基于AdaBoost算法的人脸检测经典论文研究之三
本文是我看论文的过程中自己独立总结的,也查了很多资料,花了大约两周时间,期望能对你有所帮助。欢迎转载请注明本博网址,如有不足还望大家多多指教
自从2001年Viola和Jones发表了《rapid object detection using a boosted cascade of simple features》的文章以后,在学术界和商业界研究人脸检测的热情就朝向了adaboost算法,也发表了很多文献可供参考学习。但是如何训练分类器却现有文献参考。所以,本文在本文在Viola和Jones人脸检测算法构建的框架下,从理论的角度分析其可行性,从是实验的角度形成的详细的训练过程,弥补的如何训练人脸检测分类器方面文献的空白。
1 人脸检测概念的定义
人脸定位,人脸检测和人脸识别这几个概念我们往往混为一谈,其实它们有很大差别。人脸定位是已经知道图片中人脸的个数,需要我们找到该图片中人脸的大小和位置,它是三者之间最为简单的一个;人脸检测是给定一张照片,来确定其中是否含有人脸,如果有的话,返回人脸的个数,大小和位置信息;人脸识别是在已经识别到人脸的前提下,识别该人脸是谁,是张三还是李四,而不是像人脸检测那样,人脸检测判定的是人脸还是非人脸。
2 判定人脸和非人脸的准则
以往文献判定人脸的标准大都说的含含糊糊,要么一带而过,本文明确提出使用为了使得检测结果可以评估,本文采用Rainer Lienhart提出的两条判决人脸、非人脸的准则,这样使得评价结果量化,方便计算机的执行:
1)看检测窗口的中心(也有说是重心或质心的),检测结果的窗口中心与实际人脸标注窗口的的中心之间的欧式距离小于实际人脸标注窗口宽的30%;
2)看检测窗口的边长,检测结果窗口的宽不小于实际人脸标注窗口宽的50%,同时不超过人脸区域宽的50%,检测窗口不能太大,也不能太小。
3 准备训练样本
本文中正样本主要来自于FERET数据库,FRGc(FaceRecogni-
tionGrandehallenge,FRee)数据库,中国科学院eAs一PEAL数据库,还有一些从互联网中收集的人脸图片,但是为了增加样本的多样性,还需要自己再收集更多的样本。
3.1 截取人脸图片
切割的时候以人的双眼连线中点为参考点原点,将两眼中心点之间的距离设为d。切割时,先找到原点,在水平方向左右各截取长度d作为人脸区域矩形框的左右边界,上下各截取长度为0.67d和1.33d作为人脸区域矩形框的上下边界。这样就截取了一个2d*2d的人脸区域矩形框,如下图所示:
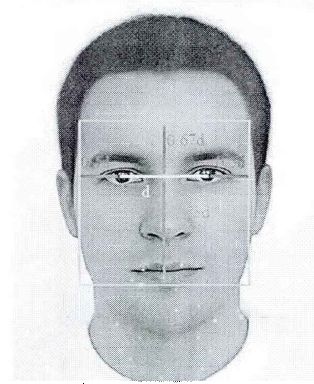
优点:人眼的位置比较容易查找,而且这样截取的人脸大小比例更一致,极大地消除了个人主观因素的干扰。
3.2 截取人脸的优化
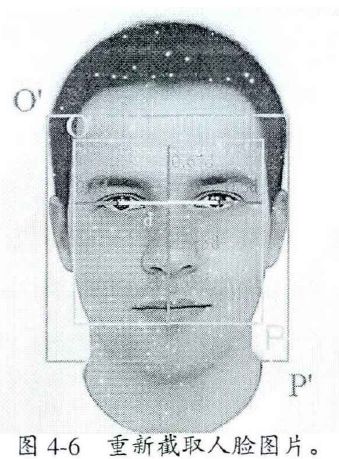
实践告诉我们,在正样本中包含有一定的背景会效果更好,不过背景过多训练时容易当成负样本来使用,一点背景不包含也是不适用的。这个度怎么把握还没有文献量化,本文做法如下:
设原截取的图片矩形区域左上角顶点坐标为(Ox,Oy),右下角顶点坐标为(Px,Py),新矩形区域左上角和右下角顶点坐标分别为(Ox’,Oy’),(Px’,Py’),设k为一比例系数,新旧坐标计算公式如下
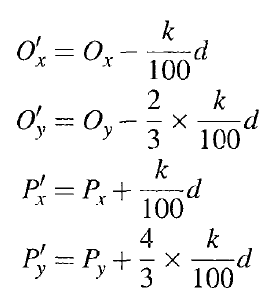
实验中系数k ={ 00, 05;10,15, 20; 25; 30; 35; 40; 45, 50},实验表明,当10
3.3 通过变换生成更多正样本
旋转:以双眼连线中点为中心,旋转-10至10度
缩放:以人眼连线中点为中心,缩放比例为[0.9,1.1]之间;
镜像
平移:在原图人脸的区域水平和垂直方向上进行平移,平移大小不超过原图的5%。
3.4 加入更多样化的人脸
增加局部光照变化变化剧烈和暗肤色的正样本,但是数量一定要多,不能太少,这样训练出来的分类器有更好的鲁棒性。还可以再增加一些更贴近生活的真实数据。
4 如何构造弱分类器(关键是确定θ)
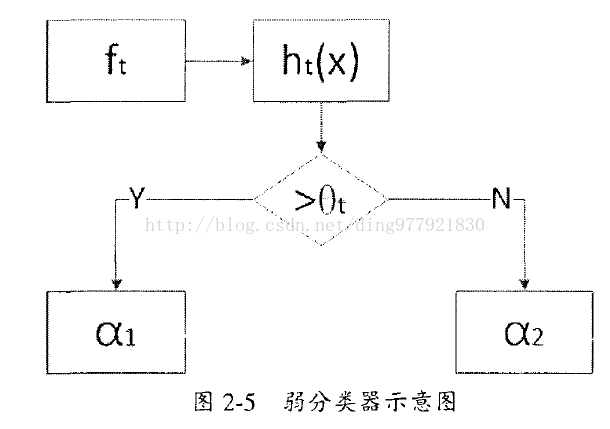
在构造Haar弱分类器的过程中,Viola和Jones对分类器作出了约束:弱分类器仅仅依赖单一的Haar特征进行分类,换句一话说每个弱分类器对应于单一的Haar特征。若分类器的数学表达式如下:


一个24*24的窗口里的haar特征有180,000种,对于其中一个haar特征,比如上图第一行的左图,就是一个haar特征,黑白的小方框在小窗口中有一定的类型,大小和位置,这才是一个完整的haar特征。对该haar特征覆盖到样本集的正样本和负样本的积分图上去,这样就可以得到一个数值,即haar特征值。把所有的haar特征值进行升序排列,图中圆圈代表人脸,菱形代表非人脸。
如下:

从图中可以看出,想完全区分开人脸和非人脸很难,但是人脸大部分集中在左侧,非人脸主要集中在右侧,这样就可以在中间合适的位置找到一个位置,大致把人脸和非人脸区分开来,这个位置其实就是阈值θj。
选择θ的准则函数:
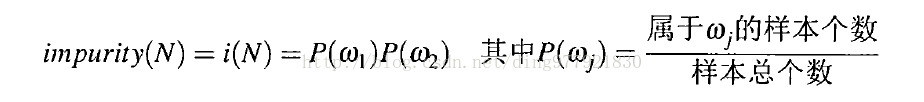
在计算p是还要乘以样本的权重,在选取阈值是选择不纯度下降最快的那个值。不纯度下降公式如下:
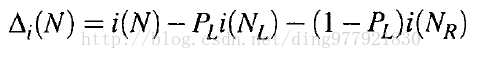
这样,在每个位置选取一个阈值θ,θ=(f1+f2)/2,f1和f2分别为相邻两个特征值。对于N个正负样本可以得到N-1个θ。对于每个θ计算不纯度下降,选取最大的那个作为最优弱分类器的阈值,一个好的阈值是可以使得左右叶子节点的不纯度都很低,这样就最终使用一个特征就孵化出了一个最优弱分类器。
5 实验验证级联分类器层数对性能的影响
级联分类器的层数与其性能并没有必然联系,但却会影响训练过程中所需的正负样本数量、训练时间和检测时间。
1)从检测率来看,层数多,检测率低;层数少,检测率高;
2)从误检率来看,层数多,误检率低;层数少,无减率高;
3)从所需正负样本数量来看,层数对消耗的正样本数量影响非常小可以忽略不计,但是对消耗的负样本却影响非常大,层数越多,所需负样本越多。对负样本的拒绝能力也越强;
4)层数越多,训练时间越长;
5)层数与检测时间无规律。
6 单层训练样本数量对性能的影响
更多的训练样本带来更好的性能,但是同时也必须指出更多的训练样本对性能提升有限,从5000正样本到50000正样本有进10倍的增加,但增加的正样本对级联分类器性能的提升非常有限。如果想进一步提升级联分类器的性能,光靠增加样本是行不通的,因为训练时间太长。
7 正负样本比例对级联分类器性能的影响
以前在一个博客中认为,正负样本比例在1:3比较好。本文中在CMU一MIT正脸测试集上,5:3的正负训练样本比例获得了最高的检测率,但在FG测试集上效果很差,实验表明正负样本比例对分类器性能的影响并无一致结论,从逻辑回归的角度看,正负样本的比例与最终的结果并没有太直接的联系,而只与正负样本的分布有关。
参考文献:
1 《基于adaboost的人脸检测》魏喆 2012.03.01 北京邮电大学。
2 《rapid object detection using a boosted cascade of simple features》 2001