目标检测算法理解:从R-CNN到Mask R-CNN
因为工作了以后时间比较琐碎,所以更多的时候使用onenote记录知识点,但是对于一些算法层面的东西,个人的理解毕竟是有局限的。我一直做的都是图像分类方向,最近开始接触了目标检测,也看了一些大牛的论文,虽然网上已经有很多相关的算法讲解,但是每个人对同一个问题的理解都不太一样,本文主要结合自己的理解做一下记录,也欢迎大家批评指正~
在讲解object detection算法之前,我们需要明白图像处理领域的几个任务的区别,比如image classification、semantic segmention、instance segmention。image classification是对整个图像做识别,判断其属于哪一类,比如名人识别。object detection是检测图像中有什么,如果有的话会框出所有该对象所在的子区域,值得一提的是,这里的对象可以是多类,比如一副图中同时包含猫、狗、鸭等对象,一个目标检测算法可以分别找到所有这些对象。semantic segmention是不考虑图像中的目标实体,将每个像素划分到不同的类别。instance segmention不仅要检测出对象,还要对对象按照其真实边缘进行精确的分割。
R-CNN
R-CNN的全称是Region-Based Convolutional Networks,它是一种比较符合常规思路的目标检测算法。从字面意思就可以看出,卷积网络的输入是图像的某个子区域,而不是整个图像。传统的SIFT和HOG浅层特征并不能很好地表征图像中的模式,作者采用了深层CNN网络来提取图像中的判别信息。下面按照模型定义->模型训练->模型测试->postprocessing的思路讲解这个算法。
R-CNN网络结构
R-CNN网络结构主要包含两大部分,CNN网络和SVM分类算法,前者用于提特征,将单个候选区域转换成一维的特征向量,后者包含了多个svm分类器,分类器的个数与目标的类别数相同,具体的网络结构如下,

数据准备和模型训练
object detection任务也属于有监督学习算法,每一个图像对应着标签,这里的标签包括图片中对象的bounding box和该box中对象的类别。对于每一幅图像,文章采用了selective search策略提取出2000个候选区域,这里不妨把候选区域称作子图像块。整个模型的训练是分阶段进行的,先训练前面的CNN网络,再训练后面的SVM分类器,下面分开介绍这两个阶段。
对于CNN网络来说,在训练该模型时,它的标签包含了两类图像块,positive样本和negative样本,positive指IoU值大于0.5的图像块,negative指Iou值小于0.5的图像块(IoU的全称是intersection-over-union,表示图像块和对应的bounding box之间的交集区域面积与并集区域面积的比值,显然,当图像块和bounding box重叠时,IoU取最大值1)。因为CNN网络的输入图像尺寸是固定的,所以为了更够正常地输入到网络中,需要先将这些图像块缩放到规定的尺寸。
通常,与image classification任务不同,目标检测的训练图像数量通常都相对较少,所以训练CNN网络的时候,并不能从头开始训练,而是基于已经训练好的的CNN网络,对其输出层参数进行微调,这种思想也可以看作是“迁移学习”。这里顺便回答一下为什么不直接用CNN网络的提取出的特征,而是要进行finetune阶段呢?因为一些经典的CNN网络结构,比如Alexnet和Resnet等模型,它们都是基于Imagenet数据集进行训练的,也就是说它们在挖掘imagenet数据集中的模式的效果比较好,但是不同数据集的分布是有差异的,原生的Alexnet网络并不能很好地提取出新的目标检测数据集中的规律。
对于SVMs来说,因为SVM在训练样本数比较少时也有很好的分类效果,所以它对训练样本的构造比较“挑剔”,只有当子图像块将整个bounding box框住的时候才会被作为positive样本,只有当子图像块的Iou值小于0.3才会被作为negative样本。其他的子图像块全部忽略。显然,这些子图像块可能包含了不同的目标,比如有的包含飞机,有的包含人物,还有的包含电视监视器,那么就相当于是一个多分类问题, 而SVM实现多分类是通过将其分解成多个二分类问题解决的。比如在训练第一个二分类模型,判断是否为飞机时,可以选择包含飞机的图像块作为正例,其它的图像块作为反例。
到这里,还需要解释两个问题,一是为什么CNN网络和SVM的训练样例的选择标准会不同呢?二是为什么作者不直接使用CNN的分类器输出作为预测标签,而要额外引入SVM呢?对于第一个问题,因为在训练CNN网络时,为了避免网络模型over fitting,需要使用更多的训练样本,于是就必然要用到可信度较低的positive样本(Iou值介于0.5和1之间)。对于第二个问题,因为CNN网络的训练样本鱼龙混杂,所以并不能实现精确定位出目标区域,所以仅作为特征提取,而额外采用SVM来判别图像块的类别。
模型测试
在模型测试阶段,输入的是单幅图像,然后采用selective search方法生成2000个候选区域,对于每一个候选区域,先使用CNN网络模型提取其一维特征向量,然后使用SVMs输出该特征向量属于不同类别的scores,预测出该特征向量对应的类别标签。当所有2000个候选区域均打分完成时,对于每一个类别,使用贪婪的non-maximum supression算法舍弃掉某些区域,关于这个算法,原文中是这么说的"rejects a region if it has an intersection-over-union
(IoU) overlap with a higher scoring selected region larger than a learned threshold"。可以这么理解,比如当前类别有五个图像块,编号分别为A、B、C、D、E,先将这些图像块按照score由高到低排列,假设排序后为B、A、D、E、C,先保留得分最高的图像块(或者称作候选区域),也即B,然后分别计算A、D、E、C与B之间的IoU值,如果IoU值大于设定的threshold,就舍弃该图像块,比如A和B之间的IoU值为0.9,大于设定的threshold=0.7,那么就舍弃图像块A,现在就剩下D、E、C需要取舍了,思路同上,也是要先保留三者中Iou最大的图像块,对于每一类都这样进行下去,就可以得到图像中所有类别的对象的子区域。
postprocessing
在上一步得到所有候选区域中可信度较高的图像块后,我们通常的想法是到这里已经处理完了,但作者在文章最后阐述了Bounding-Box Regression。具体来说,它是用于对图像块的位置进行微调用的,使其更加接近真实的boundingbox,记P=( P x P_{x} Px, P y P_{y} Py, P w P_{w} Pw, P h P_{h} Ph)表示当前候选的图像块,G=( G x G_{x} Gx, G y G_{y} Gy, G w G_{w} Gw, G h G_{h} Gh)表示真实的boundingbox位置,在训练该回归模型的时候,分别使用线性回归模型对G中的四个参数建模,该模型的输入是输入图像块在第5个pooling层的特征表示,通过定义带二范数约束的均方误差损失函数,可以求解出回归模型的参数。回归模型的优化过程比较简单,在这里就不详细展开讲了,具体的可以参见原文中的7.3部分。
Fast R-CNN
在2015年,作者提出了新的目标检测模型Fast R-CNN,它是R-CNN的改进版本。那么,为什么要对R-CNN算法进行改进呢,因为它存在如下3大缺点:
(1)训练过程是多阶段的,先后分别训练了ConvNet、SVM和bounding-box regressors;
(2)训练过程耗时较长且需要较大的存储空间;
(3)在测试阶段进行目标检测很慢,因为要分别对每一个候选区域进行前向传播。
Fast R-CNN网络结构
Fast R-CNN使用了单阶段的多任务网络模型进行目标检测,该模型的输入为整个图像和图像中的所有目标区域。从信号流的前像传播的角度来看,从输入到输出经过了下面几个阶段:
(1)该网络先采用了多个卷积和池化操作提取出高阶抽象特征,将输入图像转换成了一个conv feature map。然后,因为该feature map和输入图像的尺寸不一样,需要将输入图像中的目标区域投影到该feature map上去;
(2)为了使所有投影后的图像块能和后面的fully connected layer神经元数目保持一致,需要将这些大小不一的图像块变换到相同尺寸,这里便用到了RoI pooling layer,具体来说,比如一个大小为 h ∗ w h*w h∗w的图像块,可以把它划分成 H ∗ W H*W H∗W的网格,然后对每个小格子中的所有像素进行max-pooling操作,那么不管投影后的图像块的大小如何,经过RoI pooling层后都会被转化为相同的尺寸了;
(3)池化后的二维特征经过多个全连接层,转化为一维的特征向量,即RoI feature vector;
(4)基于上面得到的feature vector,引出两个分支,分别为softmax分类器和bbox regressor。softmax分类器用于输出候选窗属于K个类别对象的概率,bbox regressor用于输出对应的K个类别对象的位置,该位置分别用4个实数表示。
整个模型的架构如下图,

模型训练
该网络结构是改进版的CNN模型,也可以使用预训练的imagenet网络来初始化模型中的参数,只不过要用上图中的阴影部分的子网络替换imagenet网络中最后一个池化层及其后面的子网络。在模型参数finetune阶段,只需要对上图阴影部分子网络中的参数进行优化。作者在文章中提出了一种更加高效的训练算法,通过使用分层次采样来更好地利用特征共享。具体来说,比如要从N=2个图像中采样出R=128个候选区域,那么由于同一图像中的所有候选区域在forward propagation和backward propagation过程中共享计算和存储,因此比对128幅不同图像采样快了64倍(注:R-CNN算法就是对128幅不同图像采样的)。
由于Fast R-CNN模型不仅要预测类别标签还要确定对象的位置,这便是典型的Multi-task问题,那么损失函数也应该是这两个子任务的损失之和,损失函数表达式如下,

其中, L c l s ( p , u ) = − l o g p u L_{cls}(p,u)=-logp_{u} Lcls(p,u)=−logpu表示softmax输出层的损失,衡量的是预测值p和真实类别标签u之间的差异性。 L l o c ( t u , v ) L_{loc}(t^{u},v) Lloc(tu,v)表示bbox regressor输出层的损失。u表示类别标签,v表示真实的位置坐标 v x , v y , v w , v h v_{x},v_{y},v_{w},v_{h} vx,vy,vw,vh, t u t^{u} tu表示类别u对应的预测位置坐标。 [ u > = 1 ] [u>=1] [u>=1]是一个符号函数,当括号内为真时结果为1,为假时结果为0,它用于过滤掉背景类别的损失,因为只有背景类别的u值为0。参数 λ \lambda λ用于对这两个任务的损失进行折中。
尽管现在的一些深度学习框架,基本都带有自动求微分功能,但是这里引入了RoI池化层这一新概念,感觉还是有必要明白bp算法在这一层是如何实现的。RoI pooling层的图像化效果如下图,

假设输入x是大小为6×6的图像块,池化后的图像块记作y,且其标准尺寸设定为2×2,那么就需要将输入网格拆分成4份,如图中红色线条所示,然后对每一个3×3的子图像块取maxpooling操作,就可以得到池化后的值了,图中A、B、C和D分别表示四个子图像块中元素的最大值。损失函数关于输入的偏导数公式如下,

其中,r表示候选区域的索引,j表示池化后图像块y中的元素索引, i ∗ ( r , j ) i^{*}(r,j) i∗(r,j)表示y中第j个元素对应到图像块x中的索引,比如y中的元素A,对应到x中即是 x 2 , 1 x_{2,1} x2,1,所以 ∂ ( L ) x 2 , 1 = ∂ ( L ) y 1 , 1 , ∂ ( L ) x 1 , 5 = ∂ ( L ) y 1 , 2 , ∂ ( L ) x 6 , 3 = ∂ ( L ) y 2 , 1 , ∂ ( L ) x 5 , 5 = ∂ ( L ) y 2 , 2 \frac{\partial(L)}{x_{2,1}}=\frac{\partial(L)}{y_{1,1}},\frac{\partial(L)}{x_{1,5}}=\frac{\partial(L)}{y_{1,2}},\frac{\partial(L)}{x_{6,3}}=\frac{\partial(L)}{y_{2,1}},\frac{\partial(L)}{x_{5,5}}=\frac{\partial(L)}{y_{2,2}} x2,1∂(L)=y1,1∂(L),x1,5∂(L)=y1,2∂(L),x6,3∂(L)=y2,1∂(L),x5,5∂(L)=y2,2∂(L),L关于x中其它元素的偏导数均为0。
Faster R-CNN
在2016年,微软研究院的学者们提出了新的目标检测算法,Faster R-CNN,顾名思义,它是Fast R-CNN模型的改进版,因为Fast-RCNN使用了“selective search”策略生成初始候选区域,具体来说,该策略基于人工的浅层特征,采用贪婪的思想合并超像素,从而得到一些候选区域,这种方法的时间复杂度比较高,在单cpu上处理一幅图像耗时2秒。Faster R-CNN之所以快,就是因为引入了“Region Proposal Network”来自动生成候选区域,计算复杂度明显降低。
Faster R-CNN网络结构
Faster R-CNN网络模型包括了两个基本网络,RPN(Region Proposal Networks)网络和Fast R-CNN网络,前者负责生成候选区域,后者负责目标定位和识别。Faster R-CNN网络模型的结构图如下,
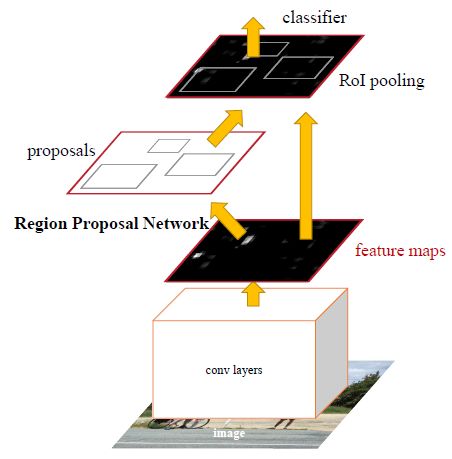
其中,RPN网络包括conv layers和proposals部分,Fast R-CNN网络包括conv layers、RoI pooling和classifier部分。从网络结构上来看,Faster R-CNN和Fast R-CNN结构非常相似,区别在于,前者从feature maps中自动提取出目标候选区域,并把生成的目标区域映射到feature maps上面,而后者是从初始输入图像image中提取候选区域,然后将其直接映射到feature maps上面,下面介绍RPN网络是如何生成候选区域,并传递给Fast R-CNN网络的。
RPN网络
RPN网络是一个全卷积网络(fully convolutional network),它可以同时预测出输入图像的每一个像素的object bounds和objectness scores,'object bounds’表征的是以当前像素为中心的一个目标区域,‘objectness scores’表征的是当前目标区域属于每一个类别的概率。这里顺便提及一下什么叫全卷积网络,通常的卷积网络是对输入一幅图像,输出一个class标签,主要用于图像分类任务中,而全卷积网络的输入图像和输出图像的尺寸是相同的,也就是说,输出图像中的像素和输入图像中的像素存在一一映射关系,主要用于图像分割(semantic segmention)任务中。论文中的网络结构图比较抽象,这里就借用另一篇博客上的一幅图进行阐述(参考资料中有引用),

在具体介绍RPN网络的前向传播过程之前,需要解释一个新的概念,什么是’anchor’?论文中针对anchor的概念给出了下图,
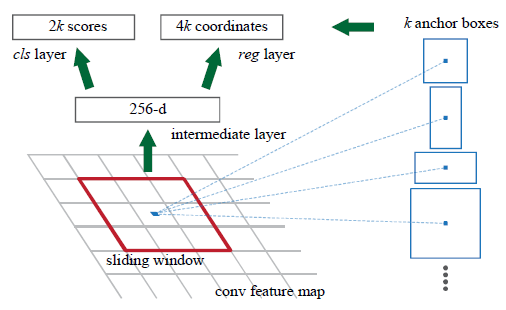
这里的anchors是一些reference boxes,每个像素点都有若干个anchors,比如图中红色正方形中心的像素,如果选择3种不同尺度和3种长宽比,就会得到k=9个anchors,所以对于大小为W×H的feature map,总共有WHk个anchors。但是,这里要强调的一点是,这些anchors是人为假定的,RPN模型预测出的k个候选区域分别是关于这k个参考boxes的函数,而这些anchors并不作为RPN子网络的输入图像块。 可能大家会想,既然不作为输入,为什么还要引入anchors这一概念呢?因为你想生成候选区域,至少得告诉设计的网络模型要生成多少个候选区域吧,这里还有一点需要说明一下,从损失函数的角度来讲,RPN模型的目的就是对于每一个像素的每一个anchor,使预测出的候选区域尽量逼近该anchor对应的ground-truth box,所以实际上每个像素的anchors可以随意指定,只不过按照多尺度、多长宽比指定anchors,可以覆盖到当前像素的更多可能区域。
记输入图像的尺寸为P×Q,需要先将其缩放成大小为M×N的图像,顺便提及一下,这里进行缩放只是为了方便进行基于batch的参数更新,实际上,如果只考虑单幅图像的forward propagation的话,任意尺寸的输入图像都是可行的,因为后面的RoI pooling操作会将其转换成相同的尺寸,不影响整个网络最终的输出。
step1:获得输入图的feature maps。图中的“13个conv层、13个relu层、4个pooling层”是直接从imagenet分类网络迁移得到的,比如VGG-16、inception v3/v4等,在经过这30层的转换之后,就得到了输入图像的高阶抽象特征图Feature Maps, 若采用ZF模型,这里的feature map有256个,若采用VGG模型,这里的feature map有512个,下面就以ZF模型为例进行说明,也即Feature Map的尺寸为A×B×256;
step2:3×3卷积操作。使用大小为(256, 3, 3, 256)的滤波器对输入的256feature maps做卷积,滤波器的各个维度分别表示输入特征图个数、滤波器高度、滤波器宽度和输出特征图个数,因此卷积后的矩阵大小仍然为A×B×256。这里还需要解释两个问题,一是为什么要进行卷积操作?二是为什么使用3×3的滤波器?对于问题一,因为RPN网络要基于feature map的每个像素点预测出对应的候选区域,也就是图中的proposal,那么必然要求softmax分类器的单个输入像素点要包含其领域的信息,所以要进行卷积操作。对于问题二,因为论文中采用的是n=3,也就是以当前像素为中心,通过输入其3×3的邻域窗包含的信息,来预测出9个anchors的位置,实际上采用更大的窗比如n=228也是可以的,关于预测过程会在下面的损失函数部分细讲;
step3:1×1卷积操作。对于多通道图像来说,1×1卷积操作用于分别将每个元素的各个子带值进行加权求和,减少feature map的个数,图中有两个1×1卷积操作,上面一个用于做分类,生成每个anchor box属于foreground/background的概率,显然这是一个2分类问题,每个像素有9个anchors,所以卷积后得到大小为A×B×18的矩阵。下面一个1×1卷积用于生成每个predict box和anchor box之间的偏移,这是一个regression问题,偏移包含了(x,y,w,h)四个参数,所以卷积后得到大小为A×B×36的矩阵。关于随后的reshape操作,这个图是用caffe框架生成的,使用reshape操作为了符合caffe中的语法,也即softmax函数的输入格式要求;
step4:Softmax操作。将每个像素的预测概率进行归一化,使各个类别的概率之和为1;
step5:Proposals过滤。将RPL网络生成的候选区域映射到原始输入图像中,过滤掉超出边界的候选区域。
经过了上面4个步骤后,RPN网络便检测出了所有的候选区域,完成了它的使命。
准备训练数据
模型训练的前提是数据准备,在训练RPNs网络的时候,将像素的每一个anchor看作一个二分类问题(foreground or background),这里的foreground代表所有类别的目标对象,background代表非目标对象的背景区域。由于Fast R-CNN网络的数据准备上面介绍过了,这里只介绍RPL网络的训练数据。对于大小为A×B×256的feature maps,每个像素点有9个anchors,那么单幅图像anchor的总数目为A×B×9。为了得到positive samples和negative samples,算法会先计算所有anchors和对应的ground-truth box之间的IoU值,然后将这些IoU值按照从大到小的顺序排列,取IoU值较高的一些anchors最为正例,取IoU值低于0.3的anchors作为反例。在模型训练过程中,mini-batch是从单幅图像中的正反样例anchors中随机采样256个anchors得到的,使每个mini-batch中的正负样本尽量满足1:1的比例。
RPN网络的loss function
与Fast R-CNN网络模型相似,RPN网络也是一个mul-task模型,所以也要定义mul-task loss,RPN网络的损失函数的数学表达式如下,

其中,i表示mini-batch中anchor的索引, p i p_{i} pi表示anchor i属于foreground(object)的预测概率, p i ∗ p_{i}^{*} pi∗表示ground truth标签(若当前anchor为正例,其值为1,否则值为0), t i t_{i} ti是预测出的bounding box的4个参数化坐标构成的向量, t i ∗ t_{i}^{*} ti∗是和positive samples相关的ground truth box。式子的前一项表示classification loss,衡量的是预测输入anchor为foreground/background的准确性。后一项表示regression loss,它只对positive anchors( p i ∗ p_{i}^{*} pi∗)的预测坐标进行约束。
对于bounding box regression来说,论文中采用了4个坐标的参数化表示,公式如下,
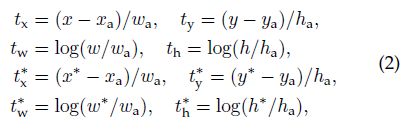
其中,x,y,w,h表示box的中心点坐标和它的height、width,变量 x , x a , x ∗ x, x_{a},x^{*} x,xa,x∗分别指代predicted box、anchor box和ground-truth box。而且,从公式2可以看出,regression模型的目标就是根据输入的anchor box,预测出与之相邻的ground-truth box。
参数初始化和模型训练
Faster R-CNN模型前面的30个卷积池化层使用imagenet预训练的模型进行参数初始化,新增的RPN子网络使用N(0, 0.01)的高斯分布进行权值参数初始化。在优化整个Faster R-CNN网络时,采用的是’Alternating training’的策略。具体来说,先训练RPN网络,然后使用生成的候选区域训练Fast R-CNN模型,对于ZF模型,就是训练所有层的参数,那么30个卷积池化层的参数就会被更新了,然后使用更新后的参数初始化RPN网络,再训练RPN网络,依此过程迭代下去,就会最优化整个Faster R-CNN网络的所有参数。而且,从整个迭代过程可以看出,两个子网络进行了卷积层特征的共享。
Mask R-CNN
Mask R-CNN是Kaiming He在2017年新提出的模型,它是在Faster R-CNN模型的基础上,增加了一个用于预测目标掩码的分支,这里所谓的“掩码”就是识别指定图像块中的foreground和background,显然这是一个二分类问题。Mask R-CNN模型主要用于解决"instance segmentation"的任务,找到组成特定类别物体的所有像素。我们可以想象到,实物分割是图像处理领域的一个非常难的任务,因为它结合了目标检测和语义分割,整个网络框架如下图,

网络结构
在Faster R-CNN模型中,在得到多个feature maps和候选区域后,会对所有候选区域进行了RoI pooling操作和多层非线性变换,然后基于得到的特征进行classification和regression。就模型本身的网络结构而言,Mask R-CNN仅仅在池化操作后增加了第三个分支,即实物分割子网络,其他的部分和Faster R-CNN是完全相同的。上图中的网络结构画的不是很详细,这里做一些补充说明,
(1)最左侧是输入图像,只包含了人物这一类别,当然了,实际应用中也可以包含多个不同的的实物类别;
(2)中间的大立方体表示feature maps,它是由输入图像经过多个卷积池化操作得到的,只不过上图为了简化没有画而已。 feature maps图上的网格对应RPN网络生成的候选区域,大家在这里可能比较困惑,该网络所表示的候选区域为什么和输入图像中的ground-truth box,以及输出图像的predict box尺寸相同呢?这是因为当前正在处理的候选区域已经被映射到输入图像上了,对应到了输入图像中的坐标表示,而其它的3个候选区域未被映射,所以看上去是很小的区域块;
(3)通过对这些候选区域进行RoIAlign操作,得到新的feature maps,如图中的第一个小立方体所示,基于当前特征图,可以进行classification和regression任务,也就是图中的上面一个分支"class/box";
(4)对上图中的第一个立方体进行多层卷积操作,得到候选区域对应的二分类图像。
在论文中,作者将整个网络划分成了两大部分,多层卷积的"backbone"架构和网络"head",前者用于对输入图像进行特征提取,后者用于bounding-box识别(classification、regression)和生成二值化图块块。从上图可以观察到,mask prediction分支是一个全卷积网络,为什么这么说呢?因为输入为RoI对应原图中的区域,输出为该区域对应的二分类图像,显然输出图像和输入图像的尺寸相同,且像素之间存在一一映射关系。"head"架构的结构图如下,

RoIAlign
RoIAlign是文章中的一个亮点所在,对于提高模型在instance segmentation任务上的效果具有重要意义。笔者在看论文的时候对这个操作很困惑,一直认为"Align"操作前后的图像的尺寸相同,后来才明白这里的"Align"指的是图像的像素之间存在一一映射关系。在Faster R-CNN网络中,会使用RoI pooling操作从候选区域中提取小的feature map,但是事实上这个过程经历了以下3个步骤:
(1)RPN网络中的regression分支预测出候选区域的坐标,由RPN网络的损失函数可以看出,预测坐标的值是相对于输入图像尺寸而言的,而且预测坐标是浮点值,所以要进行取整操作才能得到候选区域,文章中用的是"quantize",其实就是取整运算;
(2)将RoI划分成一些容器(bins),然后分别对每一个容器中的像素进行max pooling操作,但是在划分容器的时候,比如将RoI划分成7×7的大网格时,如果RoI的长宽不是7的倍数的话,就会存在四舍五入的运算,所以这里也有量化操作。
那么问题来了,上面的两个量化对模型有什么影响呢?对于分类和回归任务而言,自然是没有什么影响的,但是对于segmentation任务而言,由于输出图像中的像素是对输入图像分割的结果,所以像素之间要存在一一映射关系,不能有上面的取整运算。我们设想一下,假设在输出mask图之前进行了取整操作,那么输出图中的某些像素必然不能对应到真实的groundtruth了,那么肯定会影响图像分割的准确性。
为了避免量化带来的像素misalignments问题,作者在文章中提出了RoIAlign layer的概念,它使用了双线性插值来计算输入特征在每一个容器中的准确对应值。
Mask R-CNN模型的损失函数
Mask R-CNN也采用了two-stage的步骤进行目标检测,在第一阶段,采用RPN网络生成候选区域。在第二阶段,通过3路分支完成classification、box offset regression和binary mask prediction三大任务。
与Faster R-CNN模型类似,这里定义多任务损失函数为 L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask,分类损失 L c l s L_{cls} Lcls、bounding box损失 L b o x L_{box} Lbox同Faster R-CNN中的定义相同,binary mask分支输出维度为 K m 2 Km^{2} Km2,K表示总的实物类别的个数,m×m表示当前候选区域对应的ground-truth box的尺寸。这种方式能同时生成每一个类别对应的二值化mask,所以mask分支的输出包含了K个二分类任务,每个二分类采用的是sigmoid激活函数, L m a s k L_{mask} Lmask分支的损失函数就是当前区域的label的one-hot表示和K个sigmoid输出之间的cross-entropy损失,为什么说是one-hot表示呢?因为当前anchor只能属于单一类别。不得不说,这里确实很巧妙,通常的全卷积网络进行semantic segmentation时,都是对每一个像素采用softmax函数预测其可能的类别,然后采用multinominalcross-entropy损失函数进行模型优化,而本文引入了多个分支,将分类任务交给classification网络分支,mask分支只负责生成二分类图像,从而有效地避免了classes之间的竞争。
目标检测方向的论文更新比较快,最近看到一个比较好的总结图,这里也顺便贴一下,

参考文献:
Ross Girshick, Region-Based Convolutional Networks for Accurate Object Detection and Segmentation.
Ross Girshick, Fast R-CNN.
Shaoqing Ren, Kaiming He. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.
Kaiming He. Mask R-CNN.
http://blog.csdn.net/zy1034092330/article/details/62044941(引用了这篇文章中的一幅图)