keras 实现人脸情绪、年龄、性别 的 识别
1.所需环境:
python3
依赖包: opencv tensorflow keras dlib
这些包的下载教程全网可搜到 所以这就是我懒得写的借口了。
2.代码块
import os
import cv2
import time
import numpy as np
import argparse
import dlib
from contextlib import contextmanager
from wide_resnet import WideResNet
from keras.utils.data_utils import get_file
from keras.models import model_from_json
pretrained_model = "https://github.com/yu4u/age-gender-estimation/releases/download/v0.5/weights.28-3.73.hdf5"
modhash = ''
emotion_labels = ['angry', 'fear', 'happy', 'pingjing', 'surprise', 'neutral']
# load json and create model arch
json_file = open('model.json','r')
loaded_model_json = json_file.read()
json_file.close()
#将json重构为model结构
model = model_from_json(loaded_model_json)
# load weights into new model
model.load_weights('model.h5')
def predict_emotion(face_image_gray): # a single cropped face
resized_img = cv2.resize(face_image_gray, (48,48), interpolation = cv2.INTER_AREA)
image = resized_img.reshape(1, 1, 48, 48)
im = cv2.resize(resized_img,(90,100))
cv2.imwrite('face.bmp', im)
list_of_list = model.predict(image, batch_size=1, verbose=1)
angry, fear, happy, sad, surprise, neutral = [prob for lst in list_of_list for prob in lst]
return [angry, fear, happy, sad, surprise, neutral]
def get_args():
parser = argparse.ArgumentParser(description="This script detects faces from web cam input, "
"and estimates age and gender for the detected faces.",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
#改成自己的地址
parser.add_argument("--weight_file", type=str, default="./weights.28-3.73.hdf5",
help="path to weight file (e.g. weights.28-3.73.hdf5)")
parser.add_argument("--depth", type=int, default=16,
help="depth of network")
parser.add_argument("--width", type=int, default=8,
help="width of network")
args = parser.parse_args()
return args
def draw_label(image, point, label, font=cv2.FONT_HERSHEY_SIMPLEX,
font_scale=1, thickness=2):
size = cv2.getTextSize(label, font, font_scale, thickness)[0]
x, y = point
cv2.rectangle(image, (x, y - size[1]), (x + size[0], y), (255, 0, 0), cv2.FILLED)
cv2.putText(image, label, point, font, font_scale, (255, 255, 255), thickness)
@contextmanager
def video_capture(*args, **kwargs):
cap = cv2.VideoCapture(*args, **kwargs)
try:
yield cap
finally:
cap.release()
def yield_images():
# capture video
camera = cv2.VideoCapture(0) # 初始化摄像头(0代表使用的第一个摄像头)。
#
# while (True):
# ret, frame = camera.read() # 捕获帧,第一个为布尔值,第二个为帧。
# if ret == False:
# break
# # ----------------------------------- 持续捕捉人脸,截取人脸信息。-------------------------------------------
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转为灰度图,OpenCV人脸检测需要基于灰度的色彩空间。
# faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# with video_capture(0) as cap:
# cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
# cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
#
while True:
# get video frame
ret, img = camera.read()
if not ret:
raise RuntimeError("Failed to capture image")
yield img
def main():
biaoqing = ""
args = get_args()
depth = args.depth
k = args.width
weight_file = args.weight_file
print(weight_file)
#第一次运行时会自动从给的网址下载weights.18-4.06.hdf5模型(190M左右)
if not weight_file:
weight_file = get_file("weights.28-3.73.hdf5", pretrained_model, cache_subdir="pretrained_models",
file_hash=modhash, cache_dir=os.path.dirname(os.path.abspath(__file__)))
# for face detection
detector = dlib.get_frontal_face_detector()
# load model and weights
img_size = 64
model = WideResNet(img_size, depth=depth, k=k)()
model.load_weights(weight_file)
for img in yield_images():
#img = cv2.imread("1.jpg")
input_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_h, img_w, _ = np.shape(input_img)
#print("h w ",img_h,img_w)
emotions = []
# Draw a rectangle around the faces
# detect faces using dlib detector
detected = detector(img_gray, 0)
faces = np.empty((len(detected), img_size, img_size, 3))
#print("dector",detected)
if len(detected) > 0:
for i, d in enumerate(detected):
#print("i,d =",i,d)
x1, y1, x2, y2, w, h = d.left(), d.top(), d.right() + 1, d.bottom() + 1, d.width(), d.height()
#print("w h =",w,h)
xw1 = max(int(x1 - 0.4 * w), 0)
yw1 = max(int(y1 - 0.4 * h), 0)
xw2 = min(int(x2 + 0.4 * w), img_w - 1)
yw2 = min(int(y2 + 0.4 * h), img_h - 1)
cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 2)
#cv2.rectangle(img, (xw1, yw1), (xw2, yw2), (255, 0, 0), 2)
faces[i, :, :, :] = cv2.resize(img[yw1:yw2 + 1, xw1:xw2 + 1, :], (img_size, img_size))
#print("faces ",faces)
face_image_gray = img_gray[y1:y1 + y2, x1:x1 + x2]
angry, fear, happy, sad, surprise, neutral = predict_emotion(face_image_gray)
emotions = [angry, fear, happy, sad, surprise, neutral]
m = emotions.index(max(emotions))
for index, val in enumerate(emotion_labels):
if (m == index):
biaoqing = val
# predict ages and genders of the detected faces
results = model.predict(faces)
predicted_genders = results[0]
ages = np.arange(0, 101).reshape(101, 1)
predicted_ages = results[1].dot(ages).flatten()
# draw results
for i, d in enumerate(detected):
#print("表情",biaoqing)
label = "{}, {},{}".format(int(predicted_ages[i]),
"F" if predicted_genders[i][0] > 0.5 else "M" ,biaoqing)
draw_label(img, (d.left(), d.top()), label)
print(time.time())
cv2.imshow("result", img)
#等待3ms
key = cv2.waitKey(100)
if key == 27:
break
if __name__ == '__main__':
main()
这是第二个代码块
wide_resnet.py
# This code is imported from the following project: https://github.com/asmith26/wide_resnets_keras
import logging
import sys
import numpy as np
from keras.models import Model
from keras.layers import Input, Activation, add, Dense, Flatten, Dropout
from keras.layers.convolutional import Conv2D, AveragePooling2D
from keras.layers.normalization import BatchNormalization
from keras.regularizers import l2
from keras import backend as K
sys.setrecursionlimit(2 ** 20)
np.random.seed(2 ** 10)
class WideResNet:
def __init__(self, image_size, depth=16, k=8):
self._depth = depth
self._k = k
self._dropout_probability = 0
self._weight_decay = 0.0005
self._use_bias = False
self._weight_init = "he_normal"
if K.image_dim_ordering() == "th":
logging.debug("image_dim_ordering = 'th'")
self._channel_axis = 1
self._input_shape = (3, image_size, image_size)
else:
logging.debug("image_dim_ordering = 'tf'")
self._channel_axis = -1
self._input_shape = (image_size, image_size, 3)
# Wide residual network http://arxiv.org/abs/1605.07146
def _wide_basic(self, n_input_plane, n_output_plane, stride):
def f(net):
# format of conv_params:
# [ [kernel_size=("kernel width", "kernel height"),
# strides="(stride_vertical,stride_horizontal)",
# padding="same" or "valid"] ]
# B(3,3): orignal <> block
conv_params = [[3, 3, stride, "same"],
[3, 3, (1, 1), "same"]]
n_bottleneck_plane = n_output_plane
# Residual block
for i, v in enumerate(conv_params):
if i == 0:
if n_input_plane != n_output_plane:
net = BatchNormalization(axis=self._channel_axis)(net)
net = Activation("relu")(net)
convs = net
else:
convs = BatchNormalization(axis=self._channel_axis)(net)
convs = Activation("relu")(convs)
convs = Conv2D(n_bottleneck_plane, kernel_size=(v[0], v[1]),
strides=v[2],
padding=v[3],
kernel_initializer=self._weight_init,
kernel_regularizer=l2(self._weight_decay),
use_bias=self._use_bias)(convs)
else:
convs = BatchNormalization(axis=self._channel_axis)(convs)
convs = Activation("relu")(convs)
if self._dropout_probability > 0:
convs = Dropout(self._dropout_probability)(convs)
convs = Conv2D(n_bottleneck_plane, kernel_size=(v[0], v[1]),
strides=v[2],
padding=v[3],
kernel_initializer=self._weight_init,
kernel_regularizer=l2(self._weight_decay),
use_bias=self._use_bias)(convs)
# Shortcut Connection: identity function or 1x1 convolutional
# (depends on difference between input & output shape - this
# corresponds to whether we are using the first block in each
# group; see _layer() ).
if n_input_plane != n_output_plane:
shortcut = Conv2D(n_output_plane, kernel_size=(1, 1),
strides=stride,
padding="same",
kernel_initializer=self._weight_init,
kernel_regularizer=l2(self._weight_decay),
use_bias=self._use_bias)(net)
else:
shortcut = net
return add([convs, shortcut])
return f
# "Stacking Residual Units on the same stage"
def _layer(self, block, n_input_plane, n_output_plane, count, stride):
def f(net):
net = block(n_input_plane, n_output_plane, stride)(net)
for i in range(2, int(count + 1)):
net = block(n_output_plane, n_output_plane, stride=(1, 1))(net)
return net
return f
# def create_model(self):
def __call__(self):
logging.debug("Creating model...")
assert ((self._depth - 4) % 6 == 0)
n = (self._depth - 4) / 6
inputs = Input(shape=self._input_shape)
n_stages = [16, 16 * self._k, 32 * self._k, 64 * self._k]
conv1 = Conv2D(filters=n_stages[0], kernel_size=(3, 3),
strides=(1, 1),
padding="same",
kernel_initializer=self._weight_init,
kernel_regularizer=l2(self._weight_decay),
use_bias=self._use_bias)(inputs) # "One conv at the beginning (spatial size: 32x32)"
# Add wide residual blocks
block_fn = self._wide_basic
conv2 = self._layer(block_fn, n_input_plane=n_stages[0], n_output_plane=n_stages[1], count=n, stride=(1, 1))(conv1)
conv3 = self._layer(block_fn, n_input_plane=n_stages[1], n_output_plane=n_stages[2], count=n, stride=(2, 2))(conv2)
conv4 = self._layer(block_fn, n_input_plane=n_stages[2], n_output_plane=n_stages[3], count=n, stride=(2, 2))(conv3)
batch_norm = BatchNormalization(axis=self._channel_axis)(conv4)
relu = Activation("relu")(batch_norm)
# Classifier block
pool = AveragePooling2D(pool_size=(8, 8), strides=(1, 1), padding="same")(relu)
flatten = Flatten()(pool)
predictions_g = Dense(units=2, kernel_initializer=self._weight_init, use_bias=self._use_bias,
kernel_regularizer=l2(self._weight_decay), activation="softmax",
name="pred_gender")(flatten)
predictions_a = Dense(units=101, kernel_initializer=self._weight_init, use_bias=self._use_bias,
kernel_regularizer=l2(self._weight_decay), activation="softmax",
name="pred_age")(flatten)
model = Model(inputs=inputs, outputs=[predictions_g, predictions_a])
return model
def main():
model = WideResNet(64)()
model.summary()
if __name__ == '__main__':
main()
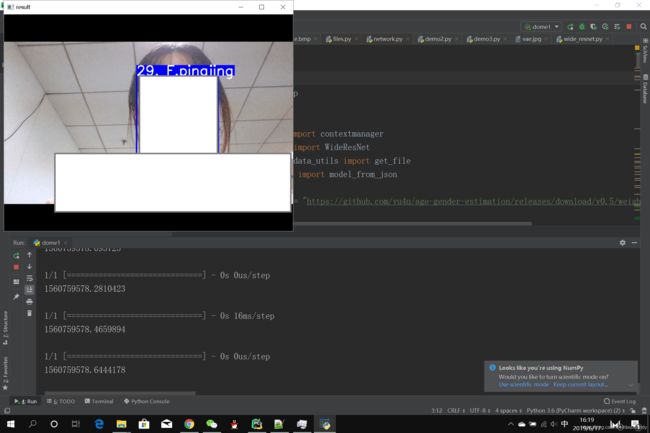
3.实现截图
4.关于代码的说明
放出来的 第一块 代码是主入口,还有一些依赖包哦
第二个代码块也是被import 的一部分哦
为了赚点C币花,我打包放到资源,小可爱们自行下载哦~
链接:
https://download.csdn.net/download/dearcandy/11245289
代码主要来源于hpyMiss的博客
https://blog.csdn.net/hpyMiss/article/details/80759500
但是我下载下来的时候他的代码是并不通的,
好不容易凑齐资料又调通,还进行了一些优化
所以可以赚点C币吗?
解释原理的话,,建议从上面那个网址看起,我就不多说了(主要是打字太累) 说的话可以写一本书,而我又没有那个实力。
啊!生活是如此美好