深度学习算法效果提升-网络结构
文章目录
- 1. 前言
- 2. 现有的优秀网络结构
- 2.1 “云”上模型
- 2.1.1 Inception v1(GoogLeNet)
- 2.1.2 Inception v2
- 2.1.3 Inception v3
- 2.1.4 Inception v4
- 2.1.4 Inception_resnet_v1
- 2.1.5 ResneXT
- 2.2 “端”上模型
- 2.2.1 squeezenet
- 2.2.2 mobilenet_v1
- 2.1.3 shufflenet
- 2.1.4 mobilenet_v2
- 3. 网络结构调整
- 4. 参考资料
1. 前言
优化深度学习算法的效果可以从三个方面入手,数据+网络结构+损失函数。一般来说,外行改网络结构,内行改损失函数,公司层面收集数据。
在一般情况下,特别是手机端应用,直接拿个成熟的小网络进行迁移学习,如shufflenet、mobilenet等,是较为常见的做法。而且,由于一些开源框架提供了官方预训练的模型,只要自己的数据集和imagenet的数据类别出入不大,在其基础上做finetune效果往往也会很好。
对于服务器端应用,在算法开发阶段,我们通常会选择imagenet数据集上效果较好的预训练模型,比如resnet 101, inception_resnet_v2等,具体可以参见https://github.com/tensorflow/models/tree/master/research/slim中给出的对比数据。在工程部署阶段,可能会因为服务器的配置、网络延迟等因素的影响,模型的inference时间不满足产品定义的响应时间,此时便需要对网络结构做裁剪,也即修改当前网络模型的backbone,然后重新训练整个网络的参数。此时面临两种选择:一是将当前网络的backbone替换成小网络,比如替换成mobilenet;二是对大的网络做裁剪,比如resneXT,将其裁剪成小的网络,然后作为backbone,至于是Mobilenet好还是裁剪后的resneXT好呢,不同的网络结构提取的图像特征是不一样的,所以要基于具体的任务做完对比实验后才知道。
事实上,裁剪网络属于网络结构设计的范畴,这个范畴包含了两大子类别:一是“从无到有”,可以直接发网络结构方面的paper了;二是”从有到有“,站在巨人的肩膀上,包括了network prune、knowledge distillation。 前者需要很多的经验和技巧,往往都出自于Google、SenseTime等公司的牛人之手,可能大家看到这里会说,“不是已经有自动化的网络结构搜索了吗,比如nasnet等”,但是网络结构的自动化搜索同样门槛也很高,对于大多数深度学习从业者来说也是很少会去用的。因此,本篇先对一些已有网络结构中的精华点进行讲解,为有志于网络结构设计方面的同学找到一些inspiration,然后结合自己的思考,从工业应用的角度,介绍调整网络结构的常用策略。
2. 现有的优秀网络结构
不同网络结构的模型,它们的表征能力不一样,有些模型是为了提升精度,而有些兼顾了精确度和速度。从应用平台上来划分,可以分为”云“上模型和“端”上模型。一般来说,大的网络结构的模型,它的精确度较高,但是因为模型较厚重,所以只适合在服务器端部署。与此同时,小的网络结构的模型,设计这在设计之初考虑了速度和精度的折中,因此这类网络模型更适合手机端部署。
2.1 “云”上模型
说起部署在云端的模型,不得不从Inception网络Inception系列网络结构在网络设计领域是非常重要的,具有很好的借鉴意义。为什么这么说呢,因为在它之前,所有的网络为了提升Imagenet分类效果,都是考虑增加卷积层的个数。Inception系列都是在前一个版本的基础上进行速度和精度的优化,让我们开始欣赏网络设计人员的智慧吧。
2.1.1 Inception v1(GoogLeNet)
Motivation:
(1) 图像中的显著性区域有很大的差异性。比如猫狗识别,对于一条狗的图片,显著性区域则为狗的身体部分,可能图片中的狗颜色、品种、姿势、尺寸都不相同,所以差异性很大;
(2) 如果想学习图片中全局的信息,应该使用大的kernel,如果想学习图片中局部的信息,应该使用小的kernel;
(3) 网络越深,越容易过拟合,而且存在梯度消失问题;
(4) 减小计算量;
Solution:
网络往 "wider"方向发展而不是 “deeper”,一种解决办法是同一层使用多个尺寸的filter,模块结构如下,

为了减小模型的计算量,使用了1x1的卷积层进行降维,修改后的模块结构如下,
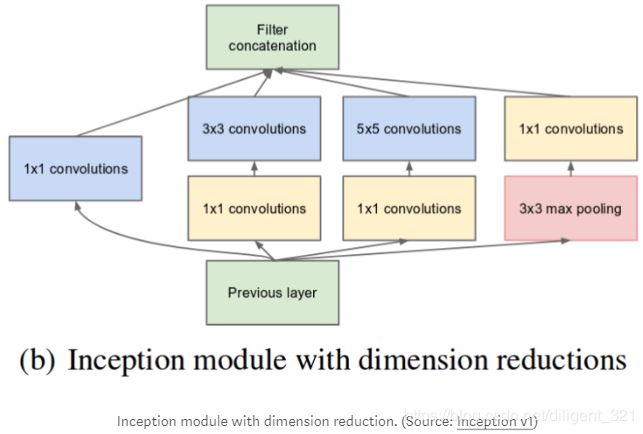
2.1.2 Inception v2
Motivation:
(1) 如果 1x1卷积使通道数减得太多,容易导致信息丢失;
(2) 对大的卷积kernel进行分解,节约计算量;
Solution:
将 5x5的卷积分解成两个级联的3x3卷积操作,当输入和输出通道数分别相同时,两种网络结构的参数量比值为25/(9x2)= 1.38,可以节约计算量,模块结构如下,

更进一步地,将 3x3的卷积分解成1x3卷积和3x1卷积的级联形式,两种网络结构的参数量比值为9/(3x2)= 1.5,也节约了计算量,模块结构如下,
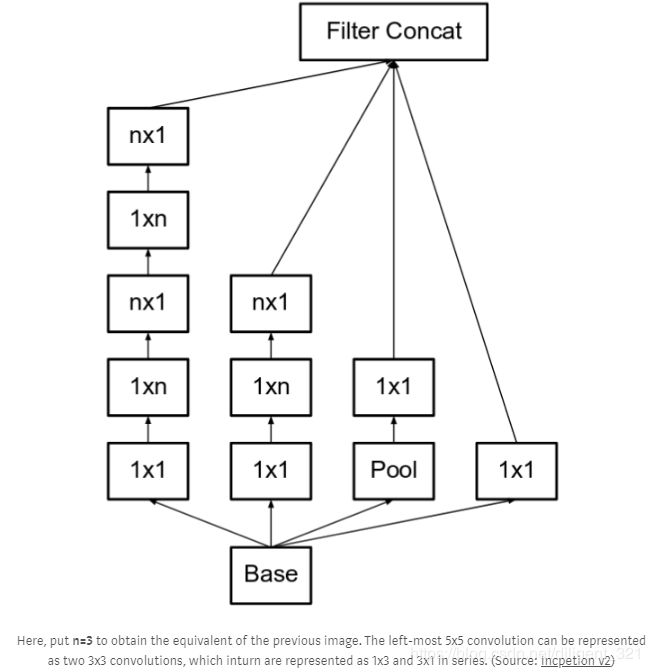
上图中的级联卷积层较多,容易对输入的通道数降维太多,导致过多的有用信息丢失,这被称为“ representational bottleneck”。为了缓解这一问题,作者将滤波器组(filter banks)设计的wider而不是deeper,模块结构如下,
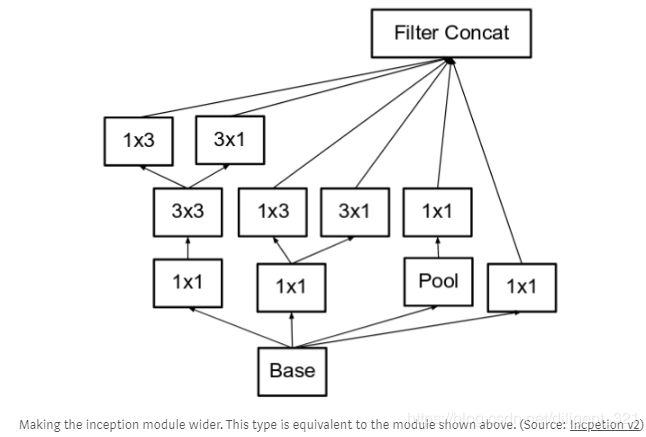
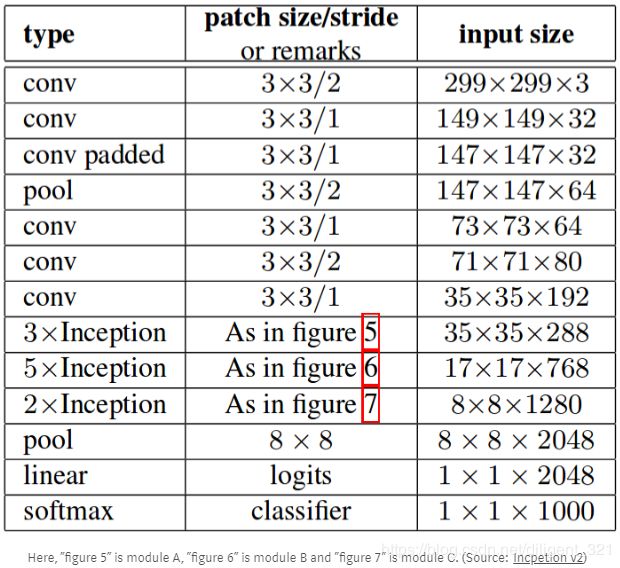
这三个图代表了不同类型的inception模块,这里分别记作A、B、C,Inception v2的网络结构主要是这三种模块的级联形式,层之间的具体连接形式如下表,
2.1.3 Inception v3
Motivation:
(1) 在不对Inception v2的module结构进行大改的前提下,尽可能地提升模型效果;
Solution:
(1) RMSProp优化器;
(2) BatchNorm层;
(3) Label Smoothing(正则化技术);
2.1.4 Inception v4
Motivation:
(1) 在设计Inception v3的过程中,作者考虑了是否能在DistBelief进行分布式训练,导致模型过于复杂,现在迁移到了tensorflow平台上,就可以做一个简单一致的网络设计;
Solution:
(1) 使用更多的inception模块来增强网络的表达能力,但是这里的Inception模块相比于v3中的更简单,所以整体上没有增加计算量;
(2) 设计了专用的“Reduction Blocks”,用于减小feature map的尺寸;
2.1.4 Inception_resnet_v1
Motivation:
(1) 借鉴何凯明大神的“residual connection”的思想,;
Solution:
(1) 对于每个inception模块,增加残差连接;
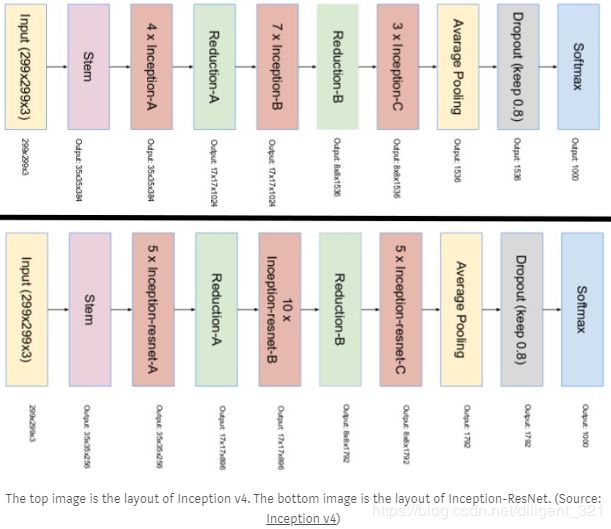
2.1.5 ResneXT
Motivation:
(1) 在不增加模型参数量的前提下,尽可能地提升模型的准确率;
(2) inception 系列网络中每个inception模块设计的较复杂,当应用在别的数据集上时,不容易修改网络结构。
Solution:
(1) ResneXT引入了“cardinality”的概念,可以理解成通路,每一条通路的结构完全相同,所以设计起来更加简单化。
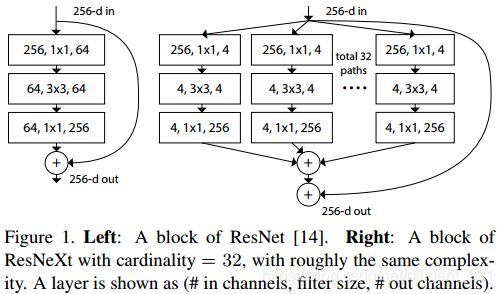
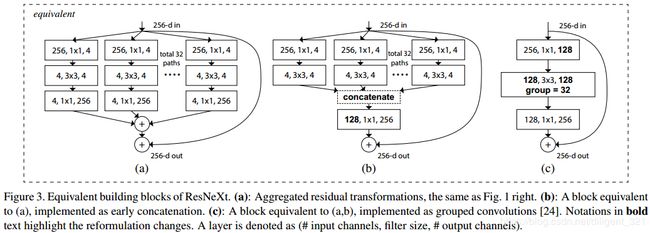
(2) 作者证明了下面的三种拓扑结构是完全等价的,意思是说模型在测试集的效果理论上是一样的,在论文中,为了工程上更容易实现,所有的实验结果采用了©结构。
2.2 “端”上模型
说起部署在移动端的模型,mobilenet是令人最印象深刻的网络结构了。各位读者可能注意到,inception和mobilenet都是谷歌家的呀,是的,笔者项目中部署到手机端的模型,用的最多的就是mobilenet系列了,效果确实可以,下面按照在imagenet测试集上的效果从低到高排序,分别解释当前可用且有效的轻量化模型。
2.2.1 squeezenet
Motivation:
(1) 在减少模型参数量的前提下,尽可能地提升模型的准确率。
Solution:
(1) 在网络结构中,尽量多使用1x1而不是3x3 的滤波器,因为前者是后者参数量的1/9;
(2) 为了进一步较少计算量,使用了论文中提到的“squeeze layer”, 减小3x3滤波器的输入通道数;
(3) 为了在参数量不变的情况下,尽可能地提升精度。作者认为卷积层的feature map尺寸越大,模型效果越好,于是就尽可能地把下采样层放到整个网络的后面。
squeezenet的整体网络结构类似于inception v1,网络结构的核心“Fire” module可以类比于inception v1的“Inception” module,“Fire” module的结构如下图,
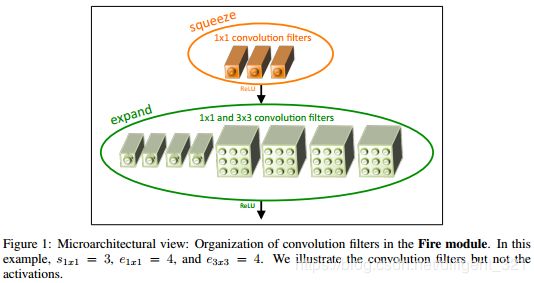
注:源代码使用的是caffe框架。
2.2.2 mobilenet_v1
Motivation:
(1) 在减少模型参数量的前提下,尽可能地提升模型的准确率;
Solution:
(1) 整个网络结构的核心模块是“Depthwise Separable Convolution”,它包含了两层,“depthwise convolutions” 和“pointwise convolutions”,前者分别对逐个通道进行卷积,获取空间域信息,后者对feature map做特征融合,这两层也使用了batchnorm和ReLU的策略,该核心模块的图形表示如下,

注:源代码使用的是tensorflow框架。
2.1.3 shufflenet
Motivation:
(1) 在减少模型参数量的前提下,尽可能地提升模型的准确率;
Solution:
(1) 本文提出的网络结构的主要layer类型是"group convolution"和“channel shuffle”,前者是Alexnet文章中首次提出来的,并被ResneX网络证明是有效的,后者是本文的创新点,”channel shuffle“能够使当前goup包含其他group的信息,从而实现信息的融合。虽然mobilenet_v1中的“pointwise convolution”也可以实现信息融合的目的,但是却引入了额外的参数量,“channel shuffle”的图形解释如下,
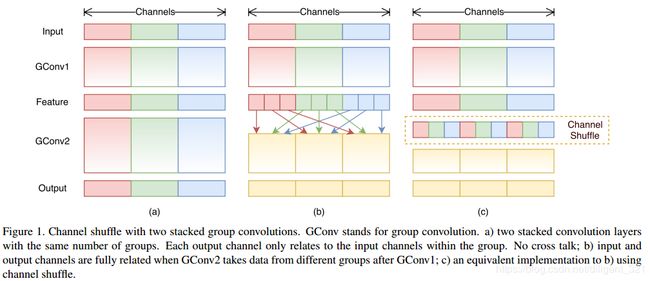
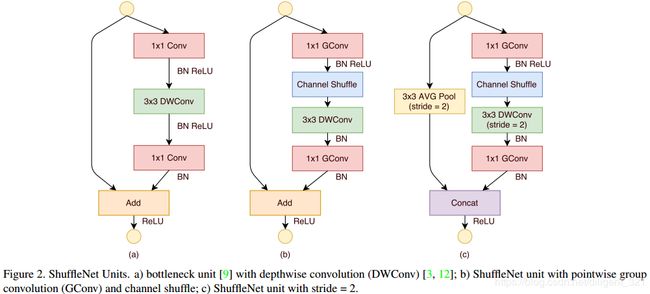
类比于inception网络中的inception模块,shufflenet网络的核心module结构如下图,
2.1.4 mobilenet_v2
Motivation:
(1) 对mobilenet_v1进一步优化;
Solution:
(1) 作者实验发现,线性bottleneck比非线性的top1 精度提升了0.5个点左右,这里的“bottleneck”指的是Figure 3中浅蓝色的输出层;
(2) 使用“Inverted residuals”,提升模型的速度。
这里贴上论文中几个比较重要的图。
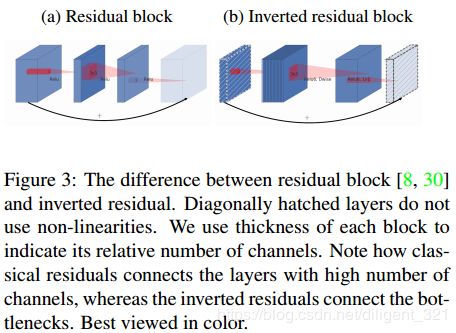
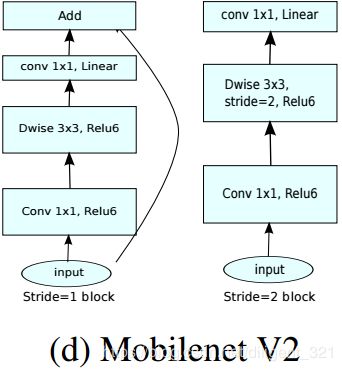
3. 网络结构调整
在实际项目应用中,需要兼顾到模型的准确率、速度和模型大小,可以从以下方面调整所使用的网络结构,
(1) 最直接且常用的方法,使用作者提供的轻量一些的网络,比如mobilenet系列,可以对比不同resolution和width的模型,以满足产品上线要求;
(2) 等比例减少整个网络每一层的channels个数,比如1/2、1/4, 1/8等。以resnet50网络为例,虽然该模型很重,可以通过这种方法对网络结构做简化,使达到mobilenet等小网络的参数量大小。
可能大家看到这里会提问,为什么不直接使用mobilenet这样的小网络,而要改resnet50的网络结构然后重新训练呢,这不是更麻烦吗?这里解释一下,不同的网络结构学习的特征是不一样的,假设我们得到了一个裁剪后的resnet50网络,且其在imagenet测试集上的效果和mobilenet相当,那么当在自己的业务数据集上做迁移学习时,可能mobilenet作为backbone的效果却不如裁剪后的resnet50网络。
(3) 知识蒸馏。就是用小的网络模型来拟合大的网络的效果,这种方式笔者没有实践过,但听朋友说效果还不错。
(4) 通道剪枝。https://github.com/yihui-he/channel-pruning 提供了剪枝vgg和resnet50的代码,但是笔者尝试了修改剪枝resnet50的代码,没有复现成功。说句实话,我也不太看好这种逐层剪枝的方式,因为需要设置很多的超参数,比如每一层要剪掉多少channels等,导致很难调试出比较好的效果。然而,最近作者在ECCV 2018又提出了使用reinforce learning进行剪枝的方法,效果很不错,感兴趣的读者可以读一下原文http://openaccess.thecvf.com/content_ECCV_2018/html/Yihui_He_AMC_Automated_Model_ECCV_2018_paper.html,作者暂未提供源代码。现在鹅厂开源了PocketFlow,一个神经网络模型的压缩和加速库,其提供的基于强化学习的剪枝方法比上面的“channel pruning with LASSO-based channel selection”提升了1.4个百分点,达到了67.9%,虽然跟AMC文章给出的 70.5%有很大差距,不过能够开源也算是很不错的了,同时也期待着该库能够复现出AMC文章的效果。
4. 参考资料
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
http://machinethink.net/blog/mobilenet-v2/.