docker swarm集群创建、配置、可视化管理实验
- 什么是docker swarm?
docker swarm 是docker原生的docker群集管理、服务编排工具,以命令行的形式创建、管理群集,部署服务,详细参考https://docs.docker.com/engine/swarm/,里边的亮点特性及关键概念需要仔细看一下。
- 创建结点
集群与单体的区别就是把多个docker实例组织在一些做为一个整体来使用。在docker swarm中一个docker实例被认为是一个node,一个node并非指一台虚拟机或者物理机,单台主机上可以运行多个docker实例,那么它就是多个node了,当然,推荐的作法是一台主机上只运行一个docker实例。在https://blog.csdn.net/dkfajsldfsdfsd/article/details/79898787一文中,通过docker machine创建了三台docker主机,它们现在都工作在单机模式,具体信息如下表:
| 虚拟机名称 | enp0s3 | enp0s8 |
| manager | 10.0.3.8 | 192.168.56.103 |
| worker1 | 10.0.3.9 | 192.168.56.104 |
| worker2 | 10.0.3.10 | 192.168.56.105 |
- key/value存储
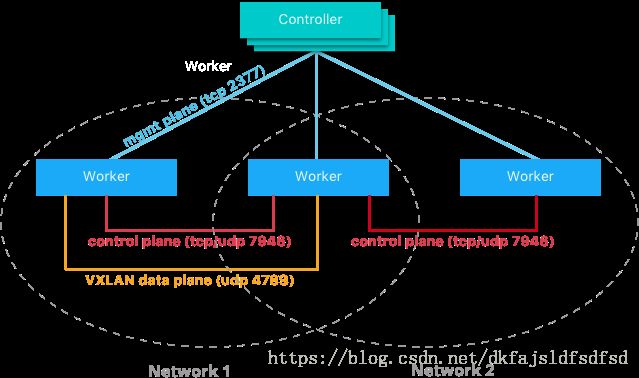
一般涉及到群集时,都需要某种分布式的key/value数据存储,用来登记、发布集群配置信息,常用的有etcd、zookeeper、consul等。但是在docker swarm中,并不需要提供这种类型的数据存储,原因是docker已经内置了这种功能,类似内存数据库,当node工作在群集模式时,每一个加入到集群中的node,同时也扮演着key/value数据存储的角色,这些数据最终会持久化到node的文件系统中。各个节点之间通过gossip协议传递集群状态信息,gossip协议又被简称为"八卦流言小道臭屁满天飞好事不出门坏事传千里协议",从名称上就能看出它的威力。以下是引自docker官方网站的示意图,注意其中用到的端口号:
- 创建集群
接下来开始创建集群。登录manager节点,可以使用docker machine,也可以直接登录,并执行如下指令:
# 登录
docker-machine ssh manager1
# 创建集群
docker swarm init --advertise-addr 192.168.56.103如下图所示:
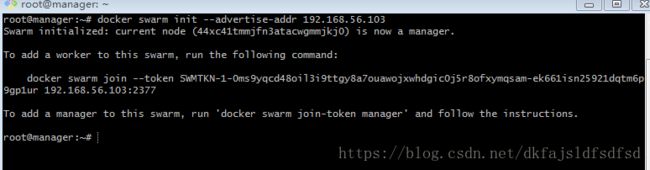
从上图可以看出,现在群集已经创建成功了,当前node现在是集群中的一个管理者。其中的docker swarm join --token xxx 192.168.56.103:2377是向集群中添加新node的指令。docker swarm join-token是专门用于输出token的,太长记不住,用的时候就用这个命令查询。
加入到集群中的node,它的角色可以是manager、worker中的一种或者同时充当这两种角色,可以通过命令控制。当集群中有多个manager时,会选出一个充当Leader。使用如下命令列出集群中的所有节点:
docker node ls如下图:

可以看到目前群集中只有一个节点,它的角色是manager,并且是Leader。
运行如下命令查看当前节点的信息:
docker info如下图:
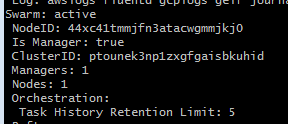
可以看到,Swarm的值由原来的inactive变成active,表示当前node工作在swarm模式了,Managers的值表示manager的个数,Nodes的值表示节点的个数。默认情况下manager同时也是worker,如果不想让manager同时承担worker的任务的话,执行如下指令,“drain”的意思是manager节点不再接受新的task,如果节点上已经有task在运行,则停止掉并调度到其它worker节点上去:
docker node update --availability drain manager- 将其它的两个节点加入集群
分别登录worker1与worker2,执行如下前文docker swarm init时提示的指令:
docker swarm join --token SWMTKN-1-0ms9yqcd48oil3i9ttgy8a7ouawojxwhdgic0j5r8ofxymqsam-5ofedd3lv5f3d2iiqd728dzwp 192.168.56.103:2377默认情况下加入集群的node的角色都是manager。通过docker node ls确认如下图:
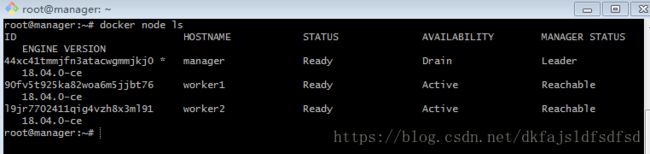
可以看到,目前集群中有三个节点,其中主机manager是专职的领导,不承担worker的工作。worker1与worker2同时承担manager与worker的工作,但不是领导。
在manager上执行如下指令,让worker2释放掉manager资格,成为专职的worker。
docker node update worker2 --role worker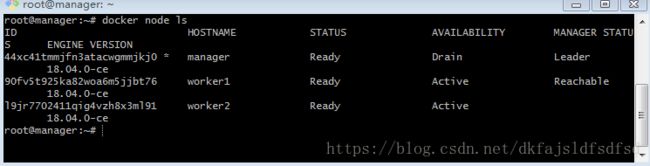
目前集群中有三个节点:
manager节点:专职manager,并且是manager中的Leader,相当于是皇帝。
worker1:worker节点,但是具备manager的能力与成为Leader的资格,在本群集是唯一具备这种资格的节点,如果manager节点不幸挂掉,那 么worker1节点就会升级成Leader,相当于太子。
worker2:纯worker节点,一辈子没出息,相当于是我等屌丝。
- docker swarm集群可视化管理
目前为止,集群创建完成了,对于集群的操作都是通过“docker-machine ssh 节点名”登录到主机上,再执行docker指令完成的,很不方便。有很多可视化的集群管理工具,“Docker Universal Control Plane(UCP)”是docker原厂的可视化集群管理GUI,企业级的,只支持docker EE。这里采用完全开源的"portainer",详细参考https://portainer.io.
整个过程很简单,只需要在集群中部署portainer的service就可以了。但是portainer比较特殊,这个服务只能被调度给manager角色的节点,在本集群中满足这个条件的节点只有worker1,manager节点已经"drain"了,不接受新task,worker2是纯工作节点。另外需要提前在worker1节点上准备好运行服务需要挂载的目录,这里是/etc/portainer,提前创建好就可以了。运行如下指令:
docker service create \
--name portainer \
--publish 9000:9000 \
--replicas=1 \
--constraint 'node.role == manager' \
--mount type=bind,src=//var/run/docker.sock,dst=/var/run/docker.sock \
--mount type=bind,src=//opt/portainer,dst=/data \
portainer/portainer \
-H unix:///var/run/docker.sock
--publish表示以docker内置的"routing mesh"方式开放端口,访问集群中任何一个节点的9000端口都会被重定向到实际运行服务的节点上。在浏览器中输入任何node的IP地址加9000端口号,如下图(首先登录需要创建管理员账户):
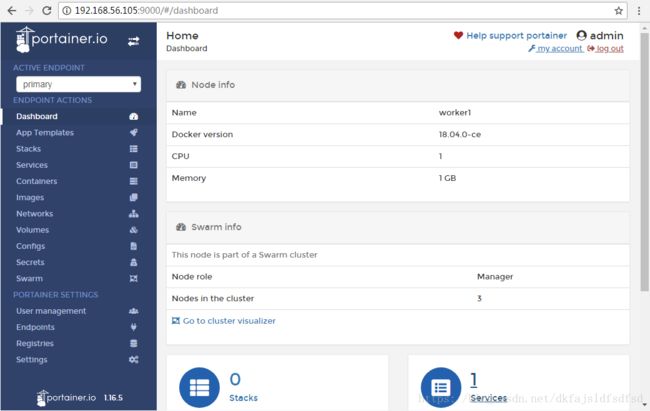
以后就可以通过这个唯一的可视化界面管理集群了。
- 其它参考信息
以上只是简单的初始化一个集群,集群非常复杂,进阶知识参考如下地址,里边包含了swarm的创建、管理、使用、原理等项内容,内容很多:
https://docs.docker.com/engine/swarm/