前言: 以前学习基础知识的时候总看别人写的入门文章,但有时候还是一脸懵逼,直到自己用心阅读了MDN的英文文档才对基础知识的一些理论有了更深的理解,所以我在边阅读文档的时候边记录下帮助比较大的,也方便大家简洁学习。建议英文不好的同学可以先看我之前学的中文版基础知识再来学习这篇英文整理。Service Worker基础知识整理
Service worker concepts
Service workers essentially act as proxy servers that sit between web applications, the browser, and the network (when available).
A service worker is an event-driven worker registered against an origin and a path.A service worker is run in a worker context: it therefore has no DOM access, and runs on a different thread to the main JavaScript that powers your app, so it is not blocking. It is designed to be fully async; as a consequence, APIs such as synchronous XHR and localStorage can't be used inside a service worker.
Service worker register
ExamplesSection The examples described here should be taken together to get a better understanding of how service workers scope applies to a page.
The following example uses the default value of scope (by omitting it). The service worker in this case will controlexample.com/index.html as well as pages underneath it, likeexample.com/product/description.html.
if ('serviceWorker' in navigator) {
// Register a service worker hosted at the root of the
// site using the default scope.
navigator.serviceWorker.register('/sw.js').then(function(registration) {
console.log('Service worker registration succeeded:', registration);
}, /*catch*/ function(error) {
console.log('Service worker registration failed:', error);
});
} else {
console.log('Service workers are not supported.');
}
note this is the file's URL relative to the origin, not the JS file that references it.
A single service worker can control many pages. Each time a page within your scope is loaded, the service worker is installed against that page and operates on it. Bear in mind therefore that you need to be careful with global variables in the service worker script: each page doesn’t get its own unique worker.
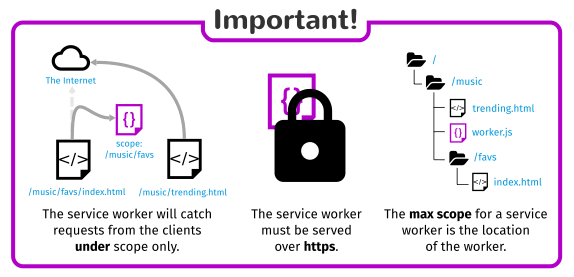
The following code, if included in a page at the root of a site, would apply to exactly the same pages as the example above. Remember the scope, when included, uses the page's location as its base. Alternatively, if this code were included in a page atexample.com/product/description.html, the scope of './' would mean that the service worker only applies to resources underexample.com/product. If I needed to register a service worker on example.com/product/description.html that applied to all ofexample.com, I would leave off the scope as above.
if ('serviceWorker' in navigator) {
// Register a service worker hosted at the root of the
// site using a more restrictive scope.
navigator.serviceWorker.register('/sw.js', {scope: './'}).then(function(registration) {
console.log('Service worker registration succeeded:', registration);
}, /*catch*/ function(error) {
console.log('Service worker registration failed:', error);
});
} else {
console.log('Service workers are not supported.');
}
If your server worker is active on a client being served with the Service-Worker-Allowed header, you can specify a list of max scopes for that worker.
Note: localStorage works in a similar way to service worker cache, but it is synchronous, so not allowed in service workers.
Note: IndexedDB can be used inside a service worker for data storage if you require it.
Download, install and activate
- Download
The service worker is immediately downloaded when a user first accesses a service worker–controlled site/page.
After that, it is downloaded every 24 hours or so. It may be downloaded more frequently, but it must be downloaded every 24 hours to prevent bad scripts from being annoying for too long.
- Install
Installation is attempted when the downloaded file is found to be new — either different to an existing service worker (byte-wise compared), or the first service worker encountered for this page/site.
You can listen out for the InstallEvent; a standard action is to prepare your service worker for usage when this fires, for example by creating a cache using the built in storage API, and placing assets inside it that you'll want for running your app offline.
- Activate
If there is an existing service worker available, the new version is installed in the background, but not yet activated — at this point it is called the worker in waiting. It is only activated when there are no longer any pages loaded that are still using the old service worker. As soon as there are no more pages to be loaded, the new service worker activates (becoming the active worker). Activation can happen sooner using ServiceWorkerGlobalScope.skipWaiting() and existing pages can be claimed by the active worker using Clients.claim().
There is also an activate event. The point where this event fires is generally a good time to clean up old caches and other things associated with the previous version of your service worker.
Your service worker can respond to requests using the FetchEvent event. You can modify the response to these requests in any way you want, using the FetchEvent.respondWith method.
Because oninstall/onactivate could take a while to complete, the service worker spec provides a waitUntil method, once this is called oninstall or onactivate, it passes a promise. Functional events are not dispatched to the service worker until the promise is successfully resolved.
use case ideas
- Background data synchronization.
- Responding to resource requests from other origins.
- Receiving centralized updates to expensive-to-calculate data such as geolocation or gyroscope, so multiple pages can make use of one set of data. Client-side compiling and dependency management of CoffeeScript, less, CJS/AMD modules, etc. for development purposes. Hooks for background services.
- Custom templating based on certain URL patterns.
- Performance enhancements, for example pre-fetching resources that the user is likely to need in the near future, such as the next few pictures in a photo album.
Basic architecture
With service workers, the following steps are generally observed for basic set up:
- The service worker URL is fetched and registered via serviceWorkerContainer.register().
- If successful, the service worker is executed in a ServiceWorkerGlobalScope; this is basically a special kind of worker context, running off the main script execution thread, with no DOM access.
- The service worker is now ready to process events.
- Installation of the worker is attempted when service worker-controlled pages are accessed subsequently. An Install event is always the first one sent to a service worker (this can be used to start the process of populating an IndexedDB, and caching site assets). This is really the same kind of procedure as installing a native or Firefox OS app — making everything available for use offline.
- When the oninstall handler completes, the service worker is considered installed.
- Next is activation. When the service worker is installed, it then receives an activate event. The primary use of onactivate is for cleanup of resources used in previous versions of a Service worker script.
- The Service worker will now control pages, but only those opened after the register() is successful. i.e. a document starts life with or without a Service worker and maintains that for its lifetime. So documents will have to be reloaded to actually be controlled.

live demo
- line: https://mdn.github.io/sw-test/
- code: https://github.com/mdn/sw-test
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('v1').then(function(cache) {
return cache.addAll([
'/sw-test/',
'/sw-test/index.html',
'/sw-test/style.css',
'/sw-test/app.js',
'/sw-test/image-list.js',
'/sw-test/star-wars-logo.jpg',
'/sw-test/gallery/bountyHunters.jpg',
'/sw-test/gallery/myLittleVader.jpg',
'/sw-test/gallery/snowTroopers.jpg'
]);
})
);
});
self.addEventListener('fetch', function(event) {
event.respondWith(caches.match(event.request).then(function(response) {
// caches.match() always resolves
// but in case of success response will have value
if (response !== undefined) {
return response;
} else {
return fetch(event.request).then(function (response) {
// response may be used only once
// we need to save clone to put one copy in cache
// and serve second one
let responseClone = response.clone();
caches.open('v1').then(function (cache) {
cache.put(event.request, responseClone);
});
return response;
}).catch(function () {
return caches.match('/sw-test/gallery/myLittleVader.jpg');
});
}
}));
});
event
- fetch
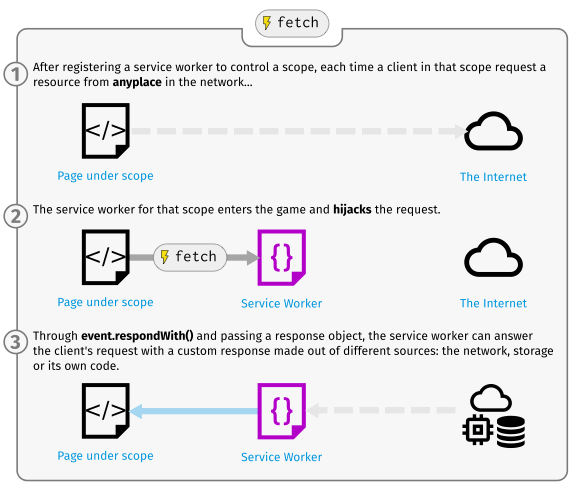
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(resp) {
return resp || fetch(event.request).then(function(response) {
let responseClone = response.clone();
caches.open('v1').then(function(cache) {
cache.put(event.request, responseClone);
});
return response;
});
}).catch(function() {
return caches.match('/sw-test/gallery/myLittleVader.jpg');
})
);
});
Cloning the response is necessary because request and response streams can only be read once. In order to return the response to the browser and put it in the cache we have to clone it. So the original gets returned to the browser and the clone gets sent to the cache. They are each read once.
- activate
self.addEventListener('activate', function(event) {
var cacheKeeplist = ['v2'];
event.waitUntil(
caches.keys().then(function(keyList) {
return Promise.all(keyList.map(function(key) {
if (cacheKeeplist.indexOf(key) === -1) {
return caches.delete(key);
}
}));
})
);
});
Developer toolsSection
Chrome has chrome://inspect/#service-workers, which shows current service worker activity and storage on a device, and chrome://serviceworker-internals, which shows more detail and allows you to start/stop/debug the worker process. In the future they will have throttling/offline modes to simulate bad or non-existent connections, which will be a really good thing.
articles
https://developer.mozilla.org/en-US/docs/Web/API/ServiceWorkerContainer/register
https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API