GitFlow分支模型下的代码全量格式化流程
全量格式化还是渐进格式化?
对于一个历史悠久又没有执行强制代码规范的代码库,全量格式化看起来是一件风险不可控的事情:它产生了大量的难以评估的格式改动,也使得格式化以后的代码库运行git blame几乎都会定位到进行格式化的人(而非是这段逻辑的上一次有意义的修改者)。相比之下,理想的做法似乎应该是渐进格式化:对于新代码,使用强制的代码规范;对于老代码,除非它被修改,不然不进行强制代码规范。
真的是这样子吗?
全量格式化风险并不随代码量变大而显著变大。
全量格式化往往会产生改变巨大的提交,代码改变得越多,看起来引入问题的风险就会越大。然而,对于代码格式器而言,代码格式器需要处理的是语言规范里面定义的有限几种语法结构的组合,绝大部分的业务逻辑代码都不会有像编译器的测试用例一般复杂的语法结构,对于代码格式器而言,只要代码库中的语法结构都被测试覆盖,改一百行代码和改十万行代码并没有本质区别。换言之,如果代码格式器出错,那么导致的代码错误一定很容易被查出来(因为同样的语法结构在系统各个角落都会用到)。只要十万行代码用到的语法结构组合不是一百行代码的语法结构组合的一千倍,那么全量格式化十万行代码引入的问题就不会是只格式化一百行代码的一百倍,因此全量格式化代码引入的风险关于代码量完全不成线性关系。
一致的代码风格降低开发成本。
全量格式化立刻使得代码库形成一致的代码风格,项目的每一个开发者都会备受鼓舞,一致的风格让开发者的阅读流不必被异常的代码格式阻断,对代码块的视觉识别也更加迅速(你的大脑很快习得了function后面一个空格的位置一定是一组参数,你不必为多一个或者少一个空格而额外消耗认知能力),配合上代码提交阶段的自动格式化,开发者甚至可以在开发过程中完全不需理会代码格式——反正最后提交时都会被计算机誊抄一遍进入到代码库中。
增量格式化容易扩大化合并时的代码冲突。
可是渐进代码格式化给我更多的安全感?在 GitFlow 的分支管理模式中,假设一个未被格式化的文件分别在特性分支和补丁分支有了改动,那么改动将会触发该文件的格式化,我们会在后面指出——当两个分支的同一个文件分别进行化后,合并时的冲突块大小将会被格式化放大(因为 git 并不理解哪些改动是格式化,哪些改动是修改业务逻辑),很快你将会淹没在无处不在的合并冲突之中,更糟糕的是,因为 git 不理解格式化和业务逻辑修改的区别,你需要仔细核对才能知道哪些改动压根没有修改业务逻辑,这无疑增大了合并的时候错漏的风险。
那么,不如毕其功于一役吧。
如何全量格式化GitFlow分支模型代码库?
下图一个典型的采用 GitFlow 分支模型的代码库历史图:
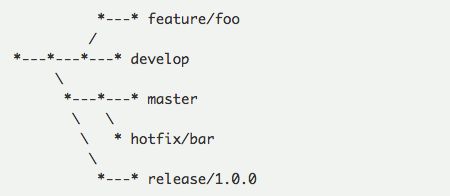
在 GitFlow 模型中,考察分支的生命周期,假设所有分支都是根据需求合理存在的,可以发现:
所有的 release 分支都是历史分支,它们不会再汇入到 master 分支
所有的 hotfix 分支都将汇入 master 分支,hotfix 分支生命周期很短
每一次发小版本的时候,master 分支作为 hotfix 的汇入者,也会汇入到 develop 分支
每一次发大版本的时候,develop 分支会汇入到 master 分支,并从新的 master 分支拉出 release 分支
所有的 feature 分支都将汇入 develop 分支
根据这个生命周期,我们可以按照以下策略对代码库进行格式化,下面我们简称这个策略为两步格式化:
一,准备代码格式化配置。对所有活跃分支准备好代码格式器的配置,我们不推荐全局安装代码格式器,而是把代码格式器作为项目的开发依赖,这样历史版本可以用老版本的代码格式器,新代码可以用到新的代码格式器。你可以从开发分支拉出一个分支增加格式器配置,再遴选到各个活跃分支。只添加格式化配置对代码业务不会产生影响。
二,挑选一个合适的时间点进行批量的格式化处理。我们建议是在刚发完小版本之后,此时 master 刚刚汇入 develop 分支。然后再将 develop 分支都汇入到开发中的 feature 分支。此时历史如图所示。
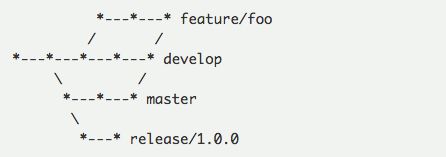
这个时候,这些分支的领先程度满足下面的关系:

这里的>是严格领先,也就是 feature 分支包含了 develop 分支的所有改动,develop 分支包含了 master 分支的所有改动。
三,单独对历史分支格式化。 对所有的还在维护的 release 分支,进行全量格式化,通过测试后提交,在下面的历史图中,我们简单记 release/1.0.0 的全量格式化 commit 为 O。
四,格式化 master 分支。 从 master 分支新开一个专门进行格式化的 hotfix 分支,进行全量格式化,测试无误后,汇入到 master 分支,记这个格式化的 commit 为 A,此时历史如图所示。

五,合并 develop 分支,使用 ours 策略消解冲突。 将此时的 master 分支再次汇入到 develop 分支,如果有冲突,使用 develop 分支的文件:

这里的-s ours指的是合并时的冲突消解策略。因为我们的分支满足上述的严格领先关系,develop 一定拥有所有 master 的改动,而 master 此时除了进行代码格式化,没有任何的业务逻辑改动(只要格式化工具不出错),因此冲突产生的原因一定不是业务逻辑产生的代码冲突,对于这些冲突,我们使用 develop 的文件一定不会影响代码业务;反过来,如果没有冲突,说明对这个文件进行格式化,大概率等同于将 master 分支的格式化改动合并过来的效果,因此,我们可以直接沿用这些格式化改动。记这个合并的 commit 为 M.
六,再次全量格式化 develop分支。 我们使用了 develop 分支自己的文件来消解冲突,而 develop 自己的文件是没有格式化的,因此,在合并完成后,我们再次进行全量的代码格式化,记这个格式化的 commit 为 B,此时分支历史如图所示。

现在,develop 和 master 仍然保持着严格领先的特点。
七,对于 feature 分支,重复上述步骤,将 develop 汇入 feature。 在下面的例子中,我们记 feature/foo 分支格式化的 commit 为 C,容易知道,格式化完成后,此时的分支历史如图所示。

进行完这个流程后,我们仍旧保持着 feature 分支 > develop 分支 > master 分支的严格领先关系。
仔细考察此时的 develop 分支,我们发现 develop 分支的格式化实际上是两个 commit A 和 B 共同作用的效果。通过这种合并策略,我们相当于告诉 git,
并且,所有格式化 A 导致的代码冲突已经在 M 得到消解,M 点的版本一定是可用的,而 develop 的代码符合规范又通过 commit B 得到了保证。
这样,当下一次发小版本时,master 汇入了新的 hotfix 并且再回流到 develop 时,我们一定无需处理格式化 A 导致的代码冲突,新的可能的冲突一定是 develop 新增的业务逻辑与 hotfix 改动之间的冲突——我们回到了格式化之前的冲突原因。
同时,当下一次发大版本时,由于 develop 总是领先于 master,并且 A 导致的代码冲突已经在 M 中得到了消解,我们也不会遇到合并冲突。
至此(请记住我们的地址:www.easyops.cn),我们完成了对代码库的全量格式化。
为什么不能对每一个分支做格式化再合并?
对每一个分支进行格式化是最容易想到的全量格式化方式,但它会扩大冲突块的大小,因为 git 只会记录文件改动,它不知道哪一些是代码格式化的改动,哪一些是业务逻辑的改动,我们不妨看一段简单的代码,看看格式化后的冲突块大小。为了简单起见,考虑只有 master 和 develop 分支的情形,源代码只有一个叫做 index.js 的文件。你也可以在这个仓库查看这个小项目的源代码与分支历史。此时历史如图所示。

各个 commit 的 index.js 内容如下表显示:

显然当 master 汇入到 develop 时,将会产生冲突,现在,我们分别格式化两个分支,并进行合并,此时index.js的冲突如图:

显然,因为格式化与业务逻辑的变更混在了一起,此时整个index.js都发生了冲突,仔细观察 module.exports = function(foo) { 一行,显然这一行是格式化修改后的结果,业务逻辑修改与这一行无关,但由于分别格式化了原本就有冲突的分支,此时合并的时候格式化的改动也被视作冲突了(同时在不同的 commit 基础上把这一行改动成了module.exports = function(foo) {),因此,冲突块扩大了。
为什么不能合并完保持分支领先关系后,再对每一个分支分别格式化?
现在我们先将 master 合并到 develop 消解冲突,再分别进行格式化,此时历史如图。

其中F和E是格式化的 commit,现在我们把格式化后的 E 合并到 D,我们预期应该不会有业务逻辑产生的冲突,因为 B 和 C 的冲突在 D 中已经消解过了,然而,由于 E 和 F 都分别格式化了 C 和 D 中的内容,此时产生了单纯由格式化产生的冲突。

这个冲突和上面居然是一样的。这是因为在 D 中我们可以单纯地使用 B 作为消解冲突的方式,最后的结果和分别格式化分支是一样的。尽管这是冲突消解的一个特例,但这已经能证明,即便是在消解后严格领先的分支进行分别格式化,依然有可能扩大冲突块的规模。
使用两步格式化策略后的 hotfix 合并
使用两步格式化后的 git 历史如图:

其中 E 是对 master 分支的格式化,G 是对 develop 分支的增量格式化,我们下面对 master 分支进行一个 hotfix G

此时 F 的文件内容为:

显然,G 的改动将会与 F 冲突,此时将 G 合并到 F,冲突如下:

冲突块清晰地定位在module.exports函数的变更冲突,master 对foo做了校验,develop 又重构了bar函数,与上面例子中module.exports = function(foo) {被标记成冲突比起来,此时代码风格的变更均不引起冲突。业务逻辑导致的代码冲突被隔离了出来。
附录:
如何在 git blame 中忽略掉庞大的全量格式化 commit,保证 git blame 的返回某一行与业务相关的修改信息?
截至2017年12月,git blame 不支持忽略某一个 commit。 Google 的 chrome 团队架构工具提供了 git blame 的一个替代命令:git-hyper-blame, 该命令支持项目指定 git blame 忽略掉一些特定 commit。macOS 用户可以通过:

来安装。只有.git-blame-ignore-revs文件中有全量格式化的 commit,例如:
那么使用git hyper-blame就可以指定 blame 的时候忽略 21dad2b6c508a637be41de85cac07699ddbd1485 这个 commit。
总结:
只要格式化工具的测试样例覆盖了足够全的语法结构,全量格式化并不是一件风险不可控的事情。对于 GitFlow 分支模型的项目,从 master 分支出发,按照合并——消解——增量格式化的两步格式化策略,就可以轻松地让整个项目代码风格统一。后续配合 pre-commit 的自动格式化钩子,可以保证项目的代码风格是永续一致的。
作者:黄俊亮(Jay),优维科技资深DevOps前端开发专家,OpenSSL、node.js等开源项目贡献者,前端外刊特约评论/撰稿人。