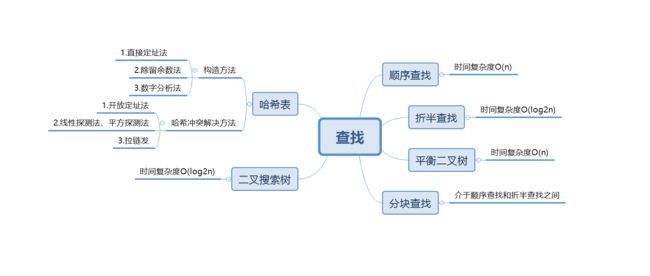
1.1思维导图
1.2谈谈你对查找运算的认识及学习体会
本周学习了查找,学习了效率较好的平衡二叉树、b树、折半查找等算法。不管是设计程序,还是打造产品,一个高性能的算法都极为重要,比如STL中的map和set使用了红黑树,高效的查找效率广受好评。
但是查找算法各自有着优缺点,选择合适的才是最好的,比如搜索引擎使用的倒排索引,非常适合在大量数据中快速找到目标。这些算法从诞生到现在,经受住了无数考验,已经非常成熟。深入了解这些算法,对提高自己的内功很有帮助(俗话说算法是内功)。2.PTA实验作业
2.1.题目1:7-1 QQ帐户的申请与登陆

2.1.1设计思路
使用STL中的map关键字为账号,值为密码。int main()
{
输出数据
for (i = 0 to T)
{
输入数据
cin >> order >> account >> password;
if (order == 'N')
{
调用注册函数Register(account, password);
}
else
{
调用登录函数Login(account, password);
}
}
return 0;
}void Register(string &account, string &password)
{
if(已经注册)
cout << "ERROR: Exist\n";
else(没有注册)
mymap[account] = password;
cout << "New: OK\n";
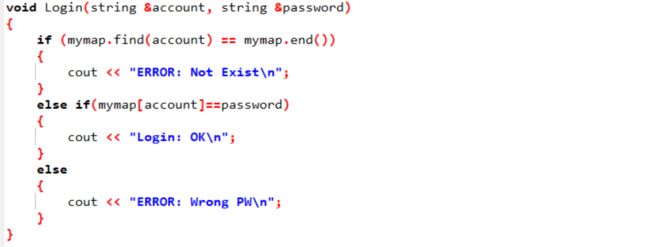
}void Login(string &account, string &password)
{
if (账号不存在)
{
cout << "ERROR: Not Exist\n";
}
else if(密码正确)
{
cout << "Login: OK\n";
}
else 密码错误
{
cout << "ERROR: Wrong PW\n";
}
}2.1.2代码截图


2.1.3本题PTA提交列表说明
![]()
A:使用map思路清晰一般不会有什么问题
2.2.题目2:7-2 航空公司VIP客户查询

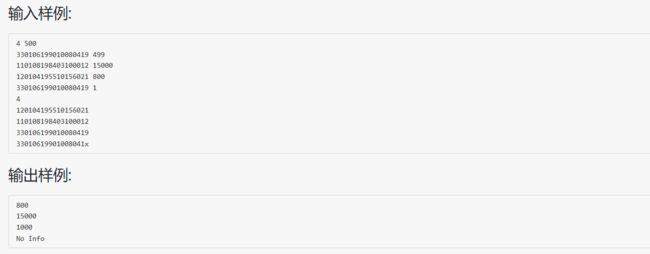
2.2.1设计思路
还是强大的map,关键字为身份证,值为里程 取消流同步,加快读写速度,具体可以百度
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
for (i = 0 to T)
{
读入数据
cin >> id >> dist;
if (dist < k)dist = k;
mymap[id] += dist;
}
for (i = 0 to n)
{
if (如果是vip)
{
输出里程
cout <second<<"\n";
}
else 如果不是
{
cout << "No Info\n";
}
} 2.2.2代码截图


2.2.3本题PTA提交列表说明
![]()
A:读写太慢,运行超时,通过std::ios::sync_with_stdio(false)加快读写
原理
std::ios::sync_with_stdio(false)
这句语句是用来取消cin的同步,
什么叫同步呢?就是iostream的缓冲跟stdio的同步。如果你已经在头文件上用了using namespace std;那么就可以去掉前面的std::了。
取消后就cin就不能和scanf,sscanf, getchar, fgets之类同时用了,否则就可能会导致输出和预期的不一样。 取消同步的目的,是为了让cin不超时,另外cout的时候尽量少用endl,换用”\n”,也是防止超时的方法。当然,尽量用scanf,printf就不用考虑这种因为缓冲的超时了。
原文:https://blog.csdn.net/lv1224/article/details/80084840
2.3.题目3:7-3(选做) 基于词频的文件相似度


2.3.1设计思路
- 1.数据读取?
solution:使用getline直接读入一行存到一个string类型变量str中(个人不喜欢频繁读入),在结尾加上\n(这也是一个单词结束的标志),然后str进行操作,然后大写统一转换为小写(个人爱好), - 2.怎么得到文件的相似度?
solution:此问题的关键在于选什么方式存放数据,发现文件的数量不多,可以直接定义一个map数组,为什么使用map ?该题测试点的数据量比较大,容易超时,而map可以通过count函数,查找时间复杂度可以达到o(1),如果使用链式会达到o(n)。(主要是哈希思想,不限于map)(小声:之前用set要遍历就超时了,所以想到map)
初始数据读入
for (i = 0 to N)文件数
{
读入数据
while (str[0] != '#')//开始处理
{
把单词放到string类型的temp中
for (遍历str)
{
if (str[j]是小写字母)
{
temp += str[j];
}
else if (str[j]是大写字母)
{
temp += str[j] - 'A' + 'a';
}
else str[j]不是字母,是单词结束标志
{
int len = temp.size();
if (len > 0)
{
if (len> 2)长度不小于3、且不超过10的英文单词,长度超过10的只考虑前10个字母
{
if (len > 10) temp = temp.substr(0, 10);
mymap[i][temp] = 1;
}
temp.clear();temp每次要清空
}
}
}
读入数据
}
}相似度计算
for (i = 0 to T)T对比较数据
{
for (; it != mymap[a].end(); it++)对其中一个遍历
{
if (mymap[b].count(it->first) == 1)在另一个中查找是否有相同单词
{
sum++;
}
}
输出结果
num -= sum;
cout << setiosflags(ios::fixed) << setprecision(1);
cout << (sum * 100 / num)<<"%\n";
}2.3.2代码截图



2.3.3本题PTA提交列表说明
![]()
A:开始是用set,查找需要遍历,最后一个测试点超时。(下面贴出遍历部分代码作为对比)

3.阅读代码
3.1 题目
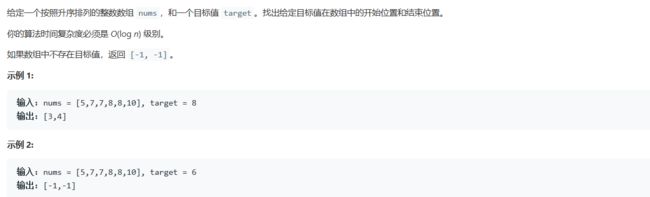
3.2 解题思路
使用二分查找,用a记录目标值开始位置,b记录结束位置3.3 代码截图

3.4 学习体会
熟悉算法的原理,再加以改造就可以解决很多算法问题,往往效果还不错。