数据预处理(2) ——数据变换与数据离散化 使用python(sklearn,pandas,numpy)实现
数据预处理的主要任务有:
一、数据预处理
1.数据清洗
2.数据集成
3.数据转换
4.数据归约
3.数据变换
数据变换是指将数据转换或统一成适合于挖掘的形式。
(1)数据泛化:使用概念分层,用高层概念替换低层或“原始”数据。例如,分类的属性,如街道,可以泛化为较高层的概念,如城市或国家。
使用时根据自己需求,自己写代码实现
(2)规范化:将属性数据按比例缩放,使之落入一个小的特定区间。大致可分三种:最小最大规范化、z-score规范化和按小数定标规范化。
2.1 最小最大规范化
from sklearn.preprocessing import MinMaxScaler
M=MinMaxScaler()
data2=M.fit_transform(data)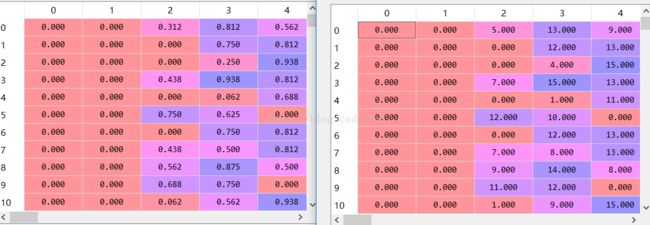
2.2 z-score规范化
from sklearn.preprocessing import StandardScaler
S=StandardScaler()
data1=S.fit_transform(data)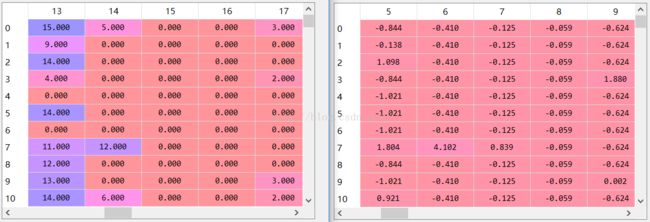
2.3 小数定标规范化
举个栗子:假设A取值由-986到917。A的最大绝对值为986 。因此,为使用小数定标规范化,我们用1000除每个值。-986被规范化到-0.986
(3)属性构造:可以构造新的属性并添加到属性集中,以帮助挖掘过程。例如,可能希望根据属性height和width添加属性area。通过属性构造可以发现关于数据属性间联系的丢失信息,这对知识发现是有用的。
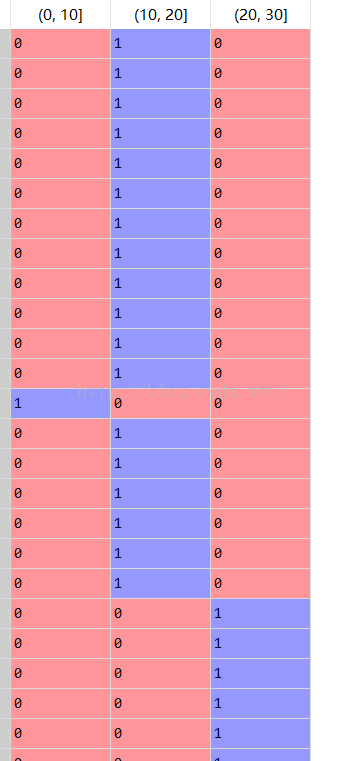
(4)离散化:数值属性(例如:年龄)的原始值用区间标签(0-10,11-20等)代替。
x=[1,1,5,5,5,5,8,8,10,10,10,10,14,14,14,14,15,15,15,15,15,15,18,18,18,18,18,18,18,18,18,20,2,20,20,20,20,20,20,21,21,21,25,25,25,25,25,28,28,30,30,30]
x=pd.Series(x)
s=pd.cut(x,bins=[0,10,20,30])
d=pd.get_dummies(s)这里采用了哑编码,用OneHotEncoder也可以实现哑编码
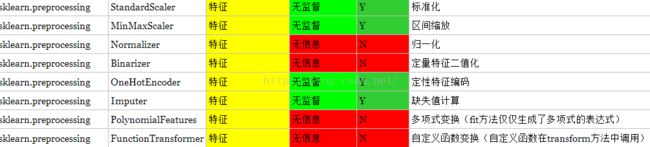
sklearn的preprocessing预处理方法参考http://blog.csdn.net/nkwangjie/article/details/17471889
参考文献:
http://www.cnblogs.com/jasonfreak/p/5448462.html