一、boston房价预测
读取数据集
训练集与测试集划分
线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
比较线性模型与非线性模型的性能,并说明原因
1.读取数据集
1、导入Boston数据集
#!/usr/bin/python
# -*- coding:utf-8 -*-
# -*- author:DavidHuang -*-
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
import numpy as np
import pandas as pd
boston = load_boston()
#
# print(boston.DESCR) # 共506条波士顿地区房价信息,每条13项数值特征描述和目标房价
# print("最大房价:",np.max(boston.target))
# print("最小房价:",np.min(boston.target))
# print("平均房价:",np.mean(boston.target))
#2.训练集和测试集划分
print("开始进行预测和分析!\n========================")
print(bos.keys())==")
bos = load_boston()
bos.keys()
数据集大小
print("数据集大小\n",boston.data.shape)
数据集特征
print("数据集特征\n",boston.feature_names)
数据集预测
print("数据集预测\n",boston.target)3.线性回归
bd = pd.DataFrame(bos.data)
print(bd)
print("开始进行一元线性回归!准备好了吗!")
import matplotlib.pyplot as plt
data = bos.data
x = bos.data[:,5]
y = bos.target
plt.scatter(x,y)
plt.plot(x,8*x-25)# 这里定义一条直线 y = w*x+b,其中w是斜率,b是与y轴的截距
plt.show()4.多项式
print("一元回归结束!开始进行多元线性回归!准备好了吗!")
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
boston = load_boston()
lineR = LinearRegression()
# w = lineR.coef_
# b = lineR.intercept_
x = boston.data[:,12].reshape(-1,1)
y = boston.target
lineR.fit(boston.data,y)
plt.figure(figsize=(10,6))
plt.scatter(x,y)
plt.plot(x,-0.8*x+30,'r')#回归线
plt.show()5.比较线性和非线性
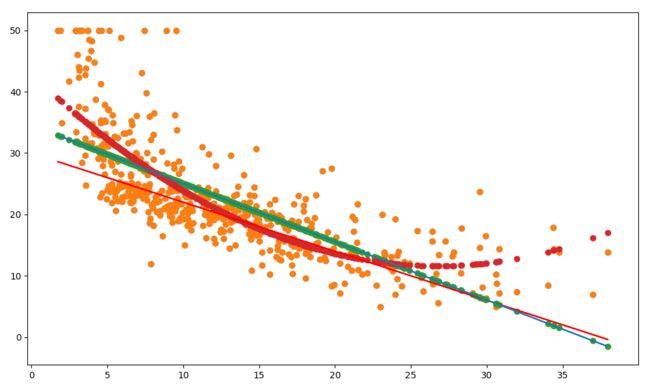
线性的话预测误差比较大,因为是一条直线,所以不能完全反映出散点图的变化
非线性的话比较灵活,也符合预测的结果,误差较小
二、中文文本分类
按学号未位下载相应数据集。
147:财经、彩票、房产、股票、
258:家居、教育、科技、社会、时尚、
0369:时政、体育、星座、游戏、娱乐
分别建立中文文本分类模型,实现对文本的分类。基本步骤如下:
1.各种获取文件,写文件
2.除去噪声,如:格式转换,去掉符号,整体规范化
3.遍历每个个文件夹下的每个文本文件。
4.使用jieba分词将中文文本切割。
中文分词就是将一句话拆分为各个词语,因为中文分词在不同的语境中歧义较大,所以分词极其重要。
可以用jieba.add_word('word')增加词,用jieba.load_userdict('wordDict.txt')导入词库。
维护自定义词库
5.去掉停用词。
维护停用词表
6.对处理之后的文本开始用TF-IDF算法进行单词权值的计算
7.贝叶斯预测种类
8.模型评价
9.新文本类别预测
#!/usr/bin/python
# -*- coding:utf-8 -*-
# -*- author:DavidHuang -*-
import os
import codecs
import jieba
path = r'F:\duym大作业\中文文本分析'
with open(r'F:\duym大作业\stopsCN.txt',encoding='utf-8') as f:
stopwords = f.read().split('\n')
#存放文件(容器)
DataPaths=[]
#存放文件类型
DataClasses=[]
#存放读取的新闻内容
DataContents=[]
#遍历转码处理
for root,dirs,files in os.walk(path):#循环目录
for n in files:
DataPath = os.path.join(root,n)#把路径和文件串起来
DataPaths.append(DataPath)#将上一步数据添加到外部容器
DataClasses.append(DataPath.split('\\')[2])#提取新闻的类别(子文件夹名)
s = codecs.open(DataPath,'r','utf-8')#转码
DataContent = s.read()#读取
DataContent = DataContent.replace('\n','')#去掉\n
tokens = [token for token in jieba.cut(DataContent)]#结巴分词
tokens = " ".join([token for token in tokens if token not in stopwords])#去掉停用词
s.close()#关闭文件
DataContents.append(tokens)#将关键字添加到外部容器
#矩阵排列
import pandas
all_datas = pandas.DataFrame({
'新闻类别':DataClasses,
'新闻内容':DataContents
})
print(all_datas)
a = ''
for i in range(len(DataContents)):
a+=DataContents[i]
import jieba.analyse
keywords = jieba.analyse.extract_tags(a,topK=20,withWeight=True,allowPOS=('n','nr','ns'))
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(DataContents,DataClasses,test_size=0.3,random_state=0,stratify=DataClasses)
from sklearn.feature_extraction.text import TfidfVectorizer
vectors = TfidfVectorizer()
X_train = vectors.fit_transform(x_train)
X_test = vectors.transform(x_test)
from sklearn.naive_bayes import MultinomialNB
mx = MultinomialNB()
mod = mx.fit(X_train,y_train)
y_predict = mod.predict(X_test,y_test)
print("模型的准确率:",mod.score(X_test,y_test))
from sklearn.metrics import classification_report
print("模型评估报告:\n",classification_report(y_predict,y_test))
import collections
testcount = collections.Counter(y_test)
predcount = collections.Counter(y_predict)
namelist = list(testcount.keys())
testlist = list(testcount.values())
predictlist = list(predcount.values())
x = list(range(len(namelist)))
print("类别;",namelist,'\n',"实际:",testlist,'\n',"预测",predictlist)