爬虫实战-爬取豆瓣读书书籍信息
1. 豆瓣读书书籍种类列表
在下面这个URL, 我们可以获得所有的种类链接
https://book.douban.com/tag/如下图:
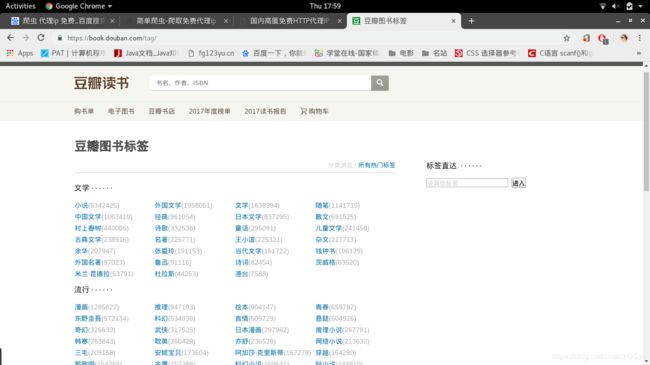
可以通过bs4和re库进行筛选, 得到所有图书种类, 结果如下:
tag_tree = {
"科技": ['科普', '互联网', '编程', '科学', '交互设计', '用户体验', '算法', '科技', 'web', 'UE', '交互', '通信', 'UCD', '神经网络', '程序'],
"经管": ['经济学', '管理', '经济', '商业', '金融', '投资', '营销', '理财', '创业', '广告', '股票', '企业史', '策划'],
"生活": ['爱情', '旅行', '成长', '生活', '心理', '励志', '女性', '摄影', '职场', '教育', '美食', '游记', '灵修', '健康', '情感', '两性', '人际关系', '手工',
'养生', '家居', '自助游'],
"文化": ['历史', '心理学', '哲学', '传记', '文化', '社会学', '艺术', '设计', '社会', '政治', '建筑', '宗教', '电影', '政治学', '数学', '中国历史', '回忆录',
'思想', '国学', '人物传记', '人文',
'音乐', '艺术史', '绘画', '戏剧', '西方哲学', '二战', '军事', '佛教', '近代史', '考古', '自由主义', '美术'],
"流行": ['漫画', '推理', '绘本', '青春', '东野圭吾',
'科幻', '言情', '悬疑', '奇幻', '武侠', '日本漫画', '韩寒', '推理小说', '耽美', '亦舒', '网络小说', '三毛', '安妮宝贝', '阿加莎·克里斯蒂', '郭敬明',
'穿越', '金庸', '科幻小说', '轻小说', '青春文学', '魔幻', '几米', '幾米', '张小娴', 'J.K.罗琳', '古龙', '高木直子', '沧月', '校园', '落落', '张悦然'],
"文学": ['小说', '外国文学', '文学', '随笔', '中国文学', '经典', '日本文学', '散文', '村上春树', '诗歌', '童话', '儿童文学', '古典文学', '王小波', '名著', '杂文',
'余华', '张爱玲', '当代文学', '钱钟书', '外国名著', '鲁迅', '诗词', '茨威格', '米兰·昆德拉', '杜拉斯', '港台']
}2.分析豆瓣图书url构造
如下, 图书种类加start来 构造url, start每次偏移量为20
https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=20&type=T3.爬取豆瓣图书
这里我们用requests来爬取网页, 用bs4来筛选图书信息,用json存储到json文件, 最后用pymysql存储到mysql数据库中。
以下为源代码:
get.json用来存储那些下载完成和未完成的种类
{"unGet": [], "Get": ["经济学", "管理", "经济", "商业", "金融", "投资", "营销", "理财", "创业", "广告", "股票", "企业史", "策划", "科普", "互联网", "编程", "科学", "交互设计", "用户体验", "算法", "科技", "web", "UE", "交互", "通信", "UCD", "神经网络", "程序", "漫画", "推理", "绘本", "青春", "东野圭吾", "科幻", "言情", "悬疑", "奇幻", "武侠", "日本漫画", "韩寒", "推理小说", "耽美", "亦舒", "网络小说", "三毛", "安妮宝贝", "阿加莎·克里斯蒂", "郭敬明", "穿越", "金庸", "科幻小说", "轻小说", "青春文学", "魔幻", "几米", "幾米", "张小娴", "J.K.罗琳", "古龙", "高木直子", "沧月", "校园", "落落", "张悦然", "历史", "心理学", "哲学", "传记", "文化", "社会学", "艺术", "设计", "社会", "政治", "建筑", "宗教", "电影", "政治学", "数学", "中国历史", "回忆录", "思想", "国学", "人物传记", "人文", "音乐", "艺术史", "绘画", "戏剧", "西方哲学", "二战", "军事", "佛教", "近代史", "考古", "自由主义", "美术", "爱情", "旅行", "成长", "生活", "心理", "励志", "女性", "摄影", "职场", "教育", "美食", "游记", "灵修", "健康", "情感", "两性", "人际关系", "手工", "养生", "家居", "自助游", "小说", "外国文学", "文学", "随笔", "中国文学", "经典", "日本文学", "散文", "村上春树", "诗歌", "童话", "儿童文学", "古典文学", "王小波", "名著", "杂文", "余华", "张爱玲", "当代文学", "钱钟书", "外国名著", "鲁迅", "诗词", "茨威格", "米兰·昆德拉", "杜拉斯", "港台"]}spider.py 维持URL序列, 爬取一个图书种类的 图书信息
# -*- coding:utf-8 -*-
from urllib.parse import quote
from util import json_dump, sleep_random
from sp import get_html_text, select
class Spider:
def __init__(self, tag):
# 爬取一个种类的豆瓣书籍信息
self.tag = tag
self.url = "https://book.douban.com/tag/" + quote(tag)
self.start = 0
def _next(self):
# 到达下一页面索引
self.start += 20
def run(self):
while True:
print("爬取:" + self.tag + str(self.start))
url = self.url + '?start=' + str(self.start) + '&type=T'
# 休息一段时间
sleep_random()
# 请求网页内容
html = get_html_text(url)
if html == None:
print('Error: html None')
return -1
# 筛选信息
books = select(html)
if books == None or books == {}:
print('结束:', self.tag)
return 0
# 保存数据
self._save(books)
# 请求下一页面
self._next()
def _save(self, ob):
path = './json/{}_{}.json'.format(self.tag, self.start // 20)
json_dump(ob, path)
sp.py 爬虫相关函数
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
from random import choice
import requests
# 用户代理
hds = [{
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
},
{
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'
},
{
'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'
},
{
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
]
def get_html_text(url):
hd = get_header()
try:
r = requests.get(url, headers=hd)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except Exception as e:
print('Error: 请求网页时, 错误', url)
return None
def get_header():
return choice(hds)
def trim(str1):
# 去除连续的空白符
# 连续的空白符, 只保留一个
list1 = list()
i = 0
str1 = str1.strip()
len1 = len(str1)
while i < len1:
if str1[i] in [' ', '\n', '\t']:
list1.append(' ')
i += 1
while i < len1 and str1[i] in [' ', '\n', '\t']:
i += 1
else:
list1.append(str1[i])
i += 1
# print(''.join(list1))
return ''.join(list1)
def select(html):
# 筛选书籍信息
soup = BeautifulSoup(html, 'lxml')
lis = soup.find_all('li', {'class': 'subject-item'})
if lis == []:
print('Error: 筛选信息时, 错误')
return None
books = list()
for li in lis:
book = dict()
# 书籍封面照片
pic_url = ''
try:
pic_url = trim(li.find('img').get('src'))
except:
pass
# 书名, 书籍链接
title = ''
book_url = ''
try:
li_h2_a = li.find('h2').find('a')
title = trim(li_h2_a.getText())
book_url = trim(li_h2_a.get('href'))
except:
pass
# 出版信息
pub = ''
try:
li_pub = li.find('div', {'class': 'pub'})
pub = trim(li_pub.getText())
except Exception as e:
pass
# 描述
desc = ''
try:
li_p = li.find('p')
desc = trim(li_p.getText())
except:
pass
# 评分
score = ''
try:
li_span = li.find('span', {'class': 'rating_nums'})
score = trim(li_span.getText())
except:
pass
# 人数
pn = ''
try:
li_pl = li.find('span', {'class': 'pl'})
pn = li_pl.getText().strip()[1:-4]
except:
pass
book['title'] = title
book['pic_url'] = pic_url
book['book_url'] = book_url
book['pub'] = pub
book['sc'] = score
book['pn'] = pn
book['ds'] = desc
books.append(book)
return books
if __name__ == '__main__':
# 测试trim
str1 = trim(' 1 1 1 12345 67890 -1')
print(str1)
path = './json/{}_{}.json'.format('c++', 100 // 20)
print(path)
# 人数可能为 整数数字, 少于10 , 目前无
# 评分可能为空, 浮点数
#
util.py
# -*- coding:utf-8 -*-
from os import listdir
from time import sleep
from random import randint
import json
def get_listdir(path):
# get a list, with path included
return listdir(path)
def sleep_random():
# sleep a random time
sleep(randint(1, 2))
def json_dump(ob, path):
with open(path, 'w') as f:
json.dump(ob, f, ensure_ascii=False)
f.close()
def json_load(path):
with open(path, 'r') as f:
string = f.read()
f.close()
return eval(string)
main.py
# -*- coding:utf-8 -*-
from util import json_load, json_dump
from spider import Spider
import copy
def main():
get = json_load('get.json')
unGet = get['unGet']
Get = get['Get']
us = copy.deepcopy(unGet)
for u in us:
s = Spider(u)
i = s.run()
if i == 0:
Get.append(u)
unGet.remove(u)
json_dump({'unGet': unGet, 'Get': Get}, './get.json')
else:
break
if __name__ == '__main__':
main()
mysqlCon.py 用于把json数据存储到mysql数据库中
# -*- coding:utf-8 -*-
from util import get_listdir, json_load
import pymysql
class MysqlCon:
def __init__(self):
self.host = 'localhost'
self.user = 'user'
self.password = 'user'
self.db = 'douban'
self.charset = 'utf8'
self.conn = None
self.cursor = None
try:
self.conn = pymysql.connect(host=self.host, user=self.user, password=self.password, db=self.db,
charset=self.charset)
self.conn.autocommit(False)
self.cursor = self.conn.cursor()
except Exception as E:
print('Exception :', E)
def __del__(self):
self.conn.close()
def insert(self, book):
try:
sql = 'INSERT INTO books(title, pic_url, url, pub, score, people_num, book_desc, book_type) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'
self.cursor.execute(sql, (
book['title'], book['pic_url'], book['book_url'], book['pub'], book['sc'], book['pn'],
book['ds'], book['type']))
self.conn.commit()
except Exception as E:
print('Insert Exception:', E)
def insert_books(self, json_name):
try:
book_list = json_load('json/' + json_name)
i = json_name.index('_')
book_type = json_name[:i]
for book in book_list:
book['type'] = book_type
self.insert(book)
except Exception as E:
print(E)
if __name__ == '__main__':
m = MysqlCon()
for json_name in get_listdir('json/'):
m.insert_books(json_name)
4.数据库(数据查询,数据清洗等工作)
select COUNT(*)
FROM books;
select *
from books
limit 20;
/* 将目前无 置位为0 */
UPDATE books
set people_num = '0'
where people_num = '目前无';
/* 将少于10 置位为10 */
UPDATE books
set people_num = '10'
where people_num = '少于10';
/*test*/
select distinct people_num
from books
order by people_num DESC;
/**/
alter table books
add column peopleNum int;
/**/
update books
set books.peopleNum = people_num + 0;
/**/
select DISTINCT title, url, pub, MAX(peopleNum)
from books
group by url
order by peopleNum DESC
limit 30;
/**/
alter table books
add column bookScore real;
/**/
update books
set score = '0'
where score = ''
or score = null;
/**/
update books
set books.bookScore = cast(score as decimal(9, 2));
/**/
alter table books
add column author varchar(255);
/**/
update books
set books.author = trim(SUBSTRING_INDEX(pub, '/', 1));
/**/
select *
from books
where author like '%唐家三少%';
/**/
select distinct book_type
from books;
/**/
SELECT title, author, peopleNum
FROM books
WHERE book_type = '文化'
ORDER BY peopleNum DESC
LIMIT 10;
/**/
SELECT *
FROM books
WHERE book_type = '金庸'
ORDER BY peopleNum DESC;
/**/
CREATE TABLE books1(SELECT DISTINCT b1.title,
b1.url,
b1.pic_url,
b1.pub,
b1.book_desc,
b1.book_type,
b1.author,
MAX(b1.bookScore),
MAX(b1.peopleNum)
FROM books b1
GROUP BY b1.url, b1.book_type);
/**/
drop table books1;