这是十分钟成为 TiDB Contributor 系列的第二篇文章,让大家可以无门槛参与大型开源项目,感谢社区为 TiDB 带来的贡献,也希望参与 TiDB Community 能为你的生活带来更多有意义的时刻。
为了加速表达式计算速度,最近我们对表达式的计算框架进行了重构,这篇教程为大家分享如何利用新的计算框架为 TiDB 重写或新增 built-in 函数。对于部分背景知识请参考这篇文章,本文将首先介绍利用新的表达式计算框架重构 built-in 函数实现的流程,然后以一个函数作为示例进行详细说明,最后介绍重构前后表达式计算框架的区别。
重构 built-in 函数整体流程
在 TiDB 源码 expression 目录下选择任一感兴趣的函数,假设函数名为 XX
-
重写 XXFunctionClass.getFunction() 方法
该方法参照 MySQL 规则,根据 built-in 函数的参数类型推导函数的返回值类型
根据参数的个数、类型、以及函数的返回值类型生成不同的函数签名,关于函数签名的详细介绍见文末附录
实现该 built-in 函数对应的所有函数签名的 evalYY() 方法,此处 YY 表示该函数签名的返回值类型
-
添加测试:
在 expression 目录下,完善已有的 TestXX() 方法中关于该函数实现的测试
在 executor 目录下,添加 SQL 层面的测试
运行 make dev,确保所有的 test cast 都能跑过
示例
这里以重写 LENGTH() 函数的 PR 为例,进行详细说明
首先看 expression/builtin_string.go:
(1)实现 lengthFunctionClass.getFunction() 方法
该方法主要完成两方面工作:
参照 MySQL 规则推导 LEGNTH 的返回值类型
根据 LENGTH 函数的参数个数、类型及返回值类型生成函数签名。由于 LENGTH 的参数个数、类型及返回值类型只存在确定的一种情况,因此此处没有定义新的函数签名类型,而是修改已有的 builtinLengthSig,使其组合了 baseIntBuiltinFunc(表示该函数签名返回值类型为 int)
type builtinLengthSig struct {
baseIntBuiltinFunc
}
func (c *lengthFunctionClass) getFunction(args []Expression, ctx context.Context) (builtinFunc, error) {
// 参照 MySQL 规则,对 LENGTH 函数返回值类型进行推导
tp := types.NewFieldType(mysql.TypeLonglong)
tp.Flen = 10
types.SetBinChsClnFlag(tp)
// 根据参数个数、类型及返回值类型生成对应的函数签名,注意此处与重构前不同,使用的是 newBaseBuiltinFuncWithTp 方法,而非 newBaseBuiltinFunc 方法
// newBaseBuiltinFuncWithTp 的函数声明中,args 表示函数的参数,tp 表示函数的返回值类型,argsTp 表示该函数签名中所有参数对应的正确类型
// 因为 LENGTH 的参数个数为1,参数类型为 string,返回值类型为 int,因此此处传入 tp 表示函数的返回值类型,传入 tpString 用来标识参数的正确类型。对于多个参数的函数,调用 newBaseBuiltinFuncWithTp 时,需要传入所有参数的正确类型
bf, err := newBaseBuiltinFuncWithTp(args, tp, ctx, tpString)
if err != nil {
return nil, errors.Trace(err)
}
sig := &builtinLengthSig{baseIntBuiltinFunc{bf}}
return sig.setSelf(sig), errors.Trace(c.verifyArgs(args))
}(2) 实现 builtinLengthSig.evalInt() 方法
func (b *builtinLengthSig) evalInt(row []types.Datum) (int64, bool, error) {
// 对于函数签名 builtinLengthSig,其参数类型已确定为 string 类型,因此直接调用 b.args[0].EvalString() 方法计算参数
val, isNull, err := b.args[0].EvalString(row, b.ctx.GetSessionVars().StmtCtx)
if isNull || err != nil {
return 0, isNull, errors.Trace(err)
}
return int64(len([]byte(val))), false, nil
}然后看 expression/builtin_string_test.go,对已有的 TestLength() 方法进行完善:
func (s *testEvaluatorSuite) TestLength(c *C) {
defer testleak.AfterTest(c)() // 监测 goroutine 泄漏的工具,可以直接照搬
// cases 的测试用例对 length 方法实现进行测试
// 此处注意,除了正常 case 之外,最好能添加一些异常的 case,如输入值为 nil,或者是多种类型的参数
cases := []struct {
args interface{}
expected int64
isNil bool
getErr bool
}{
{"abc", 3, false, false},
{"你好", 6, false, false},
{1, 1, false, false},
...
}
for _, t := range cases {
f, err := newFunctionForTest(s.ctx, ast.Length, primitiveValsToConstants([]interface{}{t.args})...)
c.Assert(err, IsNil)
// 以下对 LENGTH 函数的返回值类型进行测试
tp := f.GetType()
c.Assert(tp.Tp, Equals, mysql.TypeLonglong)
c.Assert(tp.Charset, Equals, charset.CharsetBin)
c.Assert(tp.Collate, Equals, charset.CollationBin)
c.Assert(tp.Flag, Equals, uint(mysql.BinaryFlag))
c.Assert(tp.Flen, Equals, 10)
// 以下对 LENGTH 函数的计算结果进行测试
d, err := f.Eval(nil)
if t.getErr {
c.Assert(err, NotNil)
} else {
c.Assert(err, IsNil)
if t.isNil {
c.Assert(d.Kind(), Equals, types.KindNull)
} else {
c.Assert(d.GetInt64(), Equals, t.expected)
}
}
}
// 以下测试函数是否是具有确定性
f, err := funcs[ast.Length].getFunction([]Expression{Zero}, s.ctx)
c.Assert(err, IsNil)
c.Assert(f.isDeterministic(), IsTrue)
}最后看 executor/executor_test.go,对 LENGTH 的实现进行 SQL 层面的测试:
// 关于 string built-in 函数的测试可以在这个方法中添加
func (s *testSuite) TestStringBuiltin(c *C) {
defer func() {
s.cleanEnv(c)
testleak.AfterTest(c)()
}()
tk := testkit.NewTestKit(c, s.store)
tk.MustExec("use test")
// for length
// 此处的测试最好也能覆盖多种不同的情况
tk.MustExec("drop table if exists t")
tk.MustExec("create table t(a int, b double, c datetime, d time, e char(20), f bit(10))")
tk.MustExec(`insert into t values(1, 1.1, "2017-01-01 12:01:01", "12:01:01", "abcdef", 0b10101)`)
result := tk.MustQuery("select length(a), length(b), length(c), length(d), length(e), length(f), length(null) from t")
result.Check(testkit.Rows("1 3 19 8 6 2 "))
} 重构前的表达式计算框架
TiDB 通过 Expression 接口(在 expression/expression.go 文件中定义)对表达式进行抽象,并定义 eval 方法对表达式进行计算:
type Expression interface{
...
eval(row []types.Datum) (types.Datum, error)
...
}实现 Expression 接口的表达式包括:
Scalar Function:标量函数表达式
Column:列表达式
Constant:常量表达式
下面以一个例子说明重构前的表达式计算框架。
例如:
create table t (
c1 int,
c2 varchar(20),
c3 double
)
select * from t where c1 + CONCAT( c2, c3 < “1.1” )对于上述 select 语句 where 条件中的表达式:
在编译阶段,TiDB 将构建出如下图所示的表达式树:
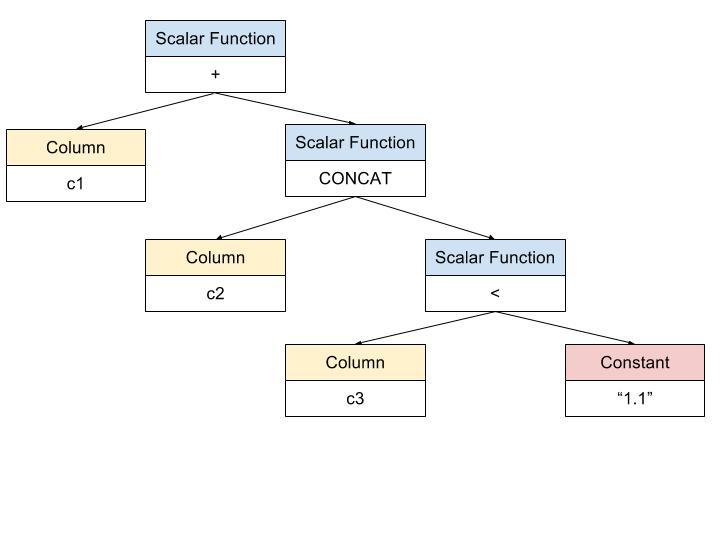
在执行阶段,调用根节点的 eval 方法,通过后续遍历表达式树对表达式进行计算。
对于表达式 ‘<’,计算时需要考虑两个参数的类型,并根据一定的规则,将两个参数的值转化为所需的数据类型后进行计算。上图表达式树中的 ‘<’,其参数类型分别为 double 和 varchar,根据 MySQL 的计算规则,此时需要使用浮点类型的计算规则对两个参数进行比较,因此需要将参数 “1.1” 转化为 double 类型,而后再进行计算。
同样的,对于上图表达式树中的表达式 CONCAT,计算前需要将其参数分别转化为 string 类型;对于表达式 ‘+’,计算前需要将其参数分别转化为 double 类型。
因此,在重构前的表达式计算框架中,对于参与运算的每一组数据,计算时都需要大量的判断分支重复地对参数的数据类型进行判断,若参数类型不符合表达式的运算规则,则需要将其转换为对应的数据类型。
此外,由 Expression.eval() 方法定义可知,在运算过程中,需要通过 Datum 结构不断地对中间结果进行包装和解包,由此也会带来一定的时间和空间开销。
为了解决这两点问题,我们对表达式计算框架进行重构。
重构后的表达式计算框架
重构后的表达式计算框架,一方面,在编译阶段利用已有的表达式类型信息,生成参数类型“符合运算规则”的表达式,从而保证在运算阶段中无需再对类型增加分支判断;另一方面,运算过程中只涉及原始类型数据,从而避免 Datum 带来的时间和空间开销。
继续以上文提到的查询为例,在编译阶段,生成的表达式树如下图所示,对于不符合函数参数类型的表达式,为其加上一层 cast 函数进行类型转换;

这样,在执行阶段,对于每一个 ScalarFunction,可以保证其所有的参数类型一定是符合该表达式运算规则的数据类型,无需在执行过程中再对参数类型进行检查和转换。
附录
对于一个 built-in 函数,由于其参数个数、类型以及返回值类型的不同,可能会生成多个函数签名分别用来处理不同的情况。对于大多数 built-in 函数,其每个参数类型及返回值类型均确定,此时只需要生成一个函数签名。
对于较为复杂的返回值类型推导规则,可以参考 CONCAT 函数的实现和测试。可以利用 MySQLWorkbench 工具运行查询语句
select funcName(arg0, arg1, ...)观察 MySQL 的 built-in 函数在传入不同参数时的返回值数据类型。在 TiDB 表达式的运算过程中,只涉及 6 种运算类型(目前正在实现对 JSON 类型的支持),分别是
int (int64)
real (float64)
decimal
string
Time
-
Duration
通过 WrapWithCastAsXX() 方法可以将一个表达式转换为对应的类型。
对于一个函数签名,其返回值类型已经确定,所以定义时需要组合与该类型对应的 baseXXBuiltinFunc,并实现 evalXX() 方法。(XX 不超过上述 6 种类型的范围)
---------------------------- 我是 AI 的分割线 ----------------------------------------
回顾三月启动的《十分钟成为 TiDB Contributor 系列 | 添加內建函数》活动,在短短的时间内,我们收到了来自社区贡献的超过 200 条新建內建函数,这之中有很多是来自大型互联网公司的资深数据库工程师,也不乏在学校或是刚毕业在刻苦钻研分布式系统和分布式数据库的学生。
TiDB Contributor Club 将大家聚集起来,我们互相分享、讨论,一起成长。
感谢你的参与和贡献,在开源的道路上我们将义无反顾地走下去,和你一起。
成为 New Contributor 赠送限量版马克杯的活动还在继续中,任何一个新加入集体的小伙伴都将收到我们充满了诚意的礼物,很荣幸能够认识你,也很高兴能和你一起坚定地走得更远。
成为 New Contributor 获赠限量版马克杯,马克杯获取流程如下:
提交 PR
PR提交之后,请耐心等待维护者进行 Review。
目前一般在一到两个工作日内都会进行 Review,如果当前的 PR 堆积数量较多可能回复会比较慢。代码提交后 CI 会执行我们内部的测试,你需要保证所有的单元测试是可以通过的。期间可能有其它的提交会与当前 PR 冲突,这时需要修复冲突。维护者在 Review 过程中可能会提出一些修改意见。修改完成之后如果 reviewer 认为没问题了,你会收到 LGTM(looks good to me) 的回复。当收到两个及以上的 LGTM 后,该 PR 将会被合并。合并 PR 后自动成为 Contributor,会收到来自 PingCAP Team 的感谢邮件,请查收邮件并填写领取表单
表单填写地址:http://cn.mikecrm.com/01wE8tX后台 AI 核查 GitHub ID 及资料信息,确认无误后随即便快递寄出属于你的限量版马克杯
期待你分享自己参与开源项目的感想和经验,TiDB Contributor Club 将和你一起分享开源的力量
了解更多关于 TiDB 的资料请登陆我们的官方网站:https://pingcap.com
加入 TiDB Contributor Club 请添加我们的 AI 微信:
TiDB Robot 微信二维码