X(xpath)一下梨视频中的美女小姐姐
预备
安装的库:requests lxml
#windows+r cmd
pip install requests
pip install lxml
爬什么好呢??
梨视频
汽车板块是不是有好多。。。
小姐姐?
emmm
走你 路径提取~
import requests
from lxml import etree
url = 'https://www.pearvideo.com/category_31'
res = requests.get(url)
res_xpath = etree.HTML(res.text) 'etree.HTML 解析res'
试着抓取一些东西
比如说标题

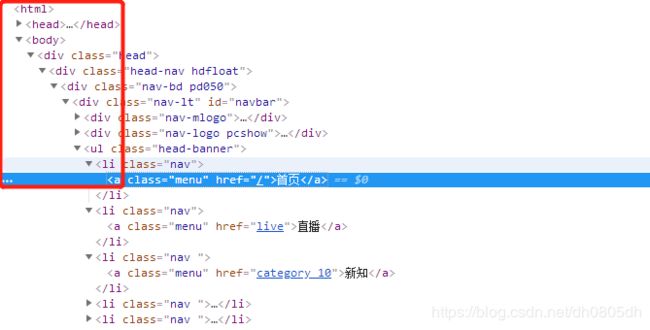
右键点击"首页",点击审查元素,找到对应的标签
右键copy- - copy xpath
'//*[@id="navbar"]/ul/li[1]/a' '这个是复制到的xpath'
menu = res_xpath.xpath('//*[@id="navbar"]/ul/li[1]/a/text()')
'结尾+/text()使得提取出的东西变为文本'
print(menu)
输出结果为
['首页']
这个只是标题之一
也就是指定属性的提取
但是需要的是所有标题
所以寻找所有标题的共同点
//*[@id="navbar"]/ul/li[2]/a 这个是标题中的'直播'的xpath
//*[@id="navbar"]/ul/li[3]/a 这个是标题中的'新知'的xpath
'由此发现,不同点是li[] 所以直接 [] 中填*'
menu = res_xpath.xpath('//*[@id="navbar"]/ul/li[*]/a/text()')
print(menu)
输出结果为
['首页', '直播', '新知', '社会', '世界', '体育', '生活', '科技', '娱乐', '财富', '汽车', '美食', '音乐', '拍客', '万象', '排行榜', '更多']
搜索xpath时候,有两种提取方式,一种是绝对路径,另一种是相对路径。
简单的说,绝对路径就是
menu = res_xpath.xpath('/html/body/div/div/div/div/ul/li/a/text()')
print(menu)
输出结果为
['首页', '直播', '新知', '社会', '世界', '体育', '生活', '科技', '娱乐', '财富', '汽车', '美食', '音乐', '拍客', '万象', '排行榜', '更多', '下载APP']
相对路径的话就是
‘//’ + 限制条件 其中下面的a标签中的限制条件为属性class和href
用到的了 标签+[ ] , [ ] 中要加属性或者其他限制条件
类似于计算机的ctrl+f中输出的关键字
简单来说就是
menu = res_xpath.xpath('//a[@class="menu"]/text()')
print(menu)
输出结果为
['首页', '直播', '新知', '社会', '世界', '体育', '生活', '科技', '娱乐', '财富', '汽车', '美食', '音乐', '拍客', '万象', '排行榜', '拍客', '万象', '排行榜']
啥是标签中的属性?
前面提到了标签中的属性
emmm
首先,@是和属性密不可分的
在定位到标签中之后
需要用@+属性来详细定位

class 和 href就是标签中的属性
不是说爬小姐姐视频么
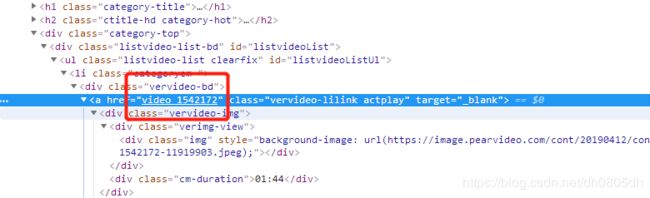
这就是我们的目标
我们需要得到新一个URL = ‘https://www.pearvideo.com/video_1542172’
这个URL就是视频的链接,而video_1542172就是上面红色框中的内容
这种URL结构很好完成
且听我细细道来
video 在href属性中
对应的href属性在a标签中
a标签又在div标签下
div标签又在li标签下
这时候
突然我发现事情并没有这么简单

一个个li标签下就是每个视频的属性诶~
也就是video+编号
啥也别说了
X他
右键X他
想办法把每个视频的标签下的属性搞出来
撒子是个提取属性
前面撒子是个属性应该了解了
那么提取属性就很简单啦
比如说提取这个href属性

还要X一下。。。
右键li标签得到
//*[@id="categoryList"]/li[2]
temp = res_xpath.xpath('//*[@id="categoryList"]/li[2]/div[@class="vervideo-bd"]/a/@href')
print(temp)
-->
['video_1544665']
懂了吧~
是不是很简单
出来吧,皮卡丘(二次提取)
二次提取
顾名思义
提取次数为2
其实就是因为每个li标签下面都放着关于视频编号的属性
所以先把每个li标签提取出来
之后再对li标签进行提取
取出来属性
这样更有逻辑性也更加方便操作一些
右键x出来的东西是这个
//*[@id="categoryList"]/li[1]
第二个视频右键x出来的东西是
//*[@id="categoryList"]/li[2]
显然。。。。
[]号内是第几个视频。。。
而且 * 这个搜索方式从一开始搜索一遍一遍又一遍
是有点浪费资源的。。。
所以小小的辅助优化一下
![]()
ul标签下的li标签
所以
//ul[@id="categoryList"]/li
这个才是我们需要的
所以走起~
li = res_xpath.xpath('ul[@id="categoryList"]/li')
print(li)
-->
[<Element li at 0x39d1208>, <Element li at 0x39d11c8>, <Element li at 0x39d1088>, <Element li at 0x39d1188>, <Element li at 0x3a3e688>, <Element li at 0x3a3e588>, <Element li at 0x3a3e5c8>, <Element li at 0x3a3e508>, <Element li at 0x3a3e648>]
得到列表~
当然还有一个法子得到他
那就是不需要去右键li标签直接右键ul标签
然后后面补一下li~同理的
看好了,二次提取出现啦
for li_xpath in li:
li_video = li_xpath.xpath('./div/a/@href')
print(li_video)
-->
['detail_1543766']
['video_1544665']
['video_1544673']
['video_1544672']
['video_1544147']
['video_1544150']
['detail_1543892']
['video_1544175']
['video_1544141']
over
温馨提示
detail那个是广告哦,记得用if语句和他们say
byebye
下面的操作还需要我说嘛
话不多说直接上全代码吧~
import requests
import re
from lxml import etree
url = 'https://www.pearvideo.com/category_31'
res = requests.get(url)
res_xpath = etree.HTML(res.text)
#menu = res_xpath.xpath('//a[@class="menu"]/text()')
#print(menu)
#抓取所有分类标签
li = res_xpath.xpath('//ul[@id="categoryList"]/li')
#print(li)
#提取li标签为二次提取准备
# for li_xpath in li:
# li_video = li_xpath.xpath('./div/a/@href')
# print(li_video)
#二次提取出视频编号
for li_xpath in li:
li_video = li_xpath.xpath('./div/a/@href')
if 'detail' in li_video[0]:
pass
else:
number = li_video[0]
url1 = 'https://www.pearvideo.com/' + li_video[0]
res_video = requests.get(url1)
video_url = re.findall('srcUrl="(.*?)"',res_video.text,re.S)[0]
response = requests.get(video_url)
video_name = li_xpath.xpath('./div/a/div[@class="vervideo-title"]/text()')[0]
with open (video_name + '.mp4','wb') as f:
f.write(response.content)
这样就把除了广告的视频都爬下来了~
溜了溜了~