RabbitMQ可靠性投递与实践
目录
可靠性投递
确保消息发送到RabbitMQ服务器
确保消息路由到正确的队列
确保消息在队列正确地存储
确保消息从队列正确地投递到消费者
消费者回调
补偿机制
消息幂等性
消息的顺序性
高可用架构
RabbitMQ集群
RabbitMQ镜像队列
HAproxy负载+Keepalived高可用
实践经验总结
配置文件与命名规范
调用封装
信息落库+定时任务
减少连接数
可靠性投递
首先需要明确,效率与可靠性是无法兼容的,如果要保证每一个环节都成功,势必会对消息的手法效率造成影响。如果是一些业务实现时,一致性要求不是特别高的场合,可以牺牲一些可靠性来换取效率。
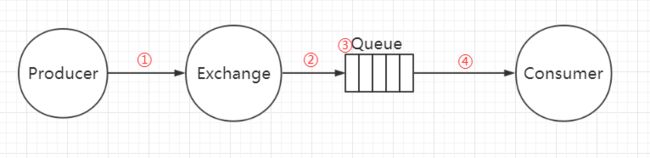
①代表消息从生产者发送到Exchange;
②代表消息从Exchange路由到Queue;
③代表消息在Queue中存储;
④代表消费者订阅Queue并消费消息。
确保消息发送到RabbitMQ服务器
可能因为网络或者Broker的问题导致①失败,而生产者是无法知道消息是否正确发送到Broker的。
有两种解决方案,第一种是Transaction(事物)模式,第二种Confirm(确认)模式。
在通过channel.txSelect方法开启事物之后,我们便可以发布消息给RabbitMQ了,如果事物提交成功,则消息一定到达了RabbitMQ中,如果在事物提交执行之前由于RabbitMQ异常崩溃或者其他原因抛出异常,这个时候我们便可以将其捕获,进而通过执行channel.txRollback方法来实现事物回归。使用事物机制的话会耗尽RabbitMQ的性能,一般不建议使用。
生产者通过调用channel.confirmSelect方法(即Confirm.Select命令)将信道设置为confirm模式。一旦消息被投递到所有匹配的队列之后,RabbitMQ就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这就使得生产者知晓消息已经正确到达了目的地。
确保消息路由到正确的队列
可能因为路由关键字错误,或者队列不存在,或者队列名称错误导致②失败。
使用mandatory参数和ReturnListener,可以实现消息无法路由的时候返回给生产者。
另一种方式就是使用备份交换机(alternate-exchange),无法路由的消息会发送到这个交换机上。
Map arguments = new HashMap();
// 指定交换机的备份交换机
arguments.put("alternate-exchange","ALTERNATE_EXCHANGE");
channel.exchangeDeclare("TEST_EXCHANGE","topic", false, false, false, arguments); 确保消息在队列正确地存储
可能因为系统宕机、重启、关闭等情况导致存储在队列地消息丢失,即③出现问题。
解决方案:
队列持久化
// String queue, boolean durable, boolean exclusive, boolean autoDelete, Map arguments
channel.queueDeclare(QUEUE_NAME, true, false, false, null); 交换机持久化
// String exchange, boolean durable
channel.exchangeDeclare("MY_EXCHANGE","true");消息持久化
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 2代表持久化,其他代表瞬态
.build();
channel.basicPublish("", QUEUE_NAME, properties, msg.getBytes());确保消息从队列正确地投递到消费者
如果消费者收到消息后未来得及处理即发生异常,或者处理过程中发生异常,会导致④失败。
为了保证消息从队列可靠地达到消费者,RabbitMQ提供了消息确认机制(message acknowledgement)。消费者在订阅队列时,可以指定autoAck参数,当autoAck等于false时,RabbitMQ会等待消费者显式地回复确认信号后才从队列中移除消息。
如果消息消费失败,也可以调用Basic.Reject或者Basic.Nack来拒绝当前消息而不是确认。如果requeue参数设置为true,可以把这个消息重新存入队列,以便发给下一个消费者(当然,只有一个消费者的时候,这种方式可能会出现无限循环重复消费的情况,可以投递到新的队列中,或者只打印异常日志)。
消费者回调
消费者处理消息以后,可以再发送一条消息给生产者,或者调用生产者的API,告知消息处理完毕。
参考:二代支付中异步通信的回执,多次交互。某提单APP,发送碎屏保消息后,消费者必须回调API。
补偿机制
对于一定时间没有得到响应的消息,可以设置一个定时重发的机制,但要控制次数,比如最多重发3次,否则会造成消息堆积。
参考:ATM存款未得到应答时发送5次确认;ATM取款未得到应答时,发送5次冲正。根据业务表状态做一个重发。
消息幂等性
服务端是没有这种控制的,只能再消费端控制。
如何避免消息的重复消费?
消息重复可能会有两个原因:
- 生产者的问题,环节①重复发送消息,比如在开启了Confirm模式但未收到确认。
- 环节④出了问题,由于消费者未发送ACK或者其他原因,消息重复投递。
对于重复发送的消息,可以对每一条消息生成一个唯一的业务ID,通过日志或者建表来做重复控制。
消息的顺序性
消息的顺序性指的是消费者消费的顺序跟生产者产生消息的顺序是一致的。
在RabbitMQ中,一个队列有多个消费者时,由于不同的消费者消费消息的速度是不一样的,顺序无法保证。
参考:新增门店、绑定产品、激活门店。这种情况下消息消费顺序不能颠倒。
高可用架构
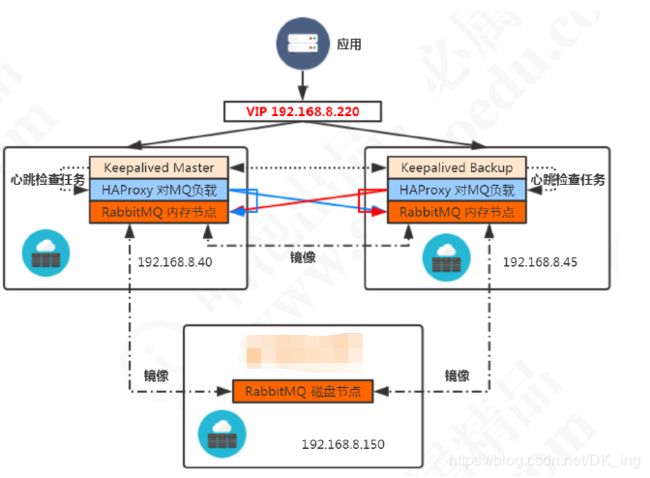
RabbitMQ集群
集群主要用于实现高可用与负载均衡
RabbitMQ通过/var/lib/rabbitmq/.erlang.cookie来验证身份,需要在所有节点上保持一致。
集群有两种节点类型,一种是磁盘节点,一种是内存节点。集群中至少需要一个磁盘节点以实现元数据的持久化,未指定类型的情况下,缺省为磁盘节点。
集群通过25672端口两两通信,需要开放防火墙的端口。
需要注意的是,RabbitMQ集群无法搭建在广域网上,除非使用federation或者shovel等插件。
集群的配置步骤:
- 配置hosts
- 同步erlang.cookie
- 加入集群
RabbitMQ镜像队列
集群方式下,队列和消息是无法在节点之间同步的,因此需要使用RabbitMQ的镜像队列机制进行同步。
| 操作方式 | 命令或步骤 |
| rabbitmqctl (Windows) |
rabbitmqctl set_policy ha-all "^ha." "{""ha-mode"":""all""}" |
| HTTP API | PUT /api/policies/%2f/ha-all {"pattern":"^ha.", "definition":{"ha-mode":"all"}} |
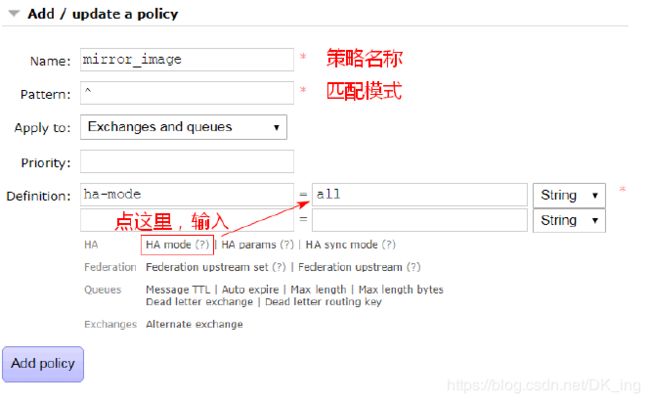
| Web UI | Navigate to Admin > Policies > Add / update a policy Name输入:mirror_image Pattern输入:^(代表匹配所有) Definition点击 HA mode,右边输入:all |
如图:
HAproxy负载+Keepalived高可用
两个内存节点上安装HAProxy
yum install haproxy编辑配置文件
vim /etc/haproxy/haproxy.cfg内容修改为:
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option dontlognull
option redispatch
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
maxconn 3000
listen http_front
mode http
bind 0.0.0.0:1080 #监听端口
stats refresh 30s #统计页面自动刷新时间
stats uri /haproxy?stats #统计页面url
stats realm Haproxy Manager #统计页面密码框上提示文本
stats auth admin:123456 #统计页面用户名和密码设置
listen rabbitmq_admin
bind 0.0.0.0:15673
server node1 192.168.8.40:15672
server node2 192.168.8.45:15672
listen rabbitmq_cluster 0.0.0.0:5673
mode tcp
balance roundrobin
timeout client 3h
timeout server 3h
timeout connect 3h
server node1 192.168.8.40:5672 check inter 5s rise 2 fall 3
server node2 192.168.8.45:5672 check inter 5s rise 2 fall 3启动HAProxy
haproxy -f /etc/haproxy/haproxy.cfg安装Keepalived
yum -y install keepalived修改配置文件
vim /etc/keepalived/keepalived.conf内容修改(物理网卡和当前主机IP需要修改):
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict # 注释掉,不然访问不到VIP
vrrp_garp_interval 0
vrrp_gna_interval 0
}
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict # 注释掉,不然访问不到VIP
vrrp_garp_interval 0
vrrp_gna_interval 0
}
# 检测任务
vrrp_script check_haproxy {
# 检测HAProxy监本
script "/etc/keepalived/script/check_haproxy.sh"
# 每隔两秒检测
interval 2
# 权重
weight 2
}
# 虚拟组
vrrp_instance haproxy {
state MASTER # 此处为`主`,备机是 `BACKUP`
interface ens33 # 物理网卡,根据情况而定
mcast_src_ip 192.168.8.40 # 当前主机ip
virtual_router_id 51 # 虚拟路由id,同一个组内需要相同
priority 100 # 主机的优先权要比备机高
advert_int 1 # 心跳检查频率,单位:秒
authentication { # 认证,组内的要相同
auth_type PASS
auth_pass 1111
}
# 调用脚本
track_script {
check_haproxy
}
# 虚拟ip,多个换行
virtual_ipaddress {
192.168.8.201
}
}启动keepalived
keepalived -D实践经验总结
配置文件与命名规范
- 集中放在properties文件中
- 体现元数据类型(_VHOST _EXCHANGE _QUEUE);
- 体现数据来源和去向(XXX_TO_XXX)
调用封装
可以对Template做进一步封装,简化消息的发送。
信息落库+定时任务
将需要发送的消息保存在数据库中,可以实现消息的可追溯和重复控制,需要配合定时任务来是实现。
减少连接数
合并消息的发送,建议单条消息不要超过4M