论文解读-CenterNet:Keypoint Triplets for Object Detection
文章目录
- 1 背景
- 2 动机
- 3 算法部分
- 3.1 后处理
- 3.2 center region定义
- 3.3 center pooling
- 3.4 Cascade corner pooling
- 3.5 优化目标
- 4 实验部分
- 5 思考与总结
论文信息
文章链接:https://arxiv.org/abs/1904.08189
作者:Kaiwen Duan
单位:中科院、华为诺亚方舟实验室(实习单位)
代码地址:https://github.com/Duankaiwen/CenterNet
这篇文章,笔者断断续续看了一周,尽管论文的思想说起来简单,但是里面的一些细节还是挺晦涩难懂的,比如为什么center pooling能够work,笔者将自己的理解记录下来,方便以后查看,也希望能对大家有所帮助。
1 背景
论文所提的centernet,是基于 cornernet网络结构,所以在具体介绍centernet 之前,有必要先了解 cornernet相关的基础知识。
cornernet是首个基于关键点的目标检测算法,它的灵感来源于人体姿态关键点检测,它的优点是:避免了设计anchor boxes的复杂操作。整个的网络结构如下图,
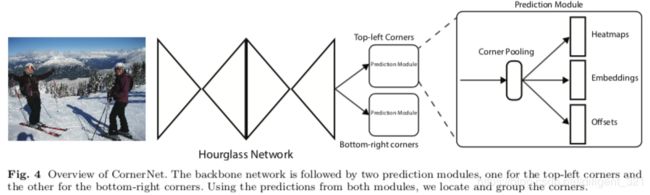
从图中可以看出,输出有三个分支,heatmaps+embeddings+offsets,heatmaps 用于生成所有类别目标的位置图,每一个feature map表示一类目标。embeddings表征了每一个位置的特征向量,用于衡量两个目标点的匹配程度(a pair)。offsets表征了位置点的偏移量,用于对目标的corner位置进行精修,来弥补输出feature map和输入图像misalign带来的影响。
2 动机
尽管cornernet在创新性和效果上确实很棒,但是也存在可以进一步改进的地方,
cornernet使用了corner pooling操作定位关键点,而这个操作是基于bounding box的边界查找最值点,不能感知bounding box内部的语义信息,所以容易有误识别,样例如下图,

为了更具有说服力,作者补充了一组实验,具体研究了不同iou阈值对应的FD,实验结果如下,

其中, F D i = 1 − A P i FD_{i}=1-AP_{i} FDi=1−APi, A P i AP_{i} APi表示iou阈值为 i / 100 i/100 i/100时对应的平均准确率。
论文中的描述如下,
“Corner- Net obtains 32.7% FD rate at IoU = 0.05. This means in average, 32.7 out of every 100 object bounding boxes have IoU lower than 0.05 with the ground-truth.”
笔者认为,这句话的表述有问题。说一下个人理解,假设所有输出bounding boxes数量为m, I o U ≥ 0.05 IoU\geq 0.05 IoU≥0.05的bounding boxes数量为n,那么32.7%表示这n个bounding boxes中,有32.7%比例的boxes分类标签是错误的。(欢迎大家留言讨论)
3 算法部分
为了感知bounding box内部的语义信息,很直接的想法是cornernet+Roi pooling,但是这种级连两阶段的方式计算量很大。
另外一种方法是采用并联的方式利用bounding box内部的语义信息,作者创造性地提出了"keypoint triplets",相比于cornernet中的两个关键点,新增的一个关键点即center point。
3.1 后处理
步骤1: 使用与cornernet相同的方法,生成top-k个bounding boxes;
步骤2: 根据打分值的大小,选择top-k个center keypoints;
步骤3: 使用offset值将center keypoints映射到input image上;
步骤4: 对于每一个bounding box,定义一个central region,并判断是否该central region包含了center keypoint;
步骤5: 如果该central region包含了center keypoint,并且bounding box的预测类别标签和对应的center keypoint相同,则保留当前bounding box;
步骤6: bounding box的打分,用对应的"key point triplets"打分平均值来表示。
3.2 center region定义
不难想象,center region尺寸会影响当前bounding box是否保留。举例来说,(1)假设当前bounding box比较小,也即当前为小目标,定位精度不高,此时若将center region定义的过小,容易导致low recall;(2)假设当前bounding box比较大,也即当前大饿小目标,定位精度会较高,此时若将center region定义的过大,容易导致low precision(误识别)。
因此,作者定义了"scale-aware" center region,也即基于bounding box的尺寸,自动选择center region的尺寸,小目标大center region,大目标小center region。
公式表示如下,
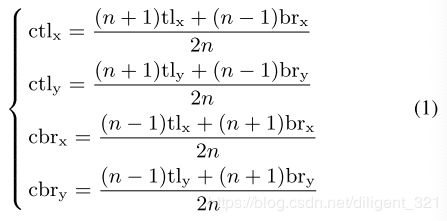
其中, ( t l x , t l y ) , ( b r x , b r y ) (tl_{x}, tl_{y}), (br_{x}, br_{y}) (tlx,tly),(brx,bry)分别表示bounding box的左上和右下角坐标, ( c t l x , c t l y ) , ( c b r x , c b r y ) (ctl_{x}, ctl_{y}), (cbr_{x}, cbr_{y}) (ctlx,ctly),(cbrx,cbry)分别表示center region的左上和右下角坐标。 n n n表示center region的尺度,大的目标对应较小的n,小的目标对应较大的n,论文中设置了2种取值,当bounding box尺寸小于150时,n=3,当大于等于150时,n=5。
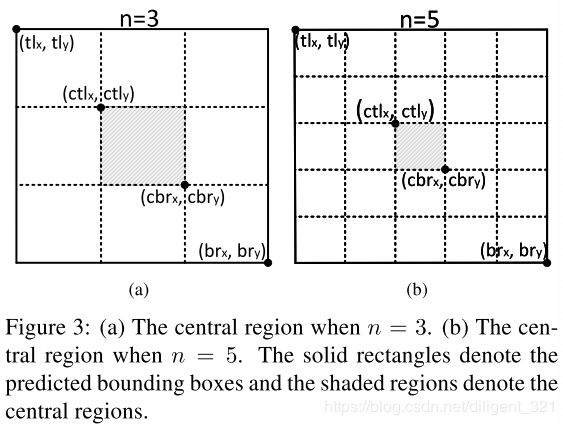
直接看这个公式不好理解,可以结合下面图像化表示抽象出这个问题,即以 c t l x ctl_{x} ctlx为例,已知一维坐标轴上的两点 t l x tl_{x} tlx和 b r x br_{x} brx,求分割比例为 1 : n − 1 1: n-1 1:n−1的点坐标,剩余的三个公式推导过程类似。
图形化表示如下,
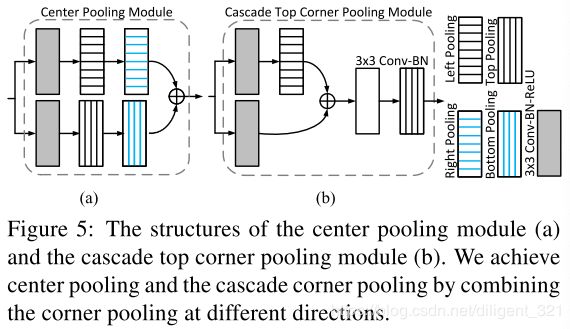
3.3 center pooling
目标的几何中心不一定有很强的判别特征,作者以人体为例给了形象的表述。比如定位出的图像中的目标为人体,那么对该bounding box更有用的信息是head结构,而几何中心(衣物)并不能包含很好的判别特征。
为了能够充分学习到目标的语义信息,作者提出了自己的解决方案center pooling,该操作的具体过程如下,
步骤1: 对于特征图上的每一个像素,分别找到水平和垂直方向的最大值;
步骤2: 将这2个最大值相加,用来表征当前位置为center keypoint的置信度。
笔者对这一点感觉到困惑,为什么这样做就可以呢,举个反例如下,红色的表示图像中的两个显著目标,那么基于上面的定义,center pooling得到的top-3个center keypoint如下图中绿色圆圈所示,显然,点A为误识别。(欢迎大家留言讨论)

3.4 Cascade corner pooling
在介绍cascade corner pooling之前,先看一下原生的corner pooling是什么样的,如图(b),显然,这种基于边缘的定位方法,导致定位出来的corner point对边缘很敏感,也就导致了Figure 1中的误识别。
那么,怎么解决这个问题呢?
作者采用了cascade corner pooling的思路,即让corners理解bounding box内部的信息,效果图如下图©所示。具体来说,对于特征图上的某一个像素,先采用corner pooling的思路定位出边界上的最大值点,然后,以当前最大值点为起点,沿着目标内部的方向找第2个最大值点,最后,将这4个最值点相加,用来表征当前像素点为corner的置信度,这里大家应该就可以理解cascade的意思了。
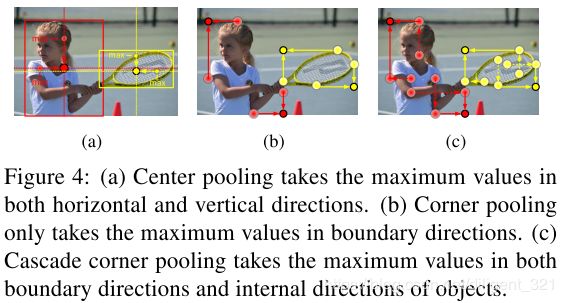
为了采用统一的表达,center pooling和cascade corner pooling均可以通过组合不同方向的corner pooling来实现,图形化解释如下,
3.5 优化目标
同cornernet类似,这里也是优化三个目标,(1)关键点分类任务;(2)关键点定位任务;(3)关键点配对任务,
loss函数的数学定义如下,
![]()
其中,"co"表示corner keypoint,"ce"表示center keypoint, L d e t 、 L o f f 和 L p u s h L_{det}、L_{off}和L_{push} Ldet、Loff和Lpush分别对应了上面的三个目标。
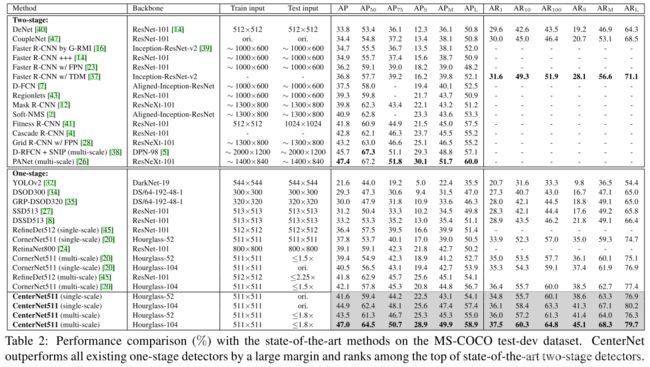
4 实验部分
centernet的效果是很给力的,47.0%的AP相对于其它One-stage的算法有很大的优势。这里还需要提及一下,tridentnet在加了各种tricks之后的AP为48.4%,所以现在称centernet是检测算法里的效果第一,笔者觉得有些不太合适。
5 思考与总结
(1)论文作者是先跑了cornernet的基线代码,然后发现到这些问题的,而不是纸上谈兵,这种严谨的思路是值得借鉴的;
(2)论文中仅使用了2种尺度系数来定义center region的尺寸,感觉不够精细,对center region的尺寸建模,使其能够根据bounding box尺寸动态调整,或许是一个可以深挖的方向;
(3)论文作者引入了目标内的信息,从而显著提升检测效果,这种思想是很好的,但是center pooling的实现方式感觉还有些粗糙,大家也可以一起往这个方向去思考。