论文解读-Rethinking on Multi-Stage Networks for Human Pose Estimation
文章目录
- 1 动机
- 2 算法设计
- 2.1 更好的single-stage module
- 2.2 Cross Stage特征融合
- 2.3 Coarse-to-fine Supervision
- 3 实验结果
- 3.1 backbone的影响
- 3.2 stages个数的影响
- 3.3 Cross Stage特征融合的影响
- 3.4 Coarse-to-fine Supervision的影响
- 3.5 高斯核的影响
- 4 总结
- 5 参考资料
新的一年,开始了新的征程。为了在检测方向走的更远,精读论文还是少不了的。笔者最近翻看了微软的COCO比赛官网,发现它包含了如下任务,
(1)目标检测(80类);
(2)人体关节点检测(17个点);
(3)Stuff分割(也即semantic分割,指代不规则目标的分割,比如grass、wall、sky、人群等);
(4)全景分割(包含了semantic分割 和 instance分割);

对于Keypoints 2018比赛,冠军队伍为Face++,亚军为MSRA,后者的工作在“Simple Baselines for Human Pose Estimation and Tracking”中有介绍,算法思路比较简单,大家感兴趣可以去读,本文主要讲解第一名的工作。
1 动机
在前面的博文中,笔者提到人体姿态估计的算法分为两种,top-to-down和bottom-to-up,这是从解决问题的顺序角度划分的。与此同时,如果从算法的网络结构方面考虑,可以划分成single-stage和multi-stage的算法。single-stage指经过一次encoder-decoder操作得到最终的关节点位置,比如上文中提到的MSRA的工作,而multi-stage指经过多次encoder-decoder操作得到最终的关节点位置,比如Hourglass network。
对分类任务而言,更深的网络往往比浅层网络效果更好,但是在COCO keypoints 2016、2017比赛中,冠军算法是single-stage的,为什么会这样呢?
针对multi-stage算法效果不好的问题,作者提出了3点可优化的方向,汇总如下,
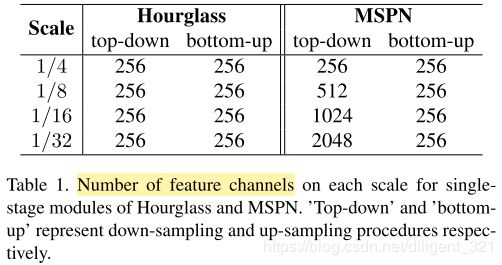
1、采用的single-stage module不够优秀,比如Hourglass module中所有层的channels个数完全相同;
2、越多的single-stage module做级联,信息丢失的越严重,导致模型难以被优化训练;
3、所有的stages按照先后顺序,预测出的关节点位置越来越精细,如何对intermediate supervision策略做调整。
2 算法设计
论文采用了top-down的解决问题的思路,所以论文的重心放在了对单人关节点检测上。针对multi-stage算法存在的问题,作者分别进行了不同的探索。
2.1 更好的single-stage module
在分类算法中,我们能够看到,优秀的网络结构设计都是随着分辨率降低,channels数量增大。对于single-stage的人体姿态估计算法,encoder用于提取global语义特征,而decoder用于恢复局部细节特征。一般来说,丢失的信息很难通过encoder进行恢复,所以可以在encoder阶段做文章,使用更好的encoder。
2.2 Cross Stage特征融合
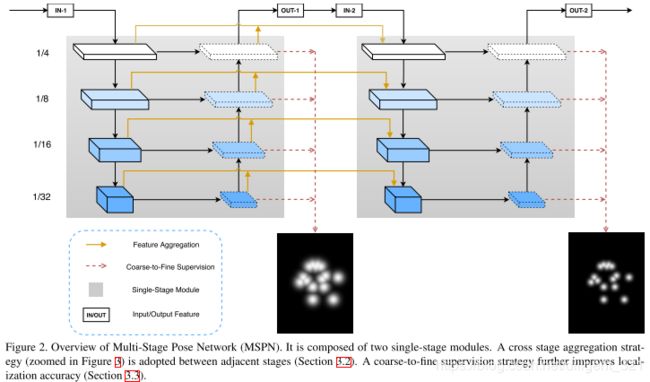
如下图中黄色线条所示,通过在相邻stages之间引入特征融合,有助于将前一stage中的先验信息融入到当前stage网络中,提升整个网络结构的效果,与此同时,从算法训练的角度来说,这种residual design有助于缓解梯度消失问题。
2.3 Coarse-to-fine Supervision
在人体姿态估计任务中,每一个关节点的ground truth位置建模成二维高斯分布,这个是很合理的。对于multi-stage的算法,作者从实验中观察到,算法的不同stage预测的关节点位置越来越精细,所以区别于已有的multi-stage算法“一刀切”的做法,作者在定义ground truth heat map时,在不同stages采用了不同的高斯核大小,也即浅层stage的高斯核较大,深层stage的高斯核较小,图形化解释如下。

另外,关于intermediate supervisions,4个尺度(1/4、1/8、1/16、1/32)的热力图均使用L2 loss,然后对它们求和,作为总的监督信号。该监督信号包含了不同尺度的全局语义信息,有助于定位较难的关节点,比如被遮挡的关节点。这里顺便提及一下,Hourglass network的监督信号为最大尺度(1/4)的特征图。
3 实验结果
在实验部分,作者做了大量的单变量分析,来证明每一个设计细节对算法效果的影响。
3.1 backbone的影响
作者设定了stages个数为1,然后单独验证不同backbone对算法效果的差异,实验结果如下,

显然,随着网络复杂度增加,模型效果的提升越来越不明显。
3.2 stages个数的影响
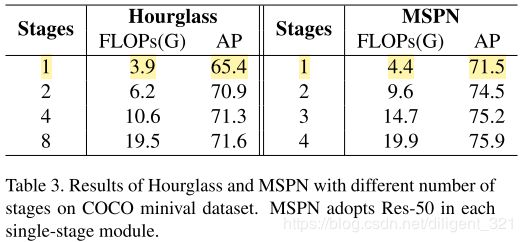
表格化对比结果如下,
图形化对比结果如下,

显然,随着Stages个数增加,Hourglass和MSPN的效果都在提升,但是MSPN提升效果更加明显。
笔者认为,横向对比是没有意义的,因为one-stage的MSPN的复杂度比Hourglass高,AP高也就是意料之中的事情了,并不能说明该网络结构就更好,将单层的Hourglass复杂度增加说不定也能达到MSPN的效果。
3.3 Cross Stage特征融合的影响

显然,采用Cross Stage特征融合策略,MSPN的AP值提升了0.3个点,提升较小。
3.4 Coarse-to-fine Supervision的影响
参见3.3中的表格数据,显然,采用作者提出的Coarse-to-fine Supervision策略,MSPN的AP值提升了0.9个点,提升较大。
笔者认为,这里应该增加一组实验,使用单一scale的监督信号,从而证明作者提出的基于多scale信息的监督信号的有效性。
3.5 高斯核的影响
作者采用了two-stages的网络结构,来验证所提ground truth定义的有效性,实验结果如下表。

显然,采用Coarse-to-fine Supervision策略,效果最好。
4 总结
论文整体的创新性不是很大,主要以效果取胜。论文中提出的3个改进点,事实上,起主要作用的还是对Hourglass network中的encoder结构做修改。因此,总结来说,cv中的不同任务是相关的,在姿态估计网络设计中,可以借鉴分类方向的优秀做法。
5 参考资料
https://arxiv.org/abs/1901.00148
https://arxiv.org/abs/1804.06208