机器学习概念总结笔记(三)——分类决策树C4.5、集成学习Bagging算法Boosting算法随机森林算法迭代决策树算法、
原文:https://cloud.tencent.com/community/article/161873
12)分类决策树C4.5
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;2) 在树构造过程中进行剪枝;3) 能够完成对连续属性的离散化处理;4) 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
构建一个决策树时,有2个重点,第一个是构建树的过程中首先选择哪个属性进行判断,即选择哪个属性作为根节点。 这个叫做属性选择度量,度量方式常见的有3种, ID3使用信息增益度, C4.5采用信息增益率, CART采用GINI指标。第二个是如何修剪这棵树,即减枝。
信息增益率使用“分裂信息”值将信息增益规范化。分类信息类似于Info(D),定义如下:
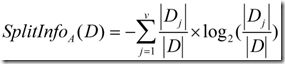
这个值表示通过将训练数据集D划分成对应于属性A测试的v个输出的v个划分产生的信息。信息增益率定义: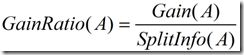
选择具有最大增益率的属性作为分裂属性。
13)集成学习
集成学习(英文: Ensemble Learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。集成学习的思路是在对新的实例进行分类的时候,把若干个单个分类器集成起来,通过对多个分类器的分类结果进行某种组合来决定最终的分类,以取得比单个分类器更好的性能。如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
集成学习方法是机器学习领域中用来提升分类算法准确率的技术,主要包括Bagging和Boosting即装袋和提升。
14)集成学习之Bagging算法
装袋算法(bagging)采取自助法的思路,从样本中随机抽样,形成多个训练样本,生成多个树模型。然后以多数投票的方式来预测结果。相同的分类器,各个分类器是独立的;使用同一个算法对样本多次训练,建立多个独立的分类器;最终的输出为各个分类器的投票(用于分类)或取平均值(用于数值预测)。
15)集成学习之Boosting算法
Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。他是一种框架算法,主要是通过对样本集的操作获得样本子集,然后用弱分类算法在样本子集上训练生成一系列的基分类器。他可以用来提高其他弱分类算法的识别率,也就是将其他的弱分类算法作为基分类算法放于Boosting 框架中,通过Boosting框架对训练样本集的操作,得到不同的训练样本子集,用该样本子集去训练生成基分类器;每得到一个样本集就用该基分类算法在该样本集上产生一个基分类器,这样在给定训练轮数 n 后,就可产生 n 个基分类器,然后Boosting框架算法将这 n个基分类器进行加权融合,产生一个最后的结果分类器,在这 n个基分类器中,每个单个的分类器的识别率不一定很高,但他们联合后的结果有很高的识别率,这样便提高了该弱分类算法的识别率。在产生单个的基分类器时可用相同的分类算法,也可用不同的分类算法,这些算法一般是不稳定的弱分类算法,如神经网络(BP) ,决策树(C4.5)等。
Boosting最早由Schapire 提出,Freund 对其进行了改进。通过这种方法可以产生一系列神经网络,各网络的训练集决定于在其之前产生的网络的表现,被已有网络错误判断的示例将以较大的概率出现在新网络的训练集中。这样,新网络将能够很好地处理对已有网络来说很困难的示例。另一方面,虽然Boosting方法能够增强神经网络集成的泛化能力,但是同时也有可能使集成过分偏向于某几个特别困难的示例。因此,该方法不太稳定,有时能起到很好的作用,有时却没有效果 。值得注意的是,Schapire 和Freund 的算法在解决实际问题时有一个重大缺陷,即它们都要求事先知道弱学习算法学习正确率的下限,这在实际问题中很难做到。1995年,Freund和Schapire 提出了AdaBoost(Adaptive Boost)算法,该算法的效率与Freund算法 很接近,却可以非常容易地应用到实际问题中,因此,该算法已成为目前最流行的Boosting算法。
Bagging 方法中,各神经网络的训练集由从原始训练集中随机选取若干示例组成,训练集的规模通常与原始训练集相当,训练例允许重复选取。这样,原始训练集中某些示例可能在新的训练集中出现多次,而另外一些示例则可能一次也不出现。Bagging方法通过重新选取训练集增加了神经网络集成的差异度,从而提高了泛化能力。Breiman 指出,稳定性是Bagging能否发挥作用的关键因素,Bagging能提高不稳定学习算法的预测精度,而对稳定的学习算法效果不明显,有时甚至使预测精度降低。学习算法的稳定性是指如果训练集有较小的变化,学习结果不会发生较大变化,例如,k最近邻方法是稳定的,而判定树、神经网络等方法是不稳定的。
Bagging与Boosting 的区别在于Bagging 的训练集的选择是随机的,各轮训练集之间相互独立,而Boosting的训练集的选择不是独立的,各轮训练集的选择与前面各轮的学习结果有关;Bagging 的各个预测函数没有权重,而Boosting是有权重的;Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。对于象神经网络这样极为耗时的学习方法,Bagging可通过并行训练节省大量时间开销。
此外还存在多种个体生成方法。例如,有些研究者 利用遗传算法来产生神经网络集成中的个体;有些研究者使用不同的目标函数、隐层神经元数、权空间初始点等来训练不同的网络,从而获得神经网络集成的个体。
16)集成学习之随机森林算法
随机森林(Random Forest算法),指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出,并被注册成了商标。简单来说,随机森林就是由多棵CART(Classification And Regression Tree)构成的。对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回的抽取的,根据Leo Breiman的建议,假设总的特征数量为M,这个比例可以是sqrt(M),1/2sqrt(M),2sqrt(M)。
因此,随机森林的训练过程可以总结如下:
(1)给定训练集S,测试集T,特征维数F。确定参数:使用到的CART的数量t,每棵树的深度d,每个节点使用到的特征数量f,终止条件:节点上最少样本数s,节点上最少的信息增益m,对于第1-t棵树,i=1-t
(2)从S中有放回的抽取大小和S一样的训练集S(i),作为根节点的样本,从根节点开始训练。
(3)如果当前节点上达到终止条件,则设置当前节点为叶子节点,如果是分类问题,该叶子节点的预测输出为当前节点样本集合中数量最多的那一类c(j),概率p为c(j)占当前样本集的比例;如果是回归问题,预测输出为当前节点样本集各个样本值的平均值。然后继续训练其他节点。如果当前节点没有达到终止条件,则从F维特征中无放回的随机选取f维特征。利用这f维特征,寻找分类效果最好的一维特征k及其阈值th,当前节点上样本第k维特征小于th的样本被划分到左节点,其余的被划分到右节点。继续训练其他节点。有关分类效果的评判标准在后面会讲。
(4)重复(2)(3)直到所有节点都训练过了或者被标记为叶子节点。
(5)重复(2),(3),(4)直到所有CART都被训练过。
利用随机森林的预测过程如下:
对于第1-t棵树,i=1-t:
(1)从当前树的根节点开始,根据当前节点的阈值th,判断是进入左节点(
(2)重复执行(1)直到所有t棵树都输出了预测值。如果是分类问题,则输出为所有树中预测概率总和最大的那一个类,即对每个c(j)的p进行累计;如果是回归问题,则输出为所有树的输出的平均值。
17)集成学习之迭代决策树算法
GBDT(Gradient Boosting Decision Tree迭代决策树) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。
GBDT有3个特征。 第一个是构建GBDT的树是回归决策树, 第二个是采用梯度迭代Gradient Boosting, 第三个是Shrinkage缩减技术。
回归树 Regression Decision Tree,提起决策树(DT, Decision Tree) 绝大部分人首先想到的就是C4.5分类决策树。但如果一开始就把GBDT中的树想成分类树,那就是一条歪路走到黑,一路各种坑,所以说千万不要以为GBDT是很多棵分类树。决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;后者用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。这里要强调的是,前者的结果加减是有意义的,如10岁+5岁-3岁=12岁,后者则无意义,如男+男+女=到底是男是女? GBDT的核心在于累加所有树的结果作为最终结果,就像前面对年龄的累加(-3是加负3),而分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树,不是分类树,这点对理解GBDT相当重要(尽管GBDT调整后也可用于分类但不代表GBDT的树是分类树)。
Boosting,迭代,即通过迭代多棵树来共同决策。这怎么实现呢?难道是每棵树独立训练一遍,比如A这个人,第一棵树认为是10岁,第二棵树认为是0岁,第三棵树认为是20岁,我们就取平均值10岁做最终结论?--当然不是!且不说这是投票方法并不是GBDT,只要训练集不变,独立训练三次的三棵树必定完全相同,这样做完全没有意义。之前说过,GBDT是把所有树的结论累加起来做最终结论的,所以可以想到每棵树的结论并不是年龄本身,而是年龄的一个累加量。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义。
Shrinkage(缩减)的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。用方程来看更清晰,即没用Shrinkage时:(yi表示第i棵树上y的预测值, y(1~i)表示前i棵树y的综合预测值)
y(i+1) = 残差(y1~yi), 其中: 残差(y1~yi) = y真实值 - y(1 ~ i)
y(1 ~ i) = SUM(y1, ..., yi)
Shrinkage不改变第一个方程,只把第二个方程改为:
y(1 ~ i) = y(1 ~ i-1) + step * yi
即Shrinkage仍然以残差作为学习目标,但对于残差学习出来的结果,只累加一小部分(step残差)逐步逼近目标,step一般都比较小,如0.01~0.001(注意该step非gradient的step),导致各个树的残差是渐变的而不是陡变的。直觉上这也很好理解,不像直接用残差一步修复误差,而是只修复一点点,其实就是把大步切成了很多小步。本质上,*Shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,但和Gradient并没有关系。这个weight就是step。就像Adaboost一样,Shrinkage能减少过拟合发生也是经验证明的,目前还没有看到从理论的证明。
18)Boosting算法之AdaBoost算法
boosting方法有许多不同的变形。其中最流行的一种就是AdaBoost方法,这个名称是“adaptive boosting”的缩写。这个方法允许设计者不断地加入新的“弱分类器”,直到达到某个预定的足够小的误差率。在AdaBoost方法中,每一个训练样本都被赋予一个权重,表明它被某个分类分类器选入训练集的概率。如果某个样本点已经被准确分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被正确分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能够“聚焦于”较为困难(更富有信息)的样本上。在具体实现上,最初令每一个样本的权重都相同,对于第k次迭代操作,我们就根据这些权重来选取样本点,进而训练分类器,然后根据这个分类器来提高被他错分的那些样本点的权重,并降低被正确分类的样本权重。

19)KNN
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
算法流程如下:1. 准备数据,对数据进行预处理;2. 选用合适的数据结构存储训练数据和测试元组;3. 设定参数,如k;4.维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列;5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax;6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值;
KNN的优点在于:1.简单,易于理解,易于实现,无需估计参数,无需训练;2. 适合对稀有事件进行分类;3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
KNN的缺点在于:该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。可理解性差,无法给出像决策树那样的规则。
20)神经网络
人工神经元是神经网络的基本元素,其原理可以用下图表示:
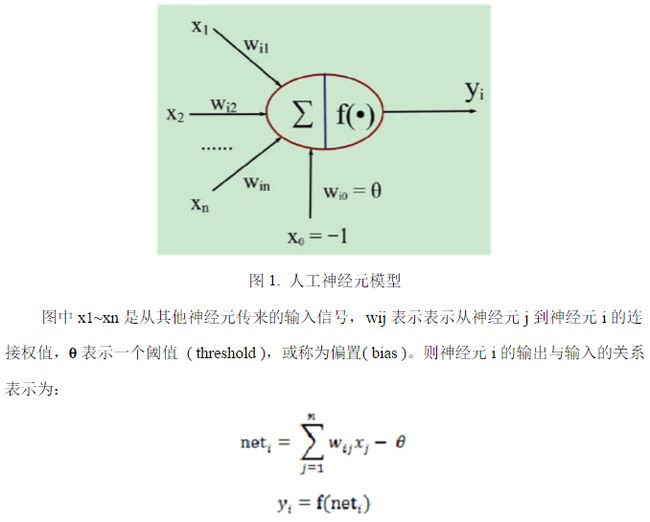
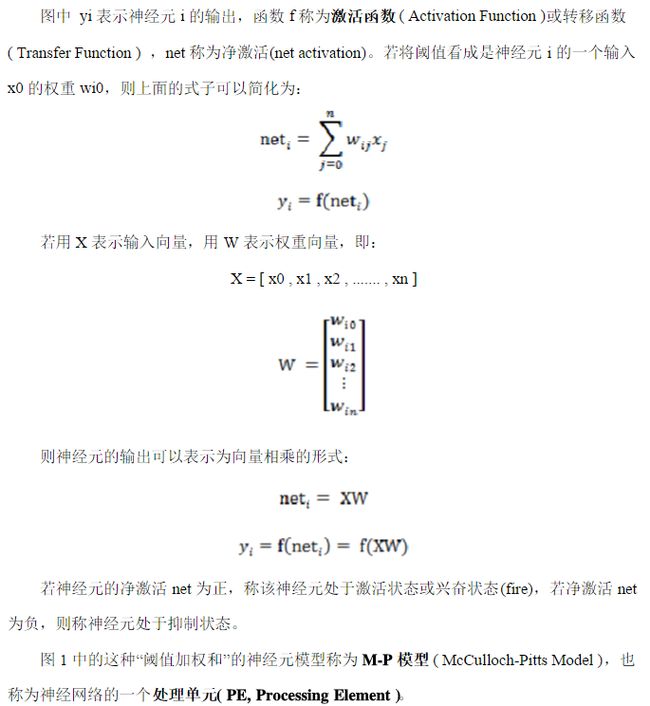
常见的激活函数有以下5类:

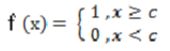

神经网络是由大量的神经元互联而构成的网络。根据网络中神经元的互联方式,常见网络结构主要可以分为下面3类:
(1) 前馈神经网络 ( Feedforward Neural Networks ) 前馈网络也称前向网络。这种网络只在训练过程会有反馈信号,而在分类过程中数据只能向前传送,直到到达输出层,层间没有向后的反馈信号,因此被称为前馈网络。感知机( perceptron)与BP神经网络就属于前馈网络。图4是一个3层的前馈神经网络,其中第一层是输入单元,第二层称为隐含层,第三层称为输出层(输入单元不是神经元,因此图中有2层神经元)
(2) 反馈神经网络(Feedback Neural Networks ) 反馈型神经网络是一种从输出到输入具有反馈连接的神经网络,其结构比前馈网络要复杂得多。典型的反馈型神经网络有:Elman网络和Hopfield网络;
(3) 自组织网络 ( SOM ,Self-Organizing Neural Networks )自组织神经网络是一种无监督学习网络。它通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构;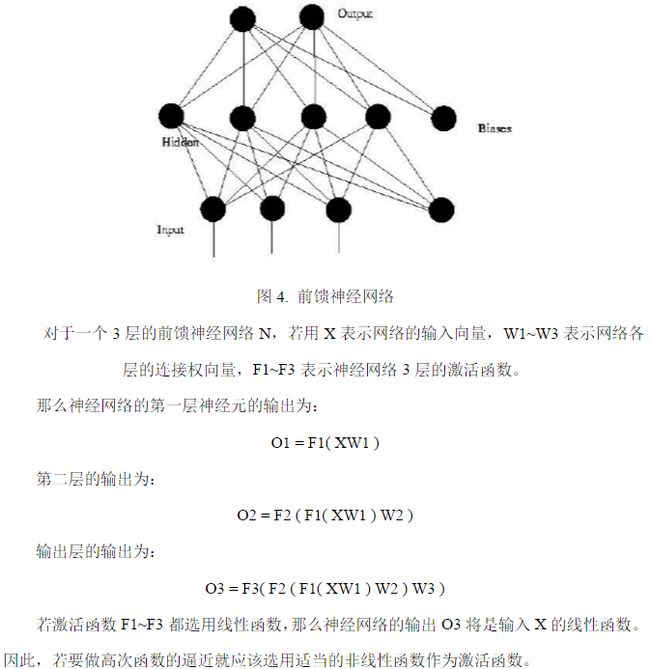

"BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。"
BP是后向传播的英文缩写,那么传播对象是什么?传播的目的是什么?传播的方式是后向,可这又是什么意思呢。传播的对象是误差,传播的目的是得到所有层的估计误差,后向是说由后层误差推导前层误差:
BP的思想可以总结为利用输出后的误差来估计输出层的直接前导层的误差,再用这个误差估计更前一层的误差,如此一层一层的反传下去,就获得了所有其他各层的误差估计。 BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。BP利用一种称为激活函数来描述层与层输出之间的关系,从而模拟各层神经元之间的交互反应。激活函数必须满足处处可导的条件。