Hadoop 搭建高可用完全分布式集群
部署规划
|
主机
|
用途
|
IP
|
|
rm01.hadoop.com
|
ResourceManager01
|
192.168.137.11
|
|
nn01.hadoop.com
|
NameNode01
、
DFSZKFailoverController
|
192.168.137.12
|
|
rm02.hadoop.com
(backup resourcemanager)
|
ResourceManager02
|
192.168.137.13
|
|
nn02.hadoop.com
(backup namenode)
|
NameNode02
、
DFSZKFailoverController
|
192.168.137.14
|
|
dn01.hadoop.com
|
Dat
a
Node
、
NodeManager
、
QuorumPeerMain
、
JournalNode
|
192.168.137.21
|
|
dn02.hadoop.com
|
Dat
a
Node
、
NodeManager
、
QuorumPeerMain
、
JournalNode
|
192.168.137.22
|
|
dn03.hadoop.com
|
Dat
a
Node
、
NodeManager
、
QuorumPeerMain
、
JournalNode
|
192.168.137.23
|
[hadoop@dn01 ~]$ tar -zxf /nfs_share/software/zookeeper-3.4.11.tar.gz -C ~
[hadoop@dn01 ~]$ vi .bashrc
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.11
export PATH=$PATH:/home/hadoop/zookeeper-3.4.11/bin
[hadoop@dn01 ~]$ source .bashrc
[hadoop@dn01 ~]$ cd zookeeper-3.4.11/conf
[hadoop@dn01 conf]$ mv zoo_sample.cfg zoo.cfg
[hadoop@dn01 conf]$ vi zoo.cfg
dataLogDir=/home/hadoop/zookeeper-3.4.11/log
dataDir=/home/hadoop/zookeeper-3.4.11/data
server.1=192.168.137.21:2888:3888
server.2=192.168.137.22:2888:3888
server.3=192.168.137.23:2888:3888
[hadoop@dn01 conf]$ cd ..
[hadoop@dn01 zookeeper-3.4.11]$ mkdir data && mkdir log && cd data && echo "1">>myid
[hadoop@dn01 zookeeper-3.4.11]$ cd
[hadoop@dn01 ~]$ scp -r zookeeper-3.4.11 dn02.hadoop.com:/home/hadoop
[hadoop@dn01 ~]$ scp -r zookeeper-3.4.11 dn03.hadoop.com:/home/hadoop
[hadoop@dn01 ~]$ ssh [email protected] 'cd /home/hadoop/zookeeper-3.4.11/data && echo "2">myid'
[hadoop@dn01 ~]$ ssh [email protected] 'cd /home/hadoop/zookeeper-3.4.11/data && echo "3">myid'
[hadoop@dn01 ~]$ zkServer.sh start
[hadoop@dn02 ~]$ zkServer.sh start
[hadoop@dn03 ~]$ zkServer.sh start
[hadoop@dn01 ~]$ zkServer.sh status
[hadoop@dn02 ~]$ zkServer.sh status
[hadoop@dn03 ~]$ zkServer.sh status
[hadoop@dn01 ~]$ cd hadoop-2.9.0 && mkdir journal
[hadoop@dn02 ~]$ cd hadoop-2.9.0 && mkdir journal
[hadoop@dn03 ~]$ cd hadoop-2.9.0 && mkdir journal
[hadoop@nn01 ~]$ cd hadoop-2.9.0/etc/hadoop/
[hadoop@nn01 hadoop]$ vi core-site.xml
|
|
[hadoop@nn01 hadoop]$ vi hdfs-site.xml
|
|
[hadoop@nn01 hadoop]$ vi
mapred
-site.xml
|
|
[hadoop@nn01 hadoop]$ vi
yarn-site.xml
|
|
[hadoop@nn01 hadoop]$ vi
slaves
|
dn01.hadoop.com
dn02.hadoop.com
dn03.hadoop.com
|
[hadoop@nn01 ~]$ hdfs zkfc -formatZK
启动journalnode节点用于namenode主备数据同步
[hadoop@dn01 ~]$ hadoop-daemon.sh start journalnode
[hadoop@dn02 ~]$ hadoop-daemon.sh start journalnode
[hadoop@dn03 ~]$ hadoop-daemon.sh start journalnode
启动主namenode
[hadoop@nn01 ~]$ hdfs namenode -format -clusterId c1
[hadoop@nn01 ~]$ hadoop-daemon.sh start namenode
启动备用namenode
[hadoop@nn02 ~]$ hdfs namenode -bootstrapStandby
[hadoop@nn02 ~]$ hadoop-daemon.sh start namenode
启动namenode故障转移程序
[hadoop@nn01 ~]$ hadoop-daemon.sh start zkfc
[hadoop@nn02 ~]$ hadoop-daemon.sh start zkfc
启动datanode
[hadoop@dn01 ~]$ hadoop-daemon.sh start datanode
[hadoop@dn02 ~]$ hadoop-daemon.sh start datanode
[hadoop@dn03 ~]$ hadoop-daemon.sh start datanode
启动主resoucemanager
[hadoop@rm01 ~]$ start-yarn.sh
启动备用resoucemanager
[hadoop@rm02 ~]$ yarn-daemon.sh start resourcemanager
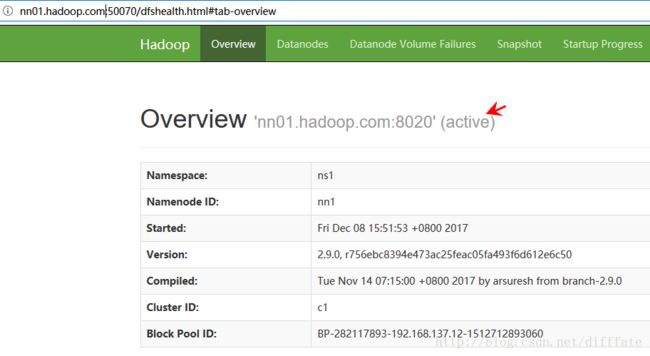
http://nn01.hadoop.com:50070/dfshealth.html#tab-overview
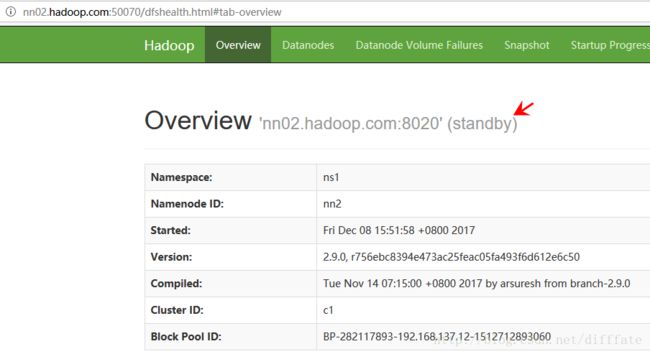
http://nn02.hadoop.com:50070/dfshealth.html#tab-overview
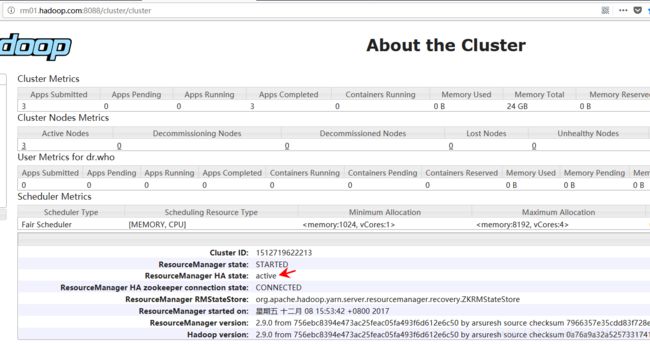
http://rm01.hadoop.com:8088/cluster/cluster
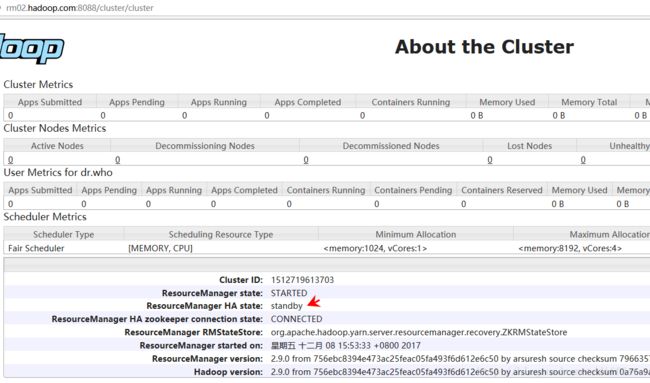
http://rm02.hadoop.com:8088/cluster/cluster
HDFS HA 检验实验
[hadoop@nn01 ~]$ jps
2352 DFSZKFailoverController
2188 NameNode
3105 Jps
执行命令
[hadoop@nn01 ~]$ kill -9 2188
刷新页面,看到
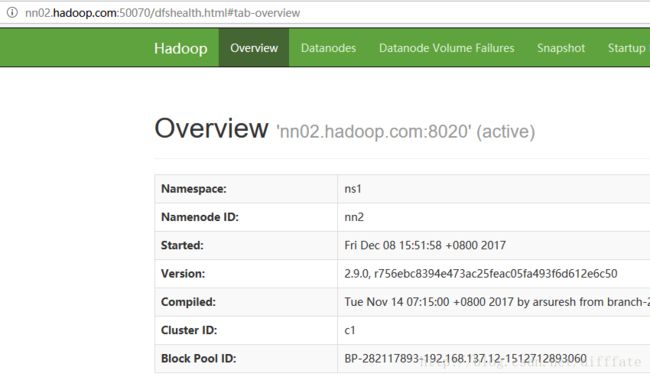
说明切换成功。
ResourceManager HA 检验实验
[hadoop@rm01 ~]$ jps
1599 ResourceManager
1927 Jps
启动wordcount程序
kill掉主ResourceManager进程
[hadoop@rm01 ~]$ kill -9 1599
看控制台输出,可以看到备的ResourceManager被启用
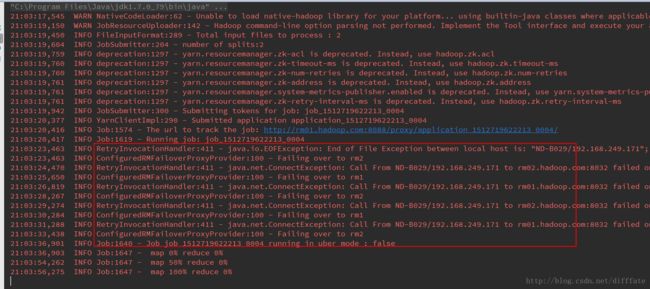
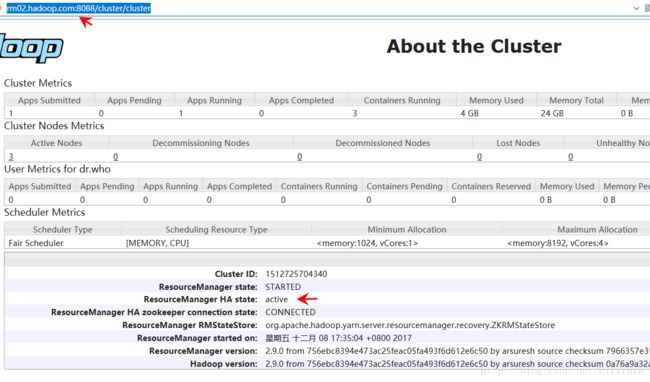
说明切换成功。