), true);
- unlock_vector_lock();
- ipi_call_unlock();
- per_cpu(cpu_state, smp_processor_id()) = CPU_ONLINE;
- /* enable local interrupts */
- local_irq_enable();
- x86_cpuinit.setup_percpu_clockev();
- wmb();
- cpu_idle();
- }
[置顶] ARM多核处理器启动过程分析
转至:http://blog.csdn.net/qianlong4526888/article/details/27695173
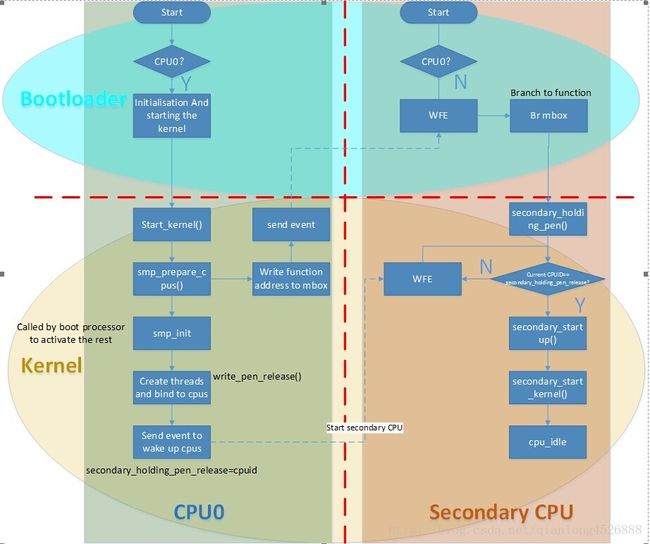
说明:
该流程图按照代码执行时间顺序划分为4部分:
1. Bootloader在图片上半部,最先启动;
2. Kernel在图片下半部,由bootloader引导启动;
3.CPU0执行流程在图片左半部,bootloader代码会进行判断,先行启动CPU0;
4. Secondary CPUs在图片右半部,由CPU唤醒
具体启动流程如下:
1. 在bootloader启动时,会判断执行代码的是否为CPU0,如果不是,则执行wfe等待CPU0发出sev指令唤醒。如果是CPU0,则继续进行初始化工作。
mrs x4,mpidr_el1
tst x4,#15 //testwether the current cpu is CPU0, ie. mpidr_el1=15
b.eq 2f
/*
* Secondary CPUs
*/
1: wfe
ldr x4, mbox
cbz x4, 1b //if x4==0(ie. The value in address of mbox is 0) dead loop,or jump to x4
br x4 // branch to thegiven address
2:…… //UART initialisation (38400 8N1)
以上mbox的地址在Makefile中写定,是0x8000fff8,该地址处初始状态内容为全0。上面代码判断,若mbox地址处内容为0,则死循环;如果不为0则直接跳转到该地址所包含内容处执行。
2. 在dts中,对cpu-release-addr进行赋值,将其地址设为0x8000fff8。即只要往该地址写入相应的值,例如地址A,并且发送sev指令,就能将次级CPU唤醒,并跳转到A地址处执行。
cpu-release-addr = <0x0 0x8000fff8>;
3. 内核中smp_prepare_cpus 函数对0x8000fff8地址处内容进行了赋值,其值为函数secondary_holding_pen 的地址:
release_addr = __va(cpu_release_addr[cpu]);
release_addr[0] = (void*)__pa(secondary_holding_pen);//write function address to mbox
以上代码执行完后发送sev指令,唤醒其他次级CPU执行secondary_holding_pen函数:
/*
* Send an event to wake up the secondaries.
*/
sev();
4. secondary cpu 执行secondary_holding_pen()函数时都会去判断当前CPU的ID,并与secondary_holding_pen_release变量做比对,如果相等,则执行进一步初始化,否则执行WFE等待;
secondary_holding_pen_release变量的修改过程由CPU0调用smp_init()函数进行。该函数首先为相应CPU绑定一个idle线程,然后修改secondary_holding_pen_release的值(其值即CPU0欲唤醒的CPU的ID),最后发送sev指令,唤醒相应CPU执行idle线程。
secondary_holding_pen()函数代码如下:
/*
* This provides a"holding pen" for platforms to hold all secondary
* cores are helduntil we're ready for them to initialise.
*/
ENTRY(secondary_holding_pen)
bl el2_setup // Drop to EL1
mrs x0, mpidr_el1
and x0, x0, #15 // CPU number
adr x1, 1b
ldp x2, x3, [x1]
sub x1, x1, x2
add x3, x3, x1
pen: ldr x4, [x3]
cmp x4,x0
b.eq secondary_startup
wfe
b pen
ENDPROC(secondary_holding_pen)
附录:
内核中启动secondary cpus函数调用过程大致如下:
start_kernel èrest_initèkernel_inièkernel_init_freeable èsmp_init() kernel/smp.c line 649, 由CPU0激活剩余的处理器
cpu_upè_cpu_up()è__cpu_up ()èboot_secondary ()èwrite_pen_release该函数中有一句:secondary_holding_pen_release = val; 然后发送sev指令,激活剩余处理器。
linux SMP多核启动分析
startup_32:
cld //决定内存地址的增长方向DF = xx ,与STD对立
cli //禁止中断
movl $(KERNEL_DS),%eax
mov %ax,%ds
mov %ax,%es
mov %ax,%fs
mov %ax,%gs
#ifdef __SMP__
orw %bx,%bx # What state are we in BX=1 for SMP
# 0 for boot
jz 2f # Initial boot
//根据bx值指示是主cpu(bx=0)还是次cpu(bx=1)
//然后会有不同的执行路径
/*
* We are trampolining an SMP processor
*//这里是其他次cpu执行路径
mov %ax,%ss
xorl %eax,%eax # Back to 0
mov %cx,%ax # SP low 16 bits
movl %eax,%esp
pushl 0 # Clear NT
popfl
ljmp $(KERNEL_CS), $0x100000 # Into C and sanity
2://这里是主cpu的执行路径
#endif
lss SYMBOL_NAME(stack_start),%esp
xorl %eax,%eax
1: incl %eax # check that A20 really IS enabled
movl %eax,0x000000 # loop forever if it isn't
cmpl %eax,0x100000
je 1b
/*
* Initialize eflags. Some BIOS's leave bits like NT set. This would
* confuse the debugger if this code is traced.
* XXX - best to initialize before switching to protected mode.
*/
pushl $0
popfl
/*
* Clear BSS
*/
xorl %eax,%eax
movl $ SYMBOL_NAME(_edata),%edi
movl $ SYMBOL_NAME(_end),%ecx
subl %edi,%ecx
cld
rep
stosb
/*
* Do the decompression, and jump to the new kernel..
*/
subl $16,%esp # place for structure on the stack
pushl %esp # address of structure as first arg
call SYMBOL_NAME(decompress_kernel)
orl %eax,%eax
jnz 3f
xorl %ebx,%ebx
ljmp $(KERNEL_CS), $0x100000
ljmp $(KERNEL_CS), $0x100000
这个其实就是跳到start_kernel函数。
asmlinkage void start_kernel(void)
{
char * command_line;
/*
* This little check will move.
*/
#ifdef __SMP__
static int first_cpu=1;
//这个不是函数局部变量,是函数静态变量,主cpu执行这个函数时复位为1,其他cpu为0,因为主cpu总是第一个执行这个函数的。
if(!first_cpu)
start_secondary();
//对于
first_cpu=0;
#endif
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
setup_arch(&command_line, &memory_start, &memory_end);
memory_start = paging_init(memory_start,memory_end);
trap_init();
init_IRQ();
sched_init();
time_init();
parse_options(command_line);
#ifdef CONFIG_MODULES
init_modules();
#endif
#ifdef CONFIG_PROFILE
if (!prof_shift)
#ifdef CONFIG_PROFILE_SHIFT
prof_shift = CONFIG_PROFILE_SHIFT;
#else
prof_shift = 2;
#endif
#endif
if (prof_shift) {
prof_buffer = (unsigned int *) memory_start;
/* only text is profiled */
prof_len = (unsigned long) &_etext - (unsigned long) &_stext;
prof_len >>= prof_shift;
memory_start += prof_len * sizeof(unsigned int);
}
memory_start = console_init(memory_start,memory_end);
#ifdef CONFIG_PCI
memory_start = pci_init(memory_start,memory_end);
#endif
memory_start = kmalloc_init(memory_start,memory_end);
sti();
calibrate_delay();
memory_start = inode_init(memory_start,memory_end);
memory_start = file_table_init(memory_start,memory_end);
memory_start = name_cache_init(memory_start,memory_end);
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && initrd_start < memory_start) {
printk(KERN_CRIT "initrd overwritten (0x%08lx < 0x%08lx) - "
"disabling it.\n",initrd_start,memory_start);
initrd_start = 0;
}
#endif
mem_init(memory_start,memory_end);
buffer_init();
sock_init();
#if defined(CONFIG_SYSVIPC) || defined(CONFIG_KERNELD)
ipc_init();
#endif
dquot_init();
arch_syms_export();
sti();
check_bugs();
printk(linux_banner);
#ifdef __SMP__
smp_init();
#endif
sysctl_init();
/*
* We count on the initial thread going ok
* Like idlers init is an unlocked kernel thread, which will
* make syscalls (and thus be locked).
*/
kernel_thread(init, NULL, 0);
/*
* task[0] is meant to be used as an "idle" task: it may not sleep, but
* it might do some general things like count free pages or it could be
* used to implement a reasonable LRU algorithm for the paging routines:
* anything that can be useful, but shouldn't take time from the real
* processes.
*
* Right now task[0] just does a infinite idle loop.
*/
cpu_idle(NULL);
}
asmlinkage void start_secondary(void)
{
trap_init();
init_IRQ();
//初始化自己的irq
smp_callin();
//这个等待主cpu给大家发送开始信号
cpu_idle(NULL);
//这个是ide进程。
}
void smp_callin(void)
{
extern void calibrate_delay(void);
int cpuid=GET_APIC_ID(apic_read(APIC_ID));
unsigned long l;
/*
* Activate our APIC
*/
SMP_PRINTK(("CALLIN %d\n",smp_processor_id()));
l=apic_read(APIC_SPIV);
l|=(1<<8); /* Enable */
apic_write(APIC_SPIV,l);
sti();
/*
* Get our bogomips.
*/
calibrate_delay();
/*
* Save our processor parameters
*/
smp_store_cpu_info(cpuid);
/*
* Allow the master to continue.
*/
set_bit(cpuid, (unsigned long *)&cpu_callin_map[0]);
/*
* Until we are ready for SMP scheduling
*/
load_ldt(0);
/* printk("Testing faulting...\n");
*(long *)0=1; OOPS... */
local_flush_tlb();
while(!smp_commenced);
//这个可以看成是自旋锁,等待主cpu发smp_commenced信号即开始信号。
if (cpu_number_map[cpuid] == -1)
while(1);
local_flush_tlb();
SMP_PRINTK(("Commenced..\n"));
load_TR(cpu_number_map[cpuid]);
/* while(1);*/
}
int cpu_idle(void *unused)
{
for(;;)
idle();
}
主cpu给各次cpu发开始信号是在init函数中调用smp_begin函数:
static void smp_begin(){
smp_threads_ready=1;
smp_commence();
//这个会通过IPI给各个次cpu发送相关中断来通信
}
每个cpu有一个current指针。
刚开始的时候由主cpu赋值为init_task;
在主cpu调用 sched_init赋值。
void sched_init(void)
{
/*
* We have to do a little magic to get the first
* process right in SMP mode.
*/
int cpu=smp_processor_id();//这个为0,因为是主cpu才调用。
#ifndef __SMP__
current_set[cpu]=&init_task;
#else
init_task.processor=cpu;
//这个是将init_task标志为主cpu在运行。
for(cpu = 0; cpu < NR_CPUS; cpu++)
current_set[cpu] = &init_task;
#endif
init_bh(TIMER_BH, timer_bh);
init_bh(TQUEUE_BH, tqueue_bh);
init_bh(IMMEDIATE_BH, immediate_bh);
}
同时这些还会在 smp_init丰富。
static void smp_init(void)
{
int i, j;
smp_boot_cpus();
/*
* Create the slave init tasks as sharing pid 0.
*
* This should only happen if we have virtual CPU numbers
* higher than 0.
*/
for (i=1; i
{
struct task_struct *n, *p;
j = cpu_logical_map[i];
/*
* We use kernel_thread for the idlers which are
* unlocked tasks running in kernel space.
*/
kernel_thread(cpu_idle, NULL, CLONE_PID);
//这个其实就是创建线程然后这个线程体现在task[i]上了,因为创建的时候的task_struct就是从task[i]取的。
/*
* Don't assume linear processor numbering
*/
current_set[j]=task[i];
current_set[j]->processor=j;
cli();
n = task[i]->next_run;
p = task[i]->prev_run;
nr_running--;
n->prev_run = p;
p->next_run = n;
task[i]->next_run = task[i]->prev_run = task[i];
sti();
}
}
上面执行完后就给每个cpu加了一个idle任务。
然后kernel_thread(init, NULL, 0)创建的init任务。
//每个cpu在时间中断时都可能调用这个共同的函数。
asmlinkage void schedule(void)
{
int c;
struct task_struct * p;
struct task_struct * prev, * next;
unsigned long timeout = 0;
int this_cpu=smp_processor_id();
//获取cpu_id;
/* check alarm, wake up any interruptible tasks that have got a signal */
if (intr_count)
goto scheduling_in_interrupt;
if (bh_active & bh_mask) {
intr_count = 1;
do_bottom_half();
intr_count = 0;
}
run_task_queue(&tq_scheduler);
need_resched = 0;
prev = current;
cli();
/* move an exhausted RR process to be last.. */
if (!prev->counter && prev->policy == SCHED_RR) {
prev->counter = prev->priority;
move_last_runqueue(prev);
}
switch (prev->state) {
case TASK_INTERRUPTIBLE:
if (prev->signal & ~prev->blocked)
goto makerunnable;
timeout = prev->timeout;
if (timeout && (timeout <= jiffies)) {
prev->timeout = 0;
timeout = 0;
makerunnable:
prev->state = TASK_RUNNING;
break;
}
default:
del_from_runqueue(prev);
case TASK_RUNNING:
}
p = init_task.next_run;
//获取进程双向链表的一个节点。
sti();
#ifdef __SMP__
/*
* This is safe as we do not permit re-entry of schedule()
*/
prev->processor = NO_PROC_ID;
#define idle_task (task[cpu_number_map[this_cpu]])
#else
#define idle_task (&init_task)
#endif
/*
* Note! there may appear new tasks on the run-queue during this, as
* interrupts are enabled. However, they will be put on front of the
* list, so our list starting at "p" is essentially fixed.
*/
/* this is the scheduler proper: */
c = -1000;
next = idle_task;
while (p != &init_task) {
//p初始值为init_task.next_run
//当回到init_task时说明已经查找为所有的了。
int weight = goodness(p, prev, this_cpu);
if (weight > c)
c = weight, next = p;
p = p->next_run;
}
//这个是查找所有的task,找出最合适的task来调度。
/* if all runnable processes have "counter == 0", re-calculate counters */
if (!c) {
for_each_task(p)
p->counter = (p->counter >> 1) + p->priority;
}
#ifdef __SMP__
/*
* Allocate process to CPU
*/
next->processor = this_cpu;
//将这个将要被执行的processor标识为这个cpu
next->last_processor = this_cpu;
#endif
#ifdef __SMP_PROF__
/* mark processor running an idle thread */
if (0==next->pid)
set_bit(this_cpu,&smp_idle_map);
else
clear_bit(this_cpu,&smp_idle_map);
#endif
if (prev != next) {
struct timer_list timer;
kstat.context_swtch++;
if (timeout) {
init_timer(&timer);
timer.expires = timeout;
timer.data = (unsigned long) prev;
timer.function = process_timeout;
add_timer(&timer);
}
get_mmu_context(next);
switch_to(prev,next);
if (timeout)
del_timer(&timer);
}
return;
scheduling_in_interrupt:
printk("Aiee: scheduling in interrupt %p\n",
__builtin_return_address(0));
}
上面需要注意的是current变量,在单核中肯定就是一个变量,在多核中肯定是各个cpu有自己的current:
其定义如下:
#define current (0+current_set[smp_processor_id()]
在smp中current是current_set数组中的一个元素,是指具体一个cpu的当前进程。
从上面可以看出一个cpu是从全局task找一个task来运行,每个cpu有一个idle_task,这个task的编号是固定的。
所有的task可以通过init_task来找到,因为创建新进程(内核线程)的时候,会将新建的挂到链表上。
而init_task是静态挂在这上面的。
附上task_struct:
struct task_struct {
/* these are hardcoded - don't touch */
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
unsigned long signal;
unsigned long blocked; /* bitmap of masked signals */
unsigned long flags; /* per process flags, defined below */
int errno;
long debugreg[8]; /* Hardware debugging registers */
struct exec_domain *exec_domain;
/* various fields */
struct linux_binfmt *binfmt;
struct task_struct *next_task, *prev_task;
struct task_struct *next_run, *prev_run;
unsigned long saved_kernel_stack;
unsigned long kernel_stack_page;
int exit_code, exit_signal;
/* ??? */
unsigned long personality;
int dumpable:1;
int did_exec:1;
/* shouldn't this be pid_t? */
int pid;
int pgrp;
int tty_old_pgrp;
int session;
/* boolean value for session group leader */
int leader;
int groups[NGROUPS];
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->p_pptr->pid)
*/
struct task_struct *p_opptr, *p_pptr, *p_cptr, *p_ysptr, *p_osptr;
struct wait_queue *wait_chldexit; /* for wait4() */
unsigned short uid,euid,suid,fsuid;
unsigned short gid,egid,sgid,fsgid;
unsigned long timeout, policy, rt_priority;
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
struct timer_list real_timer;
long utime, stime, cutime, cstime, start_time;
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1;
unsigned long swap_address;
unsigned long old_maj_flt; /* old value of maj_flt */
unsigned long dec_flt; /* page fault count of the last time */
unsigned long swap_cnt; /* number of pages to swap on next pass */
/* limits */
struct rlimit rlim[RLIM_NLIMITS];
unsigned short used_math;
char comm[16];
/* file system info */
int link_count;
struct tty_struct *tty; /* NULL if no tty */
/* ipc stuff */
struct sem_undo *semundo;
struct sem_queue *semsleeping;
/* ldt for this task - used by Wine. If NULL, default_ldt is used */
struct desc_struct *ldt;
/* tss for this task */
struct thread_struct tss;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* memory management info */
struct mm_struct *mm;
/* signal handlers */
struct signal_struct *sig;
#ifdef __SMP__
int processor;
int last_processor;
int lock_depth; /* Lock depth. We can context switch in and out of holding a syscall kernel lock... */
#endif
};
故这个p = init_task.next_run;
p可以获取到所有在就绪状态的task;