运行环境:win10 64位 py 3.6 pycharm 2018.1.1
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble,naive_bayes
def load_data_classification():
digits = datasets.load_digits()
return cross_validation.train_test_split(digits.data,digits.target,test_size=0.25,random_state=0)
def test_AdaBoostClassifier(*data):
X_train,X_test,y_train,y_test=data
clf = ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
estimators_num = len(clf.estimators_)
X = range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label='Traing score')
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_title("AdaBoostClassifier")
plt.show()
X_train,X_test,y_train,y_test = load_data_classification()
test_AdaBoostClassifier(X_train,X_test,y_train,y_test)

def test_AdaBoostClassifier_Base_classifier(*data):
X_train, X_test, y_train, y_test = data
fig = plt.figure()
ax = fig.add_subplot(2,1,1)
clf = ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
estimators_num = len(clf.estimators_)
X = range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label='Traing score')
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='lower right')
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier With Decision Tree")
ax = fig.add_subplot(2,1,2)
clf = ensemble.AdaBoostClassifier(learning_rate=0.1,base_estimator=naive_bayes.GaussianNB())
clf.fit(X_train, y_train)
estimators_num = len(clf.estimators_)
X = range(1, estimators_num + 1)
ax.plot(list(X), list(clf.staged_score(X_train, y_train)), label='Traing score')
ax.plot(list(X), list(clf.staged_score(X_test, y_test)), label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='lower right')
ax.set_ylim(0, 1)
ax.set_title("AdaBoostClassifier With GaussianNB")
plt.show()
X_train,X_test,y_train,y_test = load_data_classification()
test_AdaBoostClassifier_Base_classifier(X_train,X_test,y_train,y_test)

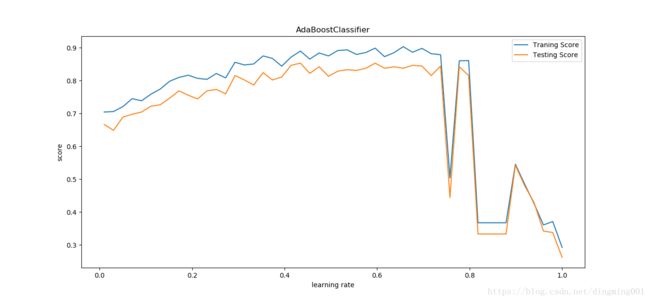
def test_AdaBoostClassifier_learning_rate(*data):
X_train, X_test, y_train, y_test = data
learning_rates = np.linspace(0.01,1)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
traing_scores = []
testing_scores = []
for learning_rate in learning_rates:
clf = ensemble.AdaBoostClassifier(learning_rate=learning_rate,n_estimators=500)
clf.fit(X_train,y_train)
traing_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label='Traning Score')
ax.plot(learning_rates,testing_scores,label='Testing Score')
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_title('AdaBoostClassifier')
plt.show()
X_train,X_test,y_train,y_test = load_data_classification()
test_AdaBoostClassifier_learning_rate(X_train,X_test,y_train,y_test)
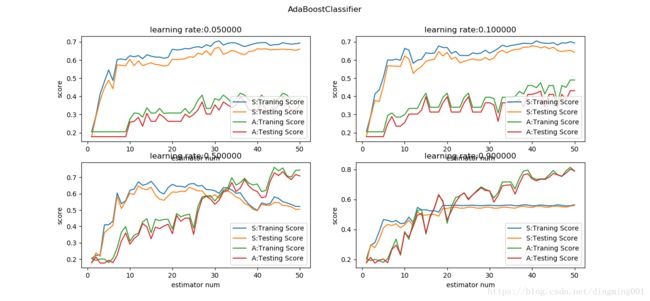
def test_AdaBoostClassifier_algorithm(*data):
X_train, X_test, y_train, y_test = data
algorithms = ['SAMME.R','SAMME']
fig = plt.figure()
learning_rates = [0.05,0.1,0.5,0.9]
for i,learning_rate in enumerate(learning_rates):
ax = fig.add_subplot(2,2,i+1)
for i, algorithm in enumerate(algorithms):
clf = ensemble.AdaBoostClassifier(learning_rate=learning_rate,algorithm=algorithm)
clf.fit(X_train,y_train)
estimator_num = len(clf.estimators_)
X = range(1,estimator_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label='%s:Traning Score'%algorithm[i])
ax.plot(list(X),list(clf.staged_score(X_test, y_test)),label='%s:Testing Score' %algorithm[i])
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='lower right')
ax.set_title('learning rate:%f'%learning_rate)
fig.suptitle('AdaBoostClassifier')
plt.show()
X_train,X_test,y_train,y_test = load_data_classification()
test_AdaBoostClassifier_algorithm(X_train,X_test,y_train,y_test)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets,cross_validation,ensemble,naive_bayes,svm
def load_data_regression():
diabetes = datasets.load_diabetes()
return cross_validation.train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0)
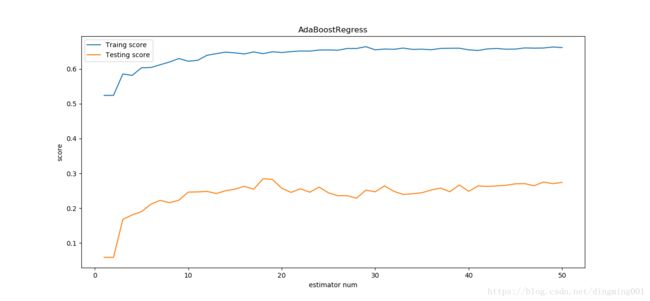
def test_AdaBoostRegressor(*data):
X_train, X_test, y_train, y_test = data
regr = ensemble.AdaBoostRegressor()
regr.fit(X_train,y_train)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
estimators_num = len(regr.estimators_)
X = range(1,estimators_num+1)
ax.plot(list(X), list(regr.staged_score(X_train, y_train)), label='Traing score')
ax.plot(list(X), list(regr.staged_score(X_test, y_test)), label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_title("AdaBoostRegress")
plt.show()
X_train, X_test, y_train, y_test = load_data_regression()
test_AdaBoostRegressor(X_train, X_test, y_train, y_test)
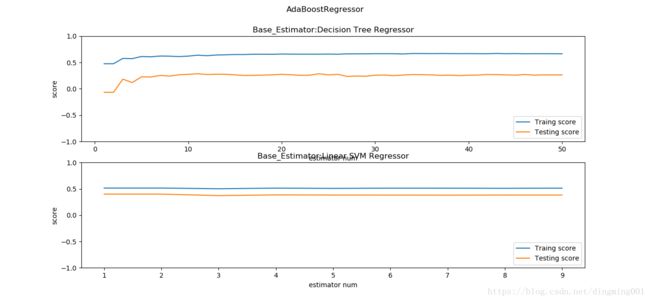
def test_AdaBoostClassifier_Base_regr(*data):
X_train, X_test, y_train, y_test = data
fig = plt.figure()
regrs = [ensemble.AdaBoostRegressor(),ensemble.AdaBoostRegressor(base_estimator=svm.LinearSVR(epsilon=0.01,C=100))]
labels = ['Decision Tree Regressor','Linear SVM Regressor']
for i, regr in enumerate(regrs):
ax = fig.add_subplot(2,1,i+1)
regr.fit(X_train,y_train)
estimators_num = len(regr.estimators_)
X = range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label='Traing score')
ax.plot(list(X),list(regr.staged_score(X_test,y_test)),label='Testing score')
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='lower right')
ax.set_ylim(-1,1)
ax.set_title("Base_Estimator:%s"%labels[i])
plt.suptitle("AdaBoostRegressor")
plt.show()
X_train,X_test,y_train,y_test = load_data_regression()
test_AdaBoostClassifier_Base_regr(X_train,X_test,y_train,y_test)
def test_AdaBoostRegressor_learning_rate(*data):
X_train, X_test, y_train, y_test = data
learning_rates = np.linspace(0.01,1)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
traing_scores = []
testing_scores = []
for learning_rate in learning_rates:
regr = ensemble.AdaBoostRegressor(learning_rate=learning_rate,n_estimators=500)
regr.fit(X_train,y_train)
traing_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label='Traning Score')
ax.plot(learning_rates,testing_scores,label='Testing Score')
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_title('AdaBoostRegressor')
plt.show()
X_train,X_test,y_train,y_test = load_data_regression()
test_AdaBoostRegressor_learning_rate(X_train,X_test,y_train,y_test)
def test_AdaBoostRegressor_loss(*data):
X_train, X_test, y_train, y_test = data
losses=['linear','square','exponential']
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
for i,loss in enumerate(losses):
regr = ensemble.AdaBoostRegressor(loss=loss,n_estimators=30)
regr.fit(X_train,y_train)
estimators_num=len(regr.estimators_)
X = range(1,estimators_num+1)
ax.plot(list(X),list(regr.staged_score(X_train,y_train)),label='Traning Score:loss=%s'%loss)
ax.plot(list(X), list(regr.staged_score(X_test, y_test)), label='Traning Score:loss=%s' % loss)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc='best')
ax.set_ylim(-1,1)
ax.set_title('AdaBoostRegressor')
plt.show()
X_train,X_test,y_train,y_test = load_data_regression()
test_AdaBoostRegressor_loss(X_train,X_test,y_train,y_test)
