随笔记
置顶
Detection 算法
- Faster rcnn:链接
- R-FCN:链接1;链接2
- Light Head R-CNN:链接
- SSD:链接
- FSSD :链接
- ION :链接
- HyperNet:链接
Network
- inception系列网络的总结:链接1;链接2
- Shufflenet:链接
- Densenet:链接
- inception v3 netscope :链接;Xception netscope:链接
- mobilenet V2:链接
- DPN netscope:链接
- Squeezenet netscope:链接
Others
- BN层在caffe中的参数及实现过程:链接
- 众多网络的caffe实现以及caffemodel下载:链接
- mixup算法:链接1,链接2
- DSD模型压缩算法:链接
caffe代码解析##
- 整体流程:链接
- Batch Normalization 层:链接
未完待续……
Python 笔记
2017.11.16 Python笔记
-
python assert 函数非常好用,大概用法如下:
python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为假,就会触发异常。assert的异常参数,其实就是在断言表达式后添加字符串信息,用来解释断言并更好的知道是哪里出了问题。eg:`assert num_classes, "must provide num_classes"`
如果num_class没有,就会报错后面那句话。
-
阅读源码的时候找不到定义的函数,用如下的指令快速搜索:
grep -n -H -R "hanshuming" *
n是行号。H是文件名,R是递归查找子目录,适用工程较大的项目。
2017.12.14 Python笔记
demo.py等跟多文件都用到了enumerate指令,自己写Python文件的时候也经常用到,在此举例说明,以防忘记。
l = ['a','b','c','c','d','c']
find = 'c'
[i for i,v in enumerate(l) if v==find]
运行结果是 [2, 3, 5],在看一个常规方法:
l = ['a','b','c','c','d','c']
find='b'
l.index(find)
结果是1。
2018.1.23 Python 笔记
判断两个矩阵是否符合numpy的广播机制:先对比并扩展矩阵的shape,以shape维度大的为准,不够的向前补一,使得两个矩阵的shape一致;对比两个shape的每一个轴,当且仅当满足以下条件可以进行广播:两个shape同一维度的值要么相等,要么其中一个是1.可以进行广播的话,再进行后续的矩阵的repeat等等。
2018.01.31 Python 笔记
Python列表切片,起始值可以超过列表长度,返回的是空列表,如下图所示.
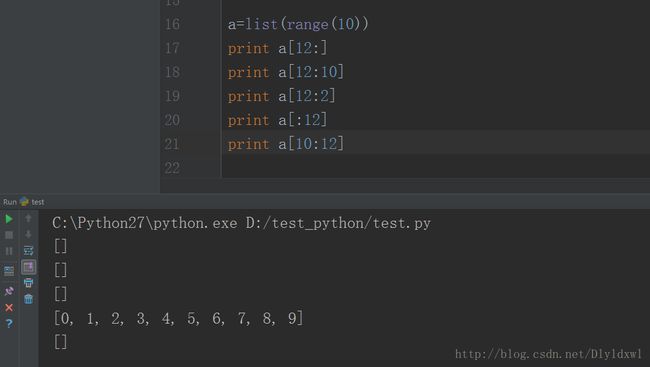
结论可从图片中总结出来。但平时不建议这么使用,特别是大项目的时候,容易引发错误自己都很难察觉出来。
2018.02.01 Python 笔记
关于time.time和time.clock问题,在windows上建议使用time.clock,因为其精度高,对比如下:
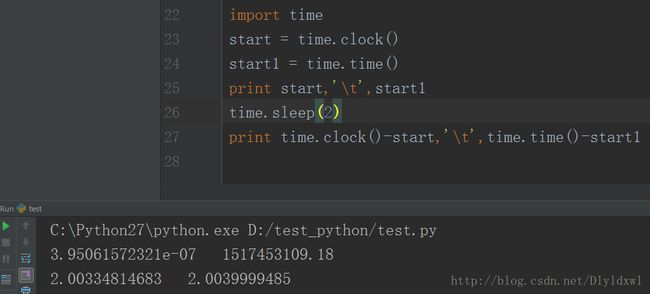
在linux系统中,同样的程序结构不一样,在此就不贴图了。口述一下,time.time()方法返回的值仍然是程序运行的时间,但是time.clock()返回的值近乎是0,因为在Unix系统上,time.clock以秒为单位返回当前处理器时间,例如,执行当前线程所花费的CPU时间。而在Windows上,它是以秒为单位的返回自首次调用该函数以来所流逝的系统时间。但是如果程序段里面没有睡眠等这些程序段,个人觉得还是可以用time.clock()的,精度也会高一点。
2018.03.12 Python笔记
经常在脚本中看到下面的语句,在此给出进行对比实验,贴出截图来说明:
if __name__ == "__main__"
下面是test.py
# coding:utf-8
# by chen yh
import caffe
import numpy as np
root = "/home/cyh/python_file/"
prototxt_n=root+"deploy_vgg.prototxt"
model = root + "VGG_coco_SSD_300x300_iter_400000.caffemodel"
net=caffe.Net(prototxt_n,model,caffe.TEST)
#weight_ori=net.params["fc7"][0].data
bias_ori=net.params["conv5_3"][1].data
print bias_ori.shape
接下来新建一个test1.py, 就import这个模块即可import test,运行这个脚本会发现,输出如图所示:

运行test1.py发现相当于运行了test.py,如果在test.py中加上 if name == “main” 如下图所示:
# coding:utf-8
# by chen yh
import caffe
import numpy as np
if __name__ == "__main__":
root = "/home/cyh/python_file/"
prototxt_n=root+"deploy_vgg.prototxt"
model = root + "VGG_coco_SSD_300x300_iter_400000.caffemodel"
net=caffe.Net(prototxt_n,model,caffe.TEST)
#weight_ori=net.params["fc7"][0].data
bias_ori=net.params["conv5_3"][1].data
print bias_ori.shape
再次运行test1.py结果如下,发现程序什么输出都没有.

也就是说,if __name__ == "__main__" 语句加上之后,只有运行脚本本身才会执行if 后面的语句,在其他脚本中import该模块后,不会运行if 后面的代码段.
但是如果没有这一行语句,在别的脚本中import 该模块后会运行该模块主函数的所有代码段,就和运行脚本自身的输出是一样的.就像第一张结果图一样.
当然我们在import 的时候是不希望这样的事情发生的,所以一般在写脚本的时候会把主函数的代码段放到if __name__ == "__main__" 之后,就相当于其他脚本import后只获得了该脚本的class和def部分.
知乎上有个解释挺不错的,搬过来.它往上第二个回答贴的代码段也是极好的.
每个人天生都自带一些技能的,比如有时候,我们因为某种原因,在月黑风高的夜里,外面寒风阵阵,屋内对影而做,甚是寂寞。这时候我们可能就需要排解一下。这时候你做的一些不可描述的事情可以理解为if name == ‘main’ 里面的内容。但是如果平时你在朋友面前做这种事当然就不合适了,所以在公众场合,我们别的技能,比如打篮球啊,去星巴克码代码啊,这些技能是可以被启用的,这个就是除if name == ‘main’ 之外的代码能够被调用。
作者:张小鸡
链接:https://www.zhihu.com/question/49136398/answer/149688235
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2018.03.13 Python笔记
nunpy的一维线性插值函数np.interp,用法见下图

第一个例子中2.5处于xp中的2和3之间,线性关系可算出2.5对应1.0,以此类推第二个例子的结果也很明显,对应于输入维度的一个array,因为每一个元素都会有一个输出,所以输入和输出的维度是一样的。
那么有什么用处呢?我觉得当用一个阈值t去卡一个大矩阵W的时候,无需使用循环,只要用这个函数就行了,interp的第一个变量是W,第二个变量xp=[Wmin t Wmax+1],第三个变量yp=[0 1 1],这样W中小于t的对应输出为0和1之间的数,大于 t的对应输出为1,结和bool矩阵,便可以完成小于t的置0,大于t的保留。
2018.04.16 Python 笔记
当需要import非当前目录下的模块A内的函数时,需要在当前运行的脚本的搜索路径中添加A,如下面的代码块所示,添加caffe的python接口为搜索路径,2,3两条语句作用相同。
caffe_root = '/home/its/caffe/'
sys.path.insert(0, caffe_root + 'python')
sys.path.append(caffe_root + 'python')
如果当前目录的很多脚本都import了路径A的函数,一般采用的做法是在当前的目录下新建一个py文件B,在这个文件中将A的路径添加到sys.path,然后该目录下的脚本先import B即可。
额外说一个问题,在B中很多脚本习惯使用os.path.dirname(file)来获得当前的文件所在的目录,比如文件/home/its/caffe/python/a.py,a里面只有print os.path.dirname(file),如果在/home/its/caffe/python/目录下运行a.py,就输出空字符串,如果在/home/its/caffe目录下运行python/ a.py,输出python,如果在/home/its目录下运行caffe/python/a.py,输出caffe/python,若在根目录下运行/home/its/caffe/python/a.py,则会输出/home/its/caffe/python。但是当a被别的模块import时,那么输出就一定是/home/its/caffe/python,因为import时,sys.path是绝对路径,所以会输出绝对路径。建议不要用这种形式,不管在何时都用os.path.dirname(os.path.abspath(file)),就一定输出绝对路径。
第二个,init.py的作用,相当于把一个文件夹变成一个包,这样就可以被其他文件调用该文件夹下的模块了。init.py可以什么都不写,也可以import 一些 包,以下举例说明:
比如/a/b/c/d有一个x.py,x文件如下所示,d中有一个__init__.py,内容为空。
def add():
print "add"
if __name__ == "__main__":
pass
在另一个目录下的脚本A中先sys.path.append(/a/b/c)(不要/d了,因为d现在相当于一个模块),再import d.x, x.add()便输出了add;若在__init__.py中写入import x,然后在A中import d,再d.x.add()便可以输出add,好处是多次调用该模块不用重复import,可以在__init__.py中导入需要import的模块(注意两次A中代码的写法),此外__init__.py中的__all__ 功能参见链接
我们在导入一个模块时候(也叫包),实际上导入的是这个模块的__init__.py文件。
2018.04.17 python
对列表进行去重考虑使用set方法。
基本的set使用方法见链接
对列表进行去重的set方法见链接
声明一点:第一条语句输出 set([‘h’, ‘o’, ‘n’, ‘p’, ‘t’, ‘y’]) ,第二条语句输出set([‘python’]),第三条语句输出[‘python’, ‘c++’],也就是完成了列表去重,需要注意的是当set()的输入是一个字符串的时候会对其进行拆分,而且此方法只能有一个输入字符串,需要增加的话用add方法;但是输入是一个list时,就会把list中每一个元素作为set的每一个元素,而不会拆分。
print set("python")
print set(["python"])
print list(set(["python","c++","python"]))
2018.05.04 python 笔记
之前一直断断续续的用argparse,今天大体上总结一些最基本的用法,方便以后查阅:
- parser.add_argument添加项前面没有–,表示该选项是位置参数,必须要有的;前面有–的表示可选参数,例如
parser.add_argument("-v", "--verbose", help="increase output verbosity", action="store_true")verbose就是可选参数,前面的-v叫短选项,是在输入verbose的值时代替verbose的,例如:Python a.py -v即可,要想在py文件中也简写为args.v,要使用dest = ‘v’.要注意的是位置参数不能加短选项。至于dest,暂时本人没测试,不过我估计应该是位置参数和可选参数都可以使用。
2.还有一些其它的常见的选项,例如choice,count等等。
参考资料:链接1,链接2
C++笔记
2018.1.29 C++笔记
c++中含有自增,自减运算符的四则运算经常容易出错,以下贴出c++运行时的汇编代码进行说明。

编译器是VS2013,在四则运算中,i++直接视为i,在进行完赋值运算后才进行++,可以由最后两行看出来。
表达式中只要既有i++和++i,那么一定先算++i,因为其可以改变i的值,可以从第2-5行代码看出;然后将i++直接视为i,这样,含有i++和++i的四则运算式中在算完++i后,就等于是一个不含自增自减运算符的计算式了。上述程序运行的结果是s=12,i=5。
2018.03.02 C++笔记
用到析构函数时,尽量使用初始化列表,常见的初始化列表用法如下图所示:

m_coorA 是另一个类Corrdinate 的一个对象作为Line类的私有成员。
注意初始化列表中冒号和逗号的位置。
2018.03.06 C++笔记
关于类的继承,有以下三种,和基类成员的关系如下图所示:
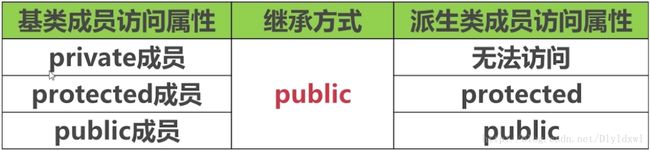

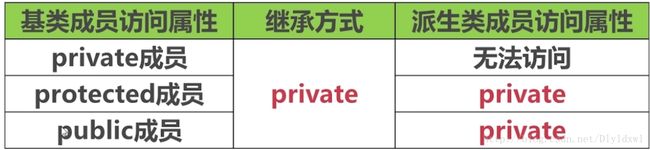
对比可以看出基类的private成员无法被派生类继承。
c++中的is a 和 has a。
假设a,b都是一种类型,a is-a b,说明a类对象是b类对象,只不过是特殊的一种。比如说”飞机“是一种“交通工具”。对应到c++中就是继承关系。可以用子类初始化父类,子类多余的成员函数和成员将被忽略;
a has-a b,说明a类对象具有若干b类对象作为其成员。比如“飞机”有”翅膀“。其中私有继承一是从对象关系上来说是不合理的,写程序的人知道,但是看程序的人就会误会了。二是,用私有继承,比如a中私有继承了b,那么b的所有成员和函数在a中都是private,不能直接访问的了,会对后面的使用造成不方便。
2018.04.30 C++笔记
C++中读取和保存到指定文件,一般会用到fstream这个库,iostream和namespace std需要加上。
ofstream可以直接保存flaot类型数据,如下代码片。但是要注意的是ofstream outfile后, outfile.open的路径不能是string类型数据,否则会报错error: no matching function for call to 'std::basic_ofstream::open(std::string&), 所以此处我用了string的.data方法,将string转化为了char类型的tp。关于string转char还有一种方法.c_str()。c++中str和string的转换可以参考链接ios::app表示写入内容不覆盖原内容。
ofstream outfile;
const char *tp = loc_txt_path_.data();
outfile.open(tp, ios::binary | ios::app | ios::in | ios::out);
vector d(4);
for(int dt=0;dt<4;dt++){
d[dt] = *(loc_pred_diff + count * 4+dt);
outfile< 关于fstream的一些细节参考链接
caffe 笔记
2017.12.4 caffe笔记
- 使用pretrain model去finetune网络时,例如在voc数据集上得到的pretrain model,其已经具有一定的分类检测能力,如果我们要对车辆,行人进行检测,因为pretrain model和最终的模型检测种类数不同,所以pretrain model的一些层就需要重命名,也就是说这些层的参数需要从0学起,那么在一定程度上就没有达到对pretrain model的充分利用。所以我们可以提取出这些层有关车辆和行人的权重,那么在后续的finetune中,这些层也不用重命名了,训练的速度和精度都会有一定的提高。
- 但是要注意的是VOC的labelmap中不同类别是有顺序的,比如说车辆是第2类,人是第10类,那么我们就提取出特定层的第2和10类的权重,现在对于这个层,检测的第一类就是车,第二类是人,如果你的数据集的labelmap里车是第二类,人是第一类,就会给pretrain model检测出来的car贴上people的标签,更新weight和计算loss的时候这个result会和数据集里的真正的people比较,导致训练速度没有明显提升。所以如果VOC里检测类别的顺序和目标检测类别的顺序不一致的话,需要将数据集的labelmap的类别顺序调整为和VOC一致。
2018.01.08 caffe笔记
今天修改shufflenet ssd的proto文件,发现一个一直都没注意到的问题,caffe中的卷积层实现的时候用的是 / 号,也就是向下取整,pooling使用的是ceil函数,所以是向上取整,一点小差别就造成了需不需要添加pad=1这一项,还是要尽快阅读源码呀!
2018.1.10 caffe笔记
今天在解析caffemodel参数的时候,需要用到protoc,在此贴出protoc的安装方法,按照链接上面的方法做的。因为我需要对caffe.proto进行编译,所以把安装好的protoc.exe拖到~/caffe/src/caffe/proto/里面,注意protoc是没有后缀的,只是它的属性是exe可执行文件,执行语句:protoc caffe.proto --cpp_out=./ 生成.h和cc文件,讲.h拖到/include/caffe/proto/里面,就可以进行caffemodel参数解析了。
有关Coco数据集的mmap,经常会有[0.5:0.95], 0.5, 0.75三个之分,再次解释一下:这三个指标表示IOU的取值,[0.5:0.95]一般表示从0.5到0.95, 以0.05为步长的多个IoU阈值下的mAP,称为 Average mAP,作为最终的测评以及排名指标,0.5和0.75就单纯的表示IOU为0.5和0.75.
2018.02.09 caffe笔记
caffe的Python接口小接,先贴图片:
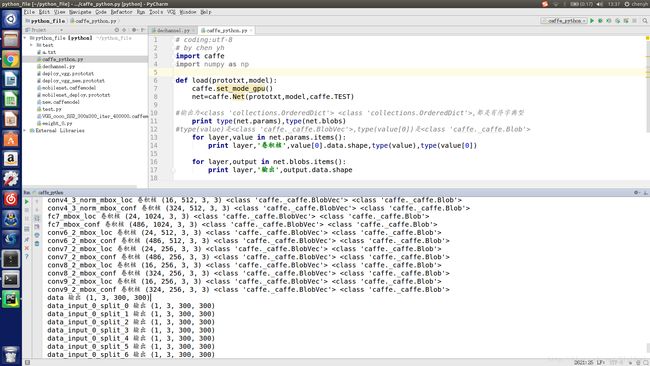
net.params和net.blobs是有序字典类型,键是layer name, 值是blobvec, 因此可以用net.params.keys()来遍历layer,net.params.values()遍历blobvec. layer有几个参数,一般blobvec就有几维,常见的卷积层,value[0]=weight,value[1]=bias,可以用enumerate来遍历value(有点像列表).value[i]是blob类型数据,value[i].data就是它们的值.从图中均可以看出.
net.params的键对应的值是网络的参数(卷积核参数,bn参数等等). net.blobs的键对应的值是每一层的输出值.
此外,net 除了.data还有.diff.
2018.02.26 caffe笔记
caffe 中data layer中有train_form参数,关于scale参数,shicai解释如下:
感觉这个坑也许是我挖的,不过我默认设置的是0.017,初衷是用它来近似代替除以标准差。在ImageNet上,输入数据的BGR三通道均值是[104,117,123]左右,而标准差在[57.1,57.4,58.4]左右,相差很小,都近似取58。然后,除以标准差,就是x/58=x*(1/58)≌x*0.017。当然,这是我一家之言,不保证别人设置0.0167跟我是一样的想法。
作者:Shicai Yang
链接:https://www.zhihu.com/question/63649386/answer/211508137
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于mean value参数,就是图像均值,参考这篇博客的代码可以实现,当然caffe也有自带的脚本实现。
在 fiuetuning 的时候,如果条件允许,需要计算自己数据集的均值,因为集中特定领域的图像均值文件会跟ImageNet上比较General的数据的均值不太一样.
2018.03.06 caffe笔记
Learning both Weights and Connections for Efficient Neural Network论文中有很多细节值得考究:
第一句话是CNNs contain fragile co-adaptedfeatures [24]: gradient descent is able to find a good solution when the network is initially trained,but not after re-initializing some layers and retraining them 。意思是在CNN中梯度下降法能够在网络最初被训练时找到一个好的解决方案,但是在重新初始化一些层并重新训练它们之后就不能了。换句话说,fiuntune/retrain网络时,重新初始化某一个层或者重新定义一个层,是没有使用原来层好的。这也很好理解,毕竟原来该层的权重已经和其他层“配合”的很好了,重新初始化必然效果不好。
第二句话是Also, neural networks are prone to sufferthe vanishing gradient problem [25] as the networks get deeper, which makes pruning errors harder to recover for deep networks. To prevent this, we fix the parameters for CONV layers and only retrain the FC layers after pruning the FC layers, and vice versa。简要翻译为:随着网络深度的增加,神经网络容易陷入消失梯度问题(25),这使得深网络的剪枝错误难以恢复。也就是说,在剪枝或修改权重retrain的时候,如果网络很深,必要的时候要固定一些层的权重,让剪枝层的梯度存在,从而完成retrain.这是不是也从侧面说明了剪枝层更需要学习,所以调大学习率也是有一定作用的呢?
第三句话是下面这张图片

也就是说剪枝的时候卷积层比全连接层更敏感,在前面的卷积层比其他卷积层更敏感,第一个卷积层对参数是最敏感的,因为其直接和输出接触,而输入channel仅仅3个,没有大量冗余,所以其最敏感。
总结起来,1.最大限度的用原网络的权重,能不改层就不改层
2.对于较深的网络。如果要修改某些层权值,必要时候为了减少梯度消失可以固定一些层的权重
3.前面的层比后面的层对参数更敏感,剪枝的时候多考虑后面的层,前面几个层不好掌控
2018.03.20 caffe笔记
SSD把VGG中的conv5_3后pool层的stride=2换成了1,然后fc6层换成了atrous conv,也就是空洞卷积,好处是什么呢,让卷积核达到一样的感受野,从而重复利用之前的网络参数,ssd中fc6和fc7层的参数是从VGG中提取出来的。paper中说明了这个方法的有效性。空洞卷积原理见下图,ssd中5_3的输出为5121919,fc6采用k=3,pool=6,dilated=6,输出的特征图size为19-(52+3)+26+1=19,size不变。

算法笔记
2018.03.09 算法笔记
关于网络的输出,以下两个图可以清楚的表示。
上图中每一列表示网络预测的一个bounding box,首先低于阈值的置信概率直接置0,然后在某一类上对所有bbox排序,再进行NMS算法剔除掉“一样”的bbox。NMS算法如第二张图所示:对于排了序的置信概率,首先把最大的bbox设为bbox_max,以此向后计算每个bbox和max之间的IoU,超过阈值的认为重合,置信概率置0,以此类推,将第二大概率的bbox设为max,再剔除掉与之重合的bbox,最后输出高于指定置信阈值的bbox。图来自于YOLO V1的一篇博客
安装等其他问题
2018.1.17 安装问题
win下安装pillow库时,使用pip和python -m pip这些方法速度都太慢了,无法正常下载,直接去官网下载然后安装即可。在使用PIL.Image显示图片的时候,经常报错为图片已损坏。需要修改源文件。“C:\Python27\Lib\site-packages\PIL\ImageShow.py”,打开这个py文件,将99行替换为
return "start /wait %s && PING 127.0.0.1 -n 5 > NUL && del /f %s" % (file, file)
即可。
pip安装太慢,使用这个 pip install -i https://pypi.doubanio.com/simple/ 包名
pycharm的一个可用激活码 https://jetlicense.nss.im/
2018.06.06
更新pip,numpy用豆瓣的源,速度很快
sudo python -m pip install --upgrade pip -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
sudo pip install numpy --upgrade numpy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
caffe代码阅读笔记
2018.03.24
- blob的num_axes是指该blob的维度,一般conv层的bottom[0]->num_axes是4维,此外shape_.size()也表示blob的维度;
- bottom.size()是指输入的个数,大部分层只有bottom[0],也就是上一层的输出。也有部分层有两个输入,如下图所示的一个loss层,在prototxt里面对应这个层也有两个bottom.

常见的卷积层的参数还有下张图片中的一些,更多请参考链接

2018.03.27
- Dtype 是泛型类型,在定义 Blob 变量时设置的,一般为 float 或者 double,参考博客
- 补充一些C++知识: 基类的析构函数用虚函数 ; vector的用法 ; vector做参数传递问题 ; 函数声明后加const ; template 的理解
2018.03.28
caffe 中的im2col,这一句话总结的非常到位:将整张图片按照卷积的窗口大小切好(按照stride来切,可以有重叠),然后各自拉成一列,所以对于单通道的feature map转换后的矩阵行数就是卷积核的wh,列数就是输出feature map的hw。这是对最终结果的总结。
实现细节是按照行来填充矩阵的,先贴上代码:最外层的for循环,是遍历输入的channel数的,就是生成channel个这样的矩阵。所以直接考虑空格下的四个循环。
/*im2col_cpu将c个通道的卷积层输入图像转化为c个通道的矩阵,矩阵的行值为卷积核高*卷积核宽,
也就是说,矩阵的单列表征了卷积核操作一次处理的小窗口图像信息;而矩阵的列值为卷积层
输出单通道图像高*卷积层输出单通道图像宽,表示一共要处理多少个小窗口。
im2col_cpu接收13个参数,分别为输入数据指针(data_im),卷积操作处理的一个卷积组的通道
数(channels),输入图像的高(height)与宽(width),原始卷积核的高(kernel_h)与宽(kernel_w),
输入图像高(pad_h)与宽(pad_w)方向的pad,卷积操作高(stride_h)与宽(stride_w)方向的步长,
卷积核高(stride_h)与宽(stride_h)方向的扩展,输出矩阵数据指针(data_col)*/
template
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col) {
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1;
const int channel_size = height * width;
for (int channel = channels; channel--; data_im += channel_size) {
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++)//遍历行
{
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++)//遍历列
{
int input_row = -pad_h + kernel_row * dilation_h;
for (int output_rows = output_h; output_rows; output_rows--) //遍历filter在map上纵向滑动的次数,所以max=output_h
{
if (!is_a_ge_zero_and_a_lt_b(input_row, height))
{
for (int output_cols = output_w; output_cols; output_cols--)//和else中的for作用一样,在map中的同一纵列,横向滑动的次数,所以max=output_w
{
*(data_col++) = 0;
}
}
else
{
int input_col = -pad_w + kernel_col * dilation_w;
for (int output_col = output_w; output_col; output_col--)
{
if (is_a_ge_zero_and_a_lt_b(input_col, width))
{
*(data_col++) = data_im[input_row * width + input_col];
}
else
{
*(data_col++) = 0;
}
input_col += stride_w;
}
}
input_row += stride_h;
}
}
}
}
}
建议结合这篇博客的图来看 ,个人觉得博客中代码并没有解释的很清楚,但是图是十分形象的。
feature map =55, kernel=33, pad=1, stride=2,所以输出特征图为3*3。
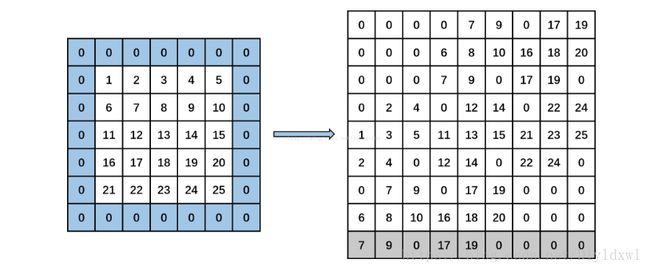
纵向看每一列是每个卷积核的每次卷积的窗口参数,所以行数为kernal_size^2=9。每次卷积得到一个值,而output_map是3*3,所以需要9列,故列数为out map^2=9。
从代码中可以看出实际不是按照列存储的,而是按照行来存储元素,例如第一行存储的是每次卷积时对应卷积核的第一个位置的特征图的9个元素。以此类推。忽略第一个channel的for循环,第二个和第三个for循环是遍历卷积核每个位置对应特征图上的的9个元素,因此也就是kernel_row*kernel_col行。因为每个filte在map上面先横向爬,再纵向爬,所以还需要两个for循环遍历,第四个for是遍历纵向爬的次数,注意是次数,所以max=output_h,同理第五个是横向的次数。当然在执行4,5个for的时候程序判断当前所在行或者列是否在原特征图上,如果是用data_im来获得数值,不是就说明在pad填充行/列,可以直接置0.这对应于代码中的两个if判断。
总的来说,我觉得这段代码非常绕,看代码的时候多画图就容易理解了。
关于2维卷积和3维卷积,指在height和width两个方向上进行卷积就是2维卷积,还在另一个维度上进行卷积就是3维卷积,计算机视觉领域基本都用的2维卷积。参考链接
所以num_spatial_axes_一般为2(下图是原因,channel_axis_是 输入图像的第几个轴是通道 ,一般为1,所以num_spatial_axes_=4-(1+1)),而且caffe.proto默认force_nd_im2col_ =False,,所以caffe中用到的一般都是im2col_cpu,而不会用到im2col_nd_core_cpu函数。


2018.05.05 caffe源码阅读
关于caffe中的某些layer(relu等 )支持in place操作,解释如下:

此外一般还满足top 和 bottom的blob shape 一样大。
那么怎么看到relu层是用的in place呢?目前我的理解是这样的,也不保证正确,以后确定了再来修改。
![]()
relu在forward中对top_data直接用bottom_data来操作,并没有开辟其它的内存空间,并没有使用caffe_copy等函数。
转载了一个关于batch size解释的可以的博客.
1.当数据量足够大的时候可以适当的减小batch_size,由于数据量太大,内存不够。但盲目减少会导致无法收敛,batch_size=1时为在线学习,也是标准的SGD,这样学习,如果数据量不大,noise数据存在时,模型容易被noise带偏,如果数据量足够大,noise的影响会被“冲淡”,对模型几乎不影响。
2.batch的选择,首先决定的是下降方向,如果数据集比较小,则完全可以采用全数据集的形式。这样做的好处有两点,
1)全数据集的方向能够更好的代表样本总体,确定其极值所在。
2)由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
3.增大batchsize的好处有三点:
1)内存的利用率提高了,大矩阵乘法的并行化效率提高。
2)跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快。
3)一定范围内,batchsize越大,其确定的下降方向就越准,引起训练震荡越小。
4.盲目增大的坏处有三点:
1)当数据集太大时,内存撑不住。
2)跑完一次epocffe-master/tools/extra/parse_log.sh caffe-master/tools/extra/extract_seconds.py和h(全数据集)所需迭代次数减少了,但要想达到相同的
精度,时间开销太大,参数的修正更加缓慢。
3)batchsize增大到一定的程度,其确定的下降方向已经基本不再变化。
总结:
1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5)由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
6)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
7)具体的batch size的选取和训练集的样本数目相关。
作者:宿永杰
来源:CSDN
原文:https://blog.csdn.net/qq_36330643/article/details/78661787?utm_source=copy
版权声明:本文为博主原创文章,转载请附上博文链接!