【原创】巧解KMP算法,循序渐进,看我是怎么自己写一个出来的
作者:DCTANT
如需转载请说明出处!
KMP算法的关键在于如何省时间,怎么减少重复匹配的次数。
这还不简单,与其每个都傻乎乎的比较,不如直接就判断个首字母,首字母不同还比什么,直接跳过,也就等于matchIndex+1。
经过漫长的首字母匹配,终于找到首字母一样的了,然后才开始匹配,既然比都开始比了,总不能什么成果都不留下吧,这也太浪费电脑资源了,当发现某个字符不同时,记录下之前已经匹配完成多少个了,下次比较直接跳过这些个数不就行了!当然这会存在一些问题,我之后再说,先拿个最简单字符串举个例子:
主字符串:FFFDXTTTDCGDCT
匹配串:DCT
匹配开始,首先就去找D呗,发现D的index在3,那么matchIndex就是3,且从index4的X开始匹配,因为D已经知道一样了,不需要在比较了。接着就是X和C的比较,发现这两个不一样了,怎么办呢?matchIndex向右移呗,移几位呢?移一位呗(后面能够优化,再说)matchIndex变为4,D和X(index为4)开始比较。
然后就又是继续找D的过程了,发现index为8的地方有个D,那么匹配继续开始了,C和C(index为9)比较发现一样,成果+1,T和G(index为10)比较,发现不同了!那么matchIndex应该向后移几位呢?如果移1位,那就太辜负电脑做出的匹配尝试了,明显知道C和C都匹配上了,可能再与D进行匹配了,后移数量应该是1+成果数(如果这么盲目移会导致问题,下面会说)。matchIndex+2,目前为D和G(index为10)开始比较。
然后就又是继续找D的过程了,发现index为11的地方有个D,那么匹配继续开始了,C和C(index为12)比较发现一样,成果+1,T和T(index为13)比较发现一样,成果再+1。匹配串遍历完成,发现成果数量等于匹配串总长度-1,说明匹配成功!matchIndex即11。
完整图,包括匹配后失败的第一次匹配:
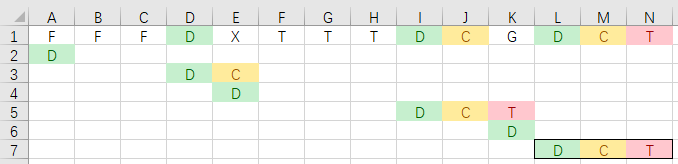
省略匹配失败后的第一次匹配,图为(这样看起来更简洁):

如果以上理解了,那么恭喜你,KMP算法基本上懂了80%了。但是这么盲目移动会导致一个问题——移过头了!!
就拿KMP算法网上最经典的例子来说:
主字符串:BBC ABCDAB ABCDABCDABDE
匹配串:ABCDABD
首先最简单的,找A呗!注意:BBC和ABCD之间有个空格,ABCDAB和ABCDABCDABDE之间也有个空格。
首先找到A在index为4的位置,matchIndex等于4,然后比较开始,B和B(index为5)比,成果+1,C和C(index为6)比,成果+1,一直比到D和空格(index为10),发现不同了,按照之前的做法,matchIndex下一次比较的位置为1+成果数,这里的成果数为5,即BCDAB五个字符是相同的,matchIndex为10(4+1+5),即A开始和空格(index为10)开始比较。
然后就又是继续找A的过程了,发现index为11的地方有个A,那么匹配继续开始了,重复上述过程,发现C(index为17)和D不同,成果数为5,即BCDAB五个字符,matchIndex为17(11+1+5),即A和C(index为17)开始比。
然后就又是继续找A的过程了,发现index为19的地方有个A,那么匹配继续开始了,结果发现主串剩余长度还没匹配串的长,说明匹配失败了!!这样问题不就大了,很明显代码写错了!!问题的根源就在于移过头了,matchIndex移太快了,完全没有考虑到被匹配串中(ABCDABD)的也有和匹配串头字符(A)一样的元素,即有两个A!!问题找到了,那么就很好解决了。
完整图为,包括匹配后失败的第一次匹配:

省略匹配失败后的第一次匹配,图为(这样看起来更简洁):

如果(if)被配匹配的字符串(假设为ABCDBBD)中仅包含一个匹配字符串(ABCDABD)的首字符(A),则按照原来的做法,移动最大长度即1+成果数
如果(else)被配匹配的字符串(假设为ABCDABC)中包含多个(两个A)匹配字符串的首字符(A),那么移动的最大长度为这个第二个首字符出现的位置,即1+第二个首字符的index,上面的例子为5,并非成果数。那么问题就解决了,图片演变为:

问题完美解决了,KMP算法也就诞生了,其实过程非常之简单,结果这东西在网上被描绘成洪水猛兽一般,让人难以理解。我在大学上课就没搞懂,书上反反复复看了几遍也没看懂,网上教程翻了又翻,也都说的不是人话。结果昨天失眠,晚上随便想想,突然就想明白了!其实真的非常简单,哪有什么难的啊。只是老师不会教,书上不会写罢了。
当然这里还有一个稍微可以再优化那么一点点的地方,就是如果匹配串失败后最后一个字符和首字符如果不同,例如示例1中的FFFDXT和DCT中的C不匹配,且X和D并不相同,移动的数量应该为1还能再加1,下一次匹配完全可以是D和T匹配,而不是D再和X去匹配,本质其实是相同的,即使有多移这么一位,性能变化也是微乎其微。
然后就是上代码,代码去掉注释后,真的很短啊!
代码注释非常详细,相信你们都能看懂:
public class StringMatcher {
/**
* 字符串匹配方法
*
* @param totalString 字符串主串
* @param matchString 匹配串
* @return
*/
public int matcher(String totalString, String matchString) {
int matchIndex = 0; // INFO: DCTANT: 2019/9/8 匹配起始点
char[] matchCharArray = matchString.toCharArray();
char[] totalCharArray = totalString.toCharArray();
char matchHeadChar = matchCharArray[0]; // INFO: DCTANT: 2019/9/8 匹配串首字符
while (true) {
if (matchIndex + matchCharArray.length - 1 > totalCharArray.length) {
// INFO: DCTANT: 2019/9/8 防止下标越界,标记匹配结束
break;
}
char charInString = totalCharArray[matchIndex];
if (charInString == matchHeadChar) {
// INFO: DCTANT: 2019/9/8 首字符相等才会开始匹配工作
int continueTimes = 1; // INFO: DCTANT: 2019/9/8 总共连续次数(成果数),最少都得移1次
int sameHeadCharIndex = -1; // INFO: DCTANT: 2019/9/8 被匹配的字符串中是否存在和匹配串首字符相同的字符
for (int i = 1; i < matchCharArray.length; i++) { // INFO: DCTANT: 2019/9/8 i为1,匹配串去头开始比较比较,因为能进这个if,说明首字符已经相同了
char matchStringChar = matchCharArray[i];
char totalStringChar = totalCharArray[matchIndex + i];
if (totalStringChar == matchHeadChar && sameHeadCharIndex == -1) {
// INFO: DCTANT: 2019/9/8 查找被匹配的字符串中是否存在和首字符相同的值
sameHeadCharIndex = continueTimes;
}
if (matchStringChar == totalStringChar) {
// INFO: DCTANT: 2019/9/8 如果相同则继续匹配,成果数+1
continueTimes++;
} else {
// INFO: DCTANT: 2019/9/8 如果不同则中断匹配
break;
}
}
if (continueTimes == matchCharArray.length) {
// INFO: DCTANT: 2019/9/8 匹配成果次数等于需要匹配的字符串长度减一(因为已经去头),则说明匹配成功了
return matchIndex;
} else {
// INFO: DCTANT: 2019/9/8 如果匹配失败,则改变下一次匹配的起点
if (sameHeadCharIndex != -1) {
// INFO: DCTANT: 2019/9/8 如果被匹配的字符串中存在和匹配串首字符相同的字符,则移动到下个首字符开始的地方
matchIndex += sameHeadCharIndex;
} else {
// INFO: DCTANT: 2019/9/8 如果去头的匹配串中没有和匹配串首字符相同的字符,则移动1+成果数
matchIndex += continueTimes + 1;
}
}
} else {
// INFO: DCTANT: 2019/9/8 首字符都无法匹配,直接往后移匹配起始点
matchIndex++;
}
}
return -1;
}最后是无聊的性能比较,这里当然要和Java原生的indexOf比,这里有个很奇怪的问题,我把indexOf这个方法从String类中拷出来后,比原方法的性能差了有近1倍,明明是一模一样的代码,我也不清楚是为什么,希望有大神能解释一下。
结果是性能和Java原生的indexOf差不多,有时性能比它要好,有时又稍微差一点,反正五五开的水平,说明写的没什么问题。