java线程池原理讲解及常用创建方式
(一)什么是线程池
其实线程池的概念和数据库链接池的概念类似。线程池的作用就是为了避免系统频繁地创建和销毁线程。在线程池中,
总有几个活跃的线程,当你需要使用线程是,可以从池子中随便拿一个空闲线程,当完成工作是,并不是关闭线程,而是
将这个线程退回到池子,方便其他人使用。
(二)JDK对于线程池常用类的讲解
首先我们先看一下线程池的类图关系,只有理解了这些类的关系后,后面的理解就容易多了:
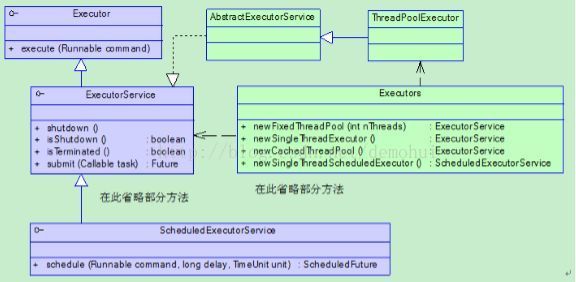
- Executor是一个顶层接口,在它里面只声明了一个方法execute(Runnable),返回值为void,参数为Runnable类型,
该方法用于接收执行用户提交任务。
- ExecutorService 接口继承了Executor接口,定义了线程池终止和创建及提交 futureTask 任务支持的方法。
并声明了
一些方法:
submit、invokeAll、invokeAny以及shutDown等。
- AbstractExecutorService 是抽象类,它实现了ExecutorService接口及其中的的所有方法。主要实现了 ExecutorService
和
futureTask 相关的一些任务创建和提交的方法。
- ThreadPoolExecutor 继承了类AbstractExecutorService,它是最核心的一个类,它的实例对象其实就代表了一个线程池,
是线程池的内部实现。线程池的功能都在这里实现了,平时用的最多的基本就是这个。其源码很精练,远没当时想象的多。
- ScheduledThreadPoolExecutor 在 ThreadPoolExecutor 的基础上提供了支持定时调度的功能。线程任务可以在一定延时
后才被触发执行。
- 最后我们充电说一下上面UML图中的Executors类,其实这个类扮演着线程池工厂的角色,它里面提供了几种构造不同线程池
的方法:
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newCachedThreadPool()
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)(三)构造线程池的常用的几种方式
- newFixedThreadPool()方法
创建语句是:ExecutorService pool = Executors.newScheduledThreadPool(10),该方式返回一个固定线程数量的线程池,
这里为10。该线程池中的的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有
,则新的任务会被暂时存放在一个队伍队列中,待有线程空闲时,便处理在任务队列的任务
- newSingleThreadExecutor方法
创建语句是:ExecutorService pool = Executors.newSingleThreadExecutor(),该方式返回一个只有一个线程的线程池。
若多于的
任务被提交到该线程池,任务就会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- newCachedThreadPool()方法
创建语句是:ExecutorService pool = Executors.newCachedThreadPool(),该方式返回一个可根据实际情况调整线程
数量的线程池,
线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,
又有新的任务提交,则会创建
新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池中进行复用。
- newSingleThreadScheduledExecutor()方法
创建语句:ScheduledExecutorService pool = Executors.newSingleThreadScheduledExecutor(),该方法返回一个
ScheduledExecutorService对象,线程池大小为1。ScheduledExecutorService接口在ExecutorService 接口之上扩展了在
给定时间执行
某任务的功能,如在某个固定的延时之后执行,或者周期性执行某个任务
- newScheduledThreadPool()方法
创建语句:ScheduledExecutorService pool = Executors.newScheduledThreadPool(10),该方法也返回一个
ScheduledExecutorService对象,但是可以给该线程池指定线程数量,这里指定为10。
下面举一个实例来看看具体的使用个,这里以newFixedThreadPool()为例:
public class ThreadPoolDemo {
public static class MyTask implements Runnable{
@Override
public void run() {
System.out.println(System.currentTimeMillis()+":Thread ID:"
+Thread.currentThread().getId());
try{
Thread.sleep(1000);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask task = new MyTask();
ExecutorService es = Executors.newFixedThreadPool(5);
for(int i = 0;i<10;i++){
es.execute(task);
}
}
}
安排
调度这10个任务。每个任务都会讲自己的执行时间和执行这个线程的ID打印出来,并且在这里,安排每个任务执行1秒钟。
得到的结果如下:
1504283763066:Thread ID:10
1504283763066:Thread ID:9
1504283763066:Thread ID:12
1504283763067:Thread ID:13
1504283763067:Thread ID:11
1504283764066:Thread ID:9
1504283764066:Thread ID:10
1504283764066:Thread ID:12
1504283764067:Thread ID:11
1504283764067:Thread ID:13
(四)线程池的内部实现
首先我们先看newFixedThreadPool()和newCachedThreadPool()的内部实现,之所以选它们,因为它们具有代表性。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
} public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) - corePoolSize:指定了线程池中的线程数量
- maximumPoolSize:制定了线程池中的最大线程数量。
- keepAliveTime:当前线程池数量超过corePoolSize时,多余的空闲线程的存活时间。
- unit:keepAliveTime的单位
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可,也可以自己实现。
- handler:拒绝策略。当任务太多来不及处理,如果拒绝任务。
(1)workQueue参数
参数workQueue指被提交但未执行的任务队列,它是一个BlockingQueue接口的对象,仅用来存放Runnable对象。
接下来
介绍几个主要的任务队列,它们都是实现了BlockingQueue
(a)直接提交的队列:该功能有SynchronousQueue对象提供。SynchronousQueue是一个特殊的BlockingQueue。
SynchronousQueue没哟容量,每一个插入操作都要等待一个相应的删除操作,反之,也是一样。如果我们使用
SynchronousQueue
,提交的任务不会保存在
SynchronousQueue中(这里
SynchronousQueue的内部实现大家可以查阅
一下资料,这里不详细说了
),
而总是将新任务提交给线程执行,如果没有空闲的进程,则尝试创建新的进程,如果进程
数量已经达到最大值,执行拒绝策略。因此
,使用
SynchronousQueue队列,通常设置很大的maximumPoolSize值,
否则很容易执行拒绝策略。
(b)有界的任务队列:有界的任务队列可以使用ArrayBlockingQueue实现。因为它是基于数组实现的,这样我们
初始化一个固定
容量即可。当时用有界的任务队列时。若有新的任务需要执行,如果线程池的实际线程数小于
corePoolSize,
则会优先创建新的线程,
若大于
corePoolSize,则会将新任务加入等待队列。若等待队列已满,无法加入,则在总线程数
不大于
maximumPoolSize的前提下,
创建新的进程执行任务。若大于
maximumPoolSize,则执行拒绝策略。
(c)无界任务队列:无界任务队列可以通过LinkedBlockingQueue类实现。与有界队列相比,除非系统资源耗尽,
否则无界的
任务队列不存在任务入队失败的情况。当新任务到来,系统的线程数小于
corePoolSize时,线程池会生成新的
线程执行任务,但当
系统的线程数达到
corePoolSize后,就不会继续增加。若后续仍有新的任务加入,而没有空闲的线程资源,
则任务直接进入队列等待。
说完workQueue参数再来看看newFixedThreadPool()和newCachedThreadPool()两个方法的内部实现,第一个方法
返回一个
corePoolSize和
maximumPoolSize大小一样的,并且使用了
LinkedBlockingQueue任务队列的线程池。第二个方法
返回
corePoolSize
为0,
maximumPoolSize无穷大的线程池,该线程池内无线程,而当任务被提交时,该线程池会使用空闲
的线程执行任务,若无
空闲线程,则将任务加入
SynchronousQueue队列,而
SynchronousQueue队列是一种直接提交的队列,
它总会迫使线程池增加新的
线程执行任务。对于
newCachedThreadPool(),如果同时有大量任务被提交,而任务的执行又不
那么快,那么系统便会开启大量的
线程处理,这样做很快会耗尽系统资源。
ThreadPoolExecutor线程池的核心调度代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
代码第5行的workerCountOf()函数取得当前线程的线程总数。当线程总数小于corePoolSize核心线程数是,会将
任务通过addWorker()方法直接调度执行。否则,则在第10行代码workQueue.offer()进入等列。如果进入等待失败,
则会执行第17行,将任务直接提交给线程池。如果当前线程数已经达到maximumPoolSize,则提交失败,执行
最后一行代码。
逻辑图如下:

(2)handler参数
ThreadPoolExecutor的这个参数制定了拒绝策略。也就是当任务数量超过系统实际承载能力时,
ThreadPoolExecutor需要执行的拒绝策略。JDK默认有自己的默认拒绝策略。
接下来我们实现RejectedExecutionHandler自定义一个自己的拒绝策略:
public class ThreadPoolDemo {
public static class MyTask implements Runnable{
@Override
public void run() {
System.out.println(System.currentTimeMillis()+":Thread ID:"
+Thread.currentThread().getId());
try{
Thread.sleep(100);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS,
new LinkedBlockingDeque(10),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor)
{ System.out.println(r.toString()+"is discard");
}
});
for(int i =0;i 上面代码定义了corePoolSize和maximumPoolSize都是5的线程池。如果理解线程池的执行原理的话,这段代码
肯定会执行拒绝策略,上面代码使用了自定义线程池,使用的是自定义的拒绝策略,所以拒绝策略会按照我们
自己实现的rejectedExecution()方法执行。下面我截取了部分结果:
1504289276848:Thread ID:9
1504289276858:Thread ID:10
demo.ThreadPoolDemo$MyTask@28d76d1eis discard
demo.ThreadPoolDemo$MyTask@28d76d1eis discard
1504289276889:Thread ID:11
1504289276892:Thread ID:13