关于zookeeper的一些想法
zookeeper是一个开源的分布式的,为分布式应用提供协调服务的apache项目。
zookeeper从设计模式的角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据(每台机器都关心的),然后接受观察者的注册,一旦这些数据的状态发生了变化,zookeeper就将通知再zookeeper上注册了的那些观察者做出相应的反应,从而实现集群中累死master/salve管理模式。
zookeeper存储的数据不大。
zookeeper的应用场景:
提供的服务包括:分布式消息同步和协调机制、服务器节点动态上下线、统一配置管理、负载均衡、集群管理等。
什么是分布式?
简单的说,一个软件不在一台机器上全功能的运行,这个软件分布到很多机器上,每个机器上有一个角色,不同的机器有不同的 角色,这些角色互相协作起来,才能完成软件系统的功能。
什么是协调服务?
分布式系统必须有master节点,其他节点可以是slave,如果master宕机了,此时分布式系统不能对外提供服务了。解决方案是从剩下的slave中选出一个节点当作master,详细的讲,zookeeper提供了监听的服务,假如master向zookeeper集群中写了一条目录数据/server/master/server01,salve就监听master这个节点的数据,一旦master发生宕机,zookeeper将修改数据/server/maseter,此事发生了一个修改数据的事件,这个事件就会被通知到各个salve,然后从salve中选举出master。
分布式的协调场景(zookeeper可以用在哪些地方)
1.主节点的主备切换
举个栗子,有两台机器上部署了相同的软件,一台机器server01的状态是active,另一台机器server02的状态是standby,此时active的机器向zookeeper中写入一条目录数据/active/server01,standby注册了监听,客户端通过zookeeper得知目前处于活跃状态的机器是server01,然后请求server01。如果server01发生宕机,zookeeper会修改目录数据/active/server01为/active,此时发生了一个变更事件,zookeeper将这个事件发送给server02,server02收到原/active的通知,修改自己的状态为active,然后想zookeeper中更改目录数据/active/server02
2.主节点的选举
同样举个栗子,有一台master节点server01,两台slave节点server02、server03,server01向zookeeper中注册并写入数据/active/server01、/servers/server02,server02想zookeeper注册并写入数据/servers/server02,server03向zookeeper注入并写入数据/servers/server03,所有机器都监听zookeeper中的/active/server01,每台机器都存在一个逻辑,当主节点宕机时,所有节点都选择主机id最大的那台机器为master。如果server01出现宕机,zookeeper会将/active/server01修改为/active,同时将/servers目录中的server01删除,并将server01挂掉的事件通知给slave,每台机器都会扫描/servers目录,此时能扫描到活着的节点,每台机器选举主机id最大的机器为master。
3.分布式共享锁
还是举个栗子,分布式系统中有三台不同功能的机器要访问阿里的服务,由于阿里的资源有限,每次只能有一台机器去访问,在这种情况下,使用分布式共享锁来解决。zookeeper有一个功能是sequential znode,对写入的数据拼接自增的序号。每台机器向zookeeper的/locks中写入数据lock,第一个写入的数据的是lock0000001,第二个写入的数据的是lock0000002,第三个写入的数据的是lock0000003,每个写入的数据并返回到相应的机器中保存。当三台机器需要访问服务时,每台机器去访问/locks目录下的数据,对比目录下的数据,自己的数据是否是最小的,如果是最小的,则可以去访问服务,如果不是最小的,则只能等待。当服务访问完成后,删除原来的数据lock000001,通过序号自增的功能,写入新的数据lock0000004。
4.统一配置管理
把配置文件放在zookeeper,修改的配置文件可以通知到各个节点,各个节点可以获取zookeeper中的配置文件
5.统一名称服务
dubbo
虽然说zookeeper可以提供各种服务,但是zookeeper在底层其实只提供了两个功能
- 管理(存储、读取)用户程序提交的数据
- 并为用户程序提供数据节点的监听服务
zookeeper的特性:
- zookeeper:一个leader,多个follower组成的集群
- 全局一致性:每个server保存一份相同的数据副本,无论连接到哪个server,数据都是要一致的。
- 分布式读写,更新请求,转发,由leader来实施。
- 更新请求顺序执行,来自一个client的更新请求按其发送顺序依次执行。
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性(涉及到paxos算法),在一定的时间范围内,client能读到最新数据
zookeeper的数据结构
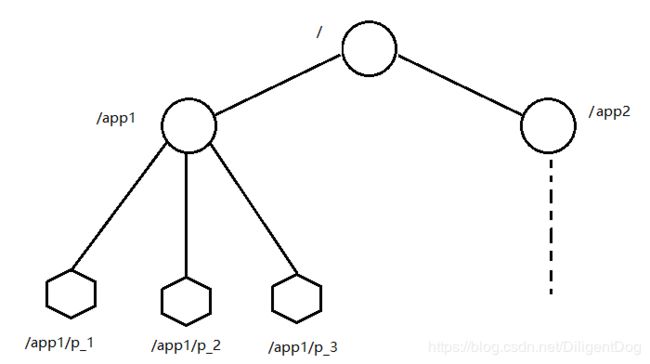
- 层次化的目录结构,命名符合常规文件系统规范(如下图)
- 每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
- 节点znode可以包含数据(只能存储很小的数据<1M,最好1k字节以后)和子节点(但是ephemeral类型的节点不能有子节点)
- 客户端应用可以在节点上设置监视器(监听器监听成功后,就失效了,如果想再监听,需要再在听的响应里再设置监听)
节点的类型
1、znode有两种类型
短暂(ephemeral)(客户端断开连接,节点自己删除)
持久(persistent)(客户端断开连接,不删除)
2.znode有四种形成的目录节点(默认是persistent)
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列,数据后会加上自增的序号)
EPHEMERAL
EPHEMERAL_SEQUENTIAL(临时序列,数据后会加上自增的序号)