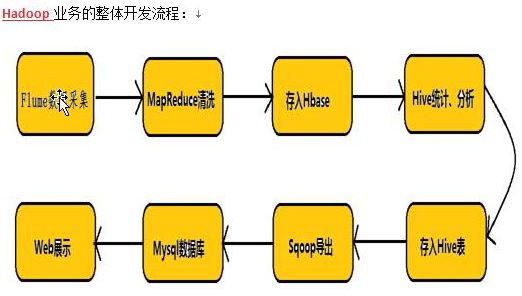
- Flume-HBase-Kafka
正在緩沖҉99%
kafkaFlumeHBase大数据
Flume-HBase-Kafka一、各自介绍1.Flume简介和特征2.HBase简介和特征3.Kafka简介和特征二、通过Flume读取日志文件写入到Kafka中在写入HBase各自作用一、各自介绍1.Flume简介和特征一、简介Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方
- 大数据环境(单机版) Flume传输数据到Kafka
凡许真
大数据flumekafka数据采集
文章目录前言一、准备二、安装三、配置环境变量四、修改配置4.1、kafka配置4.2、Flume配置五、启动程序5.1、启动zk5.2、启动kafka5.3、启动flume六、测试6.1、启动一个kafka终端,用来消费消息6.2、写入日志其他前言flume监控指定目录,传输数据到kafka一、准备flume-1.10.1kafka_2.11-2.4.1zookeeper-3.4.13二、安装使用
- Kafka系列之:记录一次源头数据库刷数据,造成数据丢失的原因
快乐骑行^_^
KafkaKafka系列记录一次源头数据库刷数据造成数据丢失的原因
Kafka系列之:记录一次源头数据库刷数据,造成数据丢失的原因一、背景二、查看topic日志信息三、结论四、解决方法一、背景源头数据库在很短的时间内刷了大量的数据,部分数据在hdfs丢失了理论上debezium数据采集不会丢失,就需要排查数据链路某个节点是否有数据丢失。数据链路是:debezium——kafka——flume——hdfs根据经验定位数据在kafka侧丢失,下一面进一步确认是否数据在
- 强大的ETL利器—DataFlow3.0
lixiang2114
数据分析etlflumesqoop数据库数据仓库
产品开发背景DataFlow是基于应用数据流程的一套分布式ETL系统服务组件,其前身是LogCollector2.0日志系统框架,自LogCollector3.0版本开始正式更名为DataFlow3.0。目前常用的ETL工具Flume、LogStash、Kettle、Sqoop等也可以完成数据的采集、传输、转换和存储;但这些工具都不具备事务一致性。比如Flume工具仅能应用到通信质量无障碍的局域网
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
m0_74823705
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- 数据仓库与数据挖掘记录 三
匆匆整棹还
数据挖掘
数据仓库的数据存储和处理数据的ETL过程数据ETL是用来实现异构数据源的数据集成,即完成数据的抓取/抽取、清洗、转换.加载与索引等数据调和工作,如图2.2所示。1)数据提取(Extract)从多个数据源中获取原始数据(如数据库、日志文件、API、云存储等)。数据源可能是结构化(如MySQL)、半结构化(如JSON)、非结构化(如文本)。关键技术:SQL查询、Web爬虫、日志采集工具(如Flume)
- 【大数据技术】搭建完全分布式高可用大数据集群(Flume)
Want595
Python大数据采集与分析大数据分布式flume
搭建完全分布式高可用大数据集群(Flume)apache-flume-1.11.0-bin.tar.gz注:请在阅读本篇文章前,将以上资源下载下来。写在前面本文主要介绍搭建完全分布式高可用集群Flume的详细步骤。注意:统一约定将软件安装包存放于虚拟机的/software目录下,软件安装至/opt目录下。安装Flume用finalshell将压缩包上传到虚拟机master的/software目录下
- 计算机毕业设计hadoop+spark+hive新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 大数据毕业设计 深度学习 知识图谱 人工智能
qq+593186283
hadoop大数据人工智能
(1)设计目的本次设计一个基于Hive的新能源汽车数据仓管理系统。企业管理员登录系统后可以在汽车保养时,根据这些汽车内置传感器传回的数据分析其故障原因,以便维修人员更加及时准确处理相关的故障问题。或者对这些数据分析之后向车主进行预警提示车主注意保养汽车,以提高汽车行驶的安全系数。(2)设计要求利用Flume进行分布式的日志数据采集,Kafka实现高吞吐量的数据传输,DateX进行数据清洗、转换和整
- python消费kafka数据nginx日志实时_基于nginx+flume+kafka+mongodb实现埋点数据采集
weixin_39534208
名词解释埋点其实就是用于记录用户在页面的一些操作行为。例如,用户访问页面(PV,PageViews)、访问页面用户数量(UV,UserViews)、页面停留、按钮点击、文件下载等,这些都属于用户的操作行为。开发背景我司之前在处理埋点数据采集时,模式很简单,当用户操作页面控件时,前端监听到操作事件,并根据上下文环境,将事件相关的数据通过接口调用发送至埋点数据采集服务(简称ets服务),ets服务对数
- 大数据-267 实时数仓 - ODS Lambda架构 Kappa架构 核心思想
m0_74823336
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!MyBatis更新完毕目前开始更新Spring,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)Cl
- nginx+flume网络流量日志实时数据分析实战_日志数据分析(1)
2401_84182578
程序员nginxflume数据分析
得到visits模型hadoopjar/export/data/mapreduce/web_log.jarcn.itcast.bigdata.weblog.clickstream.ClickStreamVisit网络日志数据分析-数据加载对于日志数据的分析,Hive也分为三层:ods层、dw层、app层创建数据库createdatabaseifnotexistsweb_log_ods;create
- 【大数据入门核心技术-Flume】(二)Flume安装部署
forest_long
大数据技术入门到21天通关bigdatahadoop大数据hbaseflume
目录一、准备工作1、基本Hadoop环境安装2、下载安装包二、安装1、解压2、修改环境变量3、修改并配置flume-env.sh文件4、验证是否安装成功一、准备工作1、基本Hadoop环境安装参考Hadoop安装【大数据入门核心技术-Hadoop】(五)Hadoop3.2.1非高可用集群搭建【大数据入门核心技术-Hadoop】(六)Hadoop3.2.1高可用集群搭建2、下载安装包官方网址:
- java.io.FileNotFoundException: /tmp/log/flume-ng/flume.log (Permission denied)
海洋 之心
Flume问题解决Hadoop问题解决javaflume开发语言zookeeper大数据
文章目录问题描述:原因分析:解决方案:问题描述:使用Flume将本地文件监控上传到HDFS上时出现log4j:ERRORsetFile(null,true)callfailed.java.io.FileNotFoundException:/tmp/log/flume-ng/flume.log(Permissiondenied)log4j:ERRORsetFile(null,true)callfai
- flume系列之:消费Kafka集群Topic报错java.io.IOException: Can‘t resolve address: data03:9092
快乐骑行^_^
flumeflume系列消费Kafka集群TopicOExceptionresolveaddress
flume系列之:消费Kafka集群Topic报错java.io.IOException:Can'tresolveaddress:data03:9092Causedby:java.nio.channels.UnresolvedAddressException一、flume消费Kafka集群Topic报错二、报错原因三、解决方法一、flume消费Kafka集群Topic报错21Sep202214:5
- 基于Spark的实时计算服务的流程架构
小小搬运工40
spark大数据
基于Spark的实时计算服务的流程架构通常涉及多个组件和步骤,从数据采集到数据处理,再到结果输出和监控。以下是一个典型的基于Spark的实时计算服务的流程架构:1.数据源数据源是实时计算服务的起点,常见的数据源包括:消息队列:如Kafka、RabbitMQ、AmazonKinesis等。日志系统:如Flume、Logstash等。传感器数据:物联网设备产生的数据流。数据库变更数据捕获(CDC):如
- 大数据开发的底层逻辑是什么?
瑰茵
大数据
大数据开发的底层逻辑主要围绕数据的生命周期进行,包括数据的采集、存储、处理、分析和可视化等环节。以下是大数据开发的一些关键底层逻辑:数据采集:目的:从不同的数据源(如日志文件、数据库、传感器等)收集数据。方法:使用数据采集工具(如ApacheFlume、ApacheKafka、ApacheSqoop)来捕获和传输数据。数据存储:目的:将收集到的数据存储在可靠且可扩展的存储系统中。方法:使用分布式文
- flume+ Elasticsearch +kibana环境搭建及讲解
pincharensheng
大数据flumekibanaelasticsearch分布式
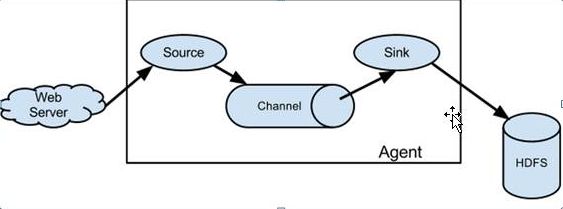
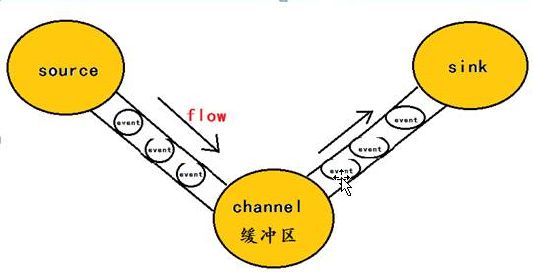
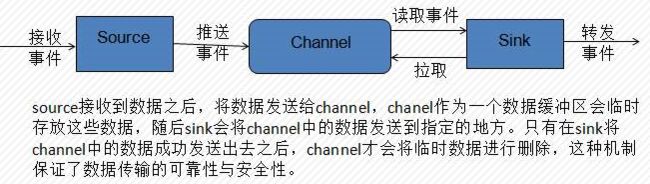
1、软件介绍1.1、flume1.1.1、flume介绍1)flume概念1、flume是一个分布式的日志收集系统,具有高可靠、高可用、事务管理、失败重启等功能。数据处理速度快,完全可以用于生产环境;2、flume的核心是agent。agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,再发送到目的地;3、agent里面包含3个核心组件:source、channel
- Hive数据仓库中的数据导出到MySQL的数据表不成功
sin2201
出错问题数据仓库hivemysql
可能的原因:(1)没有下载flume和sqoop(2)权限问题:因为MySQL数据库拒绝了root用户从hadoop3主机的连接请求,root用户没有从hadoop3主机进行连接的权限解决:通过MySQL的授权命令来授予权限mysql>GRANTALLPRIVILEGESONsqoop_weblog.*TO'root'@'hadoop3'IDENTIFIEDBY'2020';QueryOK,0ro
- python消费kafka数据nginx日志实时_Openresty+Lua+Kafka实现日志实时采集
weixin_39997311
简介在很多数据采集场景下,Flume作为一个高性能采集日志的工具,相信大家都知道它。许多人想起Flume这个组件能联想到的大多数都是Flume跟Kafka相结合进行日志的采集,这种方案有很多他的优点,比如高性能、高吞吐、数据可靠性等。但是我们如果要求对日志进行实时的采集,这显然不是一个好的解决方案。原因如下:就目前来说,Flume能支持实时监控一个目录的数据文件,一旦对某个目录的文件采集完成,就会
- openresty+lua实现实时写kafka
sky@梦幻未来
大数据openrestynginxopenrestylua
一.背景在使用openresty+lua+nginx+flume,通过定时切分日志发送kafka的方式无法满足实时性的情况下,小编开始研究openresty+lua+nginx+kafka实时写kafka,从而达到数据实时性,和高性能保证。二.实现1.openresty安装nginx,以及lua的使用请看博主上一篇博客https://blog.csdn.net/qq_29497387/articl
- SeaTunnel 与 DataX 、Sqoop、Flume、Flink CDC 对比
不二人生
#数据集成工具SeaTunnel
文章目录SeaTunnel与DataX、Sqoop、Flume、FlinkCDC对比同类产品横向对比2.1、高可用、健壮的容错机制2.2、部署难度和运行模式2.3、支持的数据源丰富度2.4、内存资源占用2.5、数据库连接占用2.6、自动建表2.7、整库同步2.8、断点续传2.9、多引擎支持2.10、数据转换算子2.11、性能2.12、离线同步2.13、增量同步&实时同步2.14、CDC同步2.15
- flume系列之:flume落cos
快乐骑行^_^
日常分享专栏flume系列
flume系列之:flume落cos一、参考文章二、安装cosjar包三、添加hadoop-cos的相关配置四、flume环境添加hadoop类路径五、使用cos路径六、启动/重启flume一、参考文章Kafka数据通过Flume存储到HDFS或COSflumetocos使用指南二、安装cosjar包将对应hadoop版本的hadoop-cos的jar包(hadoop-cos-{hadoop.ve
- Flume 简介01 作用 核心概念 事务机制 安装 配置入门实战
湖中屋
Flumeflume
Flume1.业务系统为什么会产生用户行为日志,怎么产生的用户行文日志:每一次访问的行为(访问、搜索)产生的日志记录用户行为日志的目的:1.商家会精准的给你呈现符合你的个人界面2.商家会给你个人添加用户标签,更加精准的分析埋点等2.flume用来做什么的(采集传输数据的,分布式的,可靠的)ApacheFlume是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
武子康
大数据离线数仓大数据数据仓库java后端hadoophive
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- kafka直接对接nginx
Lu_Xiao_Yue
nginxkafka
很多时候我们要对nginx产生的日志进行分析都是通过flume监控nginx产生的日志,通过flume把日志文件发送该kafka,flume作为生产者,但是这种方式的缺点就是可能效率会比较慢,除此之外还可以使用kafka直接对接nginx,nginx作为生产者,把log日志直接对接到kafka的某些分区中,这种方法的效率比较高,但是缺点就是可能会出现数据丢失,可以通过把nginx的日志进行一份给k
- 大数据新视界 --大数据大厂之大数据实战指南:Apache Flume 数据采集的配置与优化秘籍
青云交
大数据新视界数据库ApacheFlume数据采集安装部署配置优化高级功能大数据工具集成
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:大数
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- Flume:大规模日志收集与数据传输的利器
傲雪凌霜,松柏长青
后端大数据flume大数据
Flume:大规模日志收集与数据传输的利器在大数据时代,随着各类应用的不断增长,产生了海量的日志和数据。这些数据不仅对业务的健康监控至关重要,还可以通过深入分析,帮助企业做出更好的决策。那么,如何高效地收集、传输和存储这些海量数据,成为了一项重要的挑战。今天我们将深入探讨ApacheFlume,它是如何帮助我们应对这些挑战的。一、Flume概述ApacheFlume是一个分布式、可靠、可扩展的日志
- 解决flume在抽取不断产生的日志文件时,hdfs上出现很多小文件的问题
lzhlizihang
flumehdfs大数据
问题在使用flume时,需要编写conf文件,然后执行,明明sinks已经指定了roll的三个参数:a1.sinks.k1.hdfs.rollInterval=0(根据写入时间来切割)a1.sinks.k1.hdfs.rollSize=0(根据写入的文件大小来切割)a1.sinks.k1.hdfs.rollCount=0(根据Event数量来切割)其中0代表不根据其属性来切割文件但是hdfs上还会
- pyspark kafka mysql_数据平台实践①——Flume+Kafka+SparkStreaming(pyspark)
weixin_39793638
pysparkkafkamysql
蜻蜓点水Flume——数据采集如果说,爬虫是采集外部数据的常用手段的话,那么,Flume就是采集内部数据的常用手段之一(logstash也是这方面的佼佼者)。下面介绍一下Flume的基本构造。Agent:包含Source、Channel和Sink的主体,它是这3个组件的载体,是组成Flume的数据节点。Event:Flume数据传输的基本单元。Source:用来接收Event,并将Event批量传
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_