随笔记(二)
2018.06.03 Python代码生成prototxt
如下代码生成peleenet.prototxt。Python文件和deploy文件的 github 链接 . 求个小心心 --
#coding: utf-8
#by Chen yh
tran_channel = 32 #growth_rate
class Genpelee():
def __init__(self):
self.last = "data"
def header(self,name):
s_name = "name: \"%s\"" %name
return s_name
def input(self,size):
s_input = """
layer {
name: "data"
type: "Input"
top: "data"
input_param {
shape {
dim: 1
dim: 3
dim: %d
dim: %d
}
}
}""" %(size,size)
return s_input
def conv(self, name, num_output, k_size, stride, bias_term = False, bottom = None):
if bottom is None:
bottom = self.last
if bias_term:
bias_str = ""
bias_filler = """
bias_filler {
type: "constant"
}
"""
else:
bias_str = "\n bias_term: false"
bias_filler = ""
if k_size>1 :
pad_str = "\n pad: %d" %(int(k_size/2))
else:
pad_str = ""
s_conv = """
layer {
name: "%s"
type: "Convolution"
bottom: "%s"
top: "%s"
convolution_param {
num_output: %d%s%s
kernel_size: %d
stride: %d
weight_filler {
type: "xavier"
}%s
}
}""" %(name,bottom,name,num_output,bias_str,pad_str,k_size,stride,bias_filler)
self.last = name
return s_conv
def bn(self,bottom = None):
if bottom is None:
bottom = self.last
s_bn = """
layer {
name: "%s/bn"
type: "BatchNorm"
bottom: "%s"
top: "%s"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
batch_norm_param {
moving_average_fraction: 0.999000012875
eps: 0.0010000000475
}
}
layer {
name: "%s/scale"
type: "Scale"
bottom: "%s"
top: "%s"
scale_param {
filler {
value: 1.0
}
bias_term: true
bias_filler {
value: 0.0
}
}
}""" %(bottom,bottom,bottom,bottom,bottom,bottom)
return s_bn
def relu(self,bottom = None):
if bottom is None:
bottom = self.last
s_relu = """
layer {
name: "%s/relu"
type: "ReLU"
bottom: "%s"
top: "%s"
}""" %(bottom,bottom,bottom)
return s_relu
def pool(self, name, k_size, stride, bottom = None):
if bottom is None:
bottom = self.last
s_pool = """
layer {
name: "%s"
type: "Pooling"
bottom: "%s"
top: "%s"
pooling_param {
pool: MAX
kernel_size: %d
stride: %d
}
}""" %(name,bottom,name,k_size,stride)
self.last = name
return s_pool
def ave_pool(self, bottom = None):
if bottom is None:
bottom = self.last
s_avepool = """
layer {
name: "global_pool"
type: "Pooling"
bottom: "%s"
top: "global_pool"
pooling_param {
pool: AVE
global_pooling: true
}
}""" %(bottom)
self.last = "global_pool"
return s_avepool
def cls(self, num = 1000, bottom = "global_pool"):
s_cls = """
layer {
name: "classifier"
type: "InnerProduct"
bottom: "%s"
top: "classifier"
inner_product_param {
num_output: %d
bias_term: true
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "classifier"
top: "prob"
}""" %(bottom,num)
return s_cls
def concat(self,bottom,top):
assert type(bottom) is list
length = len(bottom)
str_bo = ""
for i in range(length):
str_bo += """
bottom: "%s" """ %(bottom[i])
s_concat = """
layer {
name: "%s"
type: "Concat"%s
top: "%s"
concat_param {
axis: 1
}
}""" %(top,str_bo,top)
self.last = top
return s_concat
def conv_block(self, name, num_output, k_size, stride, bottom = None):
if bottom is None:
bottom = self.last
s_conv_block = self.conv(name, num_output, k_size, stride, bottom = bottom)+self.bn()+self.relu()
return s_conv_block
def stem_block(self,init_feature):
s1 = self.conv_block("stem1",init_feature,3,2)
s2_a = self.conv_block("stem2a",int(init_feature/2),1,1)
s2_b = self.conv_block("stem2b",init_feature,3,2)
s2_c = self.pool("stem1/pool",2,2,bottom= "stem1")
s3 = self.concat(["stem2b","stem1/pool"],"stem/concat")+self.conv_block("stem",init_feature,1,1)
stem = s1+s2_a+s2_b+s2_c+s3
return stem
def dense_block(self, num_layers, bottleneck_width, stage, growth_rate=32, bottom=None):
if bottom is None:
bottom = self.last
g = int(growth_rate / 2)
btn_width = g * bottleneck_width
s_dense = ""
for i in range(1, num_layers+1):
base_name = "stage"+str(stage)+"_"+str(i)
branch_1 = self.conv_block(base_name+"/a1",btn_width,1,1)+self.conv_block(base_name+"/a2",g,3,1)
branch_2 = self.conv_block(base_name+"/b1",btn_width,1,1,bottom=bottom)+self.conv_block(base_name+"/b2",g,3,1)+self.conv_block(base_name+"/b3",g,3,1)
concat = self.concat([bottom,base_name+"/a2",base_name+"/b3"],base_name)
s_dense += branch_1 + branch_2 + concat
bottom = self.last
assert self.last == base_name
return s_dense
def transition_layer(self, growth_rate=32, has_pool = True, bottom = None):
if bottom is None:
bottom = self.last
name,num = bottom.split("_",1)
global tran_channel
tran_channel += (int(num))*growth_rate
s_tran = self.conv_block(name, tran_channel,1,1)
if has_pool:
s_tran += self.pool(name+"/pool",2,2)
return s_tran
def generate(self):
s_steam = self.header("PeleeNet")+self.input(224)+self.stem_block(32)
s_stage1 = self.dense_block(3,1,1)+self.transition_layer()
s_stage2 = self.dense_block(4,2,2)+self.transition_layer()
s_stage3 = self.dense_block(8,4,3)+self.transition_layer()
s_stage4 = self.dense_block(6,4,4)+self.transition_layer(has_pool=False)
s_cls = self.ave_pool()+self.cls()
s_net = s_steam+s_stage1+s_stage2+s_stage3+s_stage4+s_cls
return s_net
if __name__ == "__main__":
gen = Genpelee()
s= gen.generate()
with open("PeleeNet.prototxt",'w') as a:
a.write(s)
记录一下用Python 生成prototxt的问题吧。
1. 目前比较常用的方法是
from caffe import layers as L
from caffe import params as P这种方法生成train.prototxt 加学习率等参数时,注意param必须是一个列表,元素是字典。BN,relu等层用到In place时要写出来。参考如下代码。参考链接,链接2
#coding:utf-8
#by Chen yh
import caffe
from caffe import layers as l
from caffe import params as p
from caffe.proto import caffe_pb2
from google.protobuf import text_format
if __name__=="__main__":
net = caffe.NetSpec()
net.data=l.Input(shape=dict(dim=[1,3,224,224]))
param=[dict(lr_mult=1,decay_mult=1)]
net.conv1 = l.Convolution(net.data,kernel_size=3,num_output=56,pad=1,group=1,stride=1,bias_term=False,weight_filler=dict(type="msra"),param=param)
bn_param=dict(param=[dict(lr_mult=0,decay_mult=0),dict(lr_mult=0,decay_mult=0),dict(lr_mult=0,decay_mult=0)])
net["conv1/bn"] = l.BatchNorm(net.conv1,in_place=True,**bn_param)
s_p=[dict(lr_mult=1,decay_mult=0),dict(lr_mult=2,decay_mult=0)]
net["conv1/scale"] = l.Scale(net["conv1/bn"],in_place=True,bias_term=True,param=s_p,filler=dict(value=1),bias_filler=dict(value=0))
net["conv1/relu"] = l.Relu(net["conv1/scale"],in_place=True)
net.pool1 = l.Pooling(net["conv1/relu"],pool=p.Pooling.MAX,kernel_size=2,stride=2)
print net.to_proto()2. 第二种是我这种写法,我个人觉得这种写法比较好,不用记那么多接口参数。其主要思想就是写出基本的conv,bn,relu等结构,然后定义block,最后统一连接好各个block.
要特别注意的点是,self.last的更新一定要正确。在复杂的block结尾可以用assert来确保net的传递正确性。
2018.07.10 caffePython接口进行数据可视化
代码是以自己稍加改进的mobilenet_ssd为例,希望看到几个检测层的输出情况,从而决定如何做fuse。以conv11为例。
import numpy as np
import sys,os
import cv2
root = "/home/its/ssd-depthwize/caffe/python/"
sys.path.append(root)
import caffe
import matplotlib.pyplot as plt
def preposs(img):
img = cv2.resize(img, (308, 308))
img = img.transpose([2, 0, 1])
img = (img - 127.5) / 0.007843
img = img.astype(np.float32)
return img
def vis_square(data):
"""Take an array of shape (n, height, width) or (n, height, width, 3)
and visualize each (height, width) thing in a grid of size approx. sqrt(n) by sqrt(n)"""
# normalize data for display
data = (data - data.min()) / (data.max() - data.min())
# force the number of filters to be square
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = (((0, n ** 2 - data.shape[0]),
(0, 1), (0, 1)) # add some space between filters
+ ((0, 0),) * (data.ndim - 3)) # don't pad the last dimension (if there is one)
data = np.pad(data, padding, mode='constant', constant_values=1) # pad with ones (white)
# tile the filters into an image
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
cv2.imshow("conv11",data)
cv2.waitKey(0)
def show(net,img):
net.blobs["data"].data[...] = img
net.forward()
data_l = net.blobs["conv11"].data
data_l = data_l.squeeze()
vis_square(data_l)
if __name__ == "__main__":
img = cv2.imread("004545.jpg")
img = preposs(img)
p = "MobileNetSSD_test.prototxt"
m = "_iter_17000.caffemodel"
caffe.set_mode_gpu()
net = caffe.Net(p,m,caffe.TEST)
show(net,img)
数据预处理,我没有采用caffe自带的方法,也就是caffe.io.load_image(),和一堆transform。使用方法可以参考shicai的mobilenet里面的eval_image.py, github。具体细节参考/caffe/python/caffe/io.py,定义了一堆接口。同目录下的classifier.py作为官方例程也调用了这么些接口。
我是自己写函数来进行预处理操作,注意的点有:1. CV2读取的img就是BRG格式,不是RGB。因此不需要交换channel层内部维度,只需要transpose把channel调到第一个维度即可。2. 注意np.float32的使用。
主要说明一下vis_square函数的作用,其可以可视化卷积核,也可以可视化输出的blob。以blob为例:

首先,n=[sqrt(channel)]+1=23,ceil函数在pool层也用到过。接下来使用np.pad,一来可以是不同的feature map之间可以留个白条做记号,二来是补全channel==n^2.关于pad函数的使用,参考这篇博客。接下里第一个reshape是把(529,21,21)分组为(23,23,21,21),这个好理解,reshape不改变内部数据排列,单纯地把529channel分成了23“行”和23“列”,每一个元素是21*21的feature map。但是要想在二维图上连续显示出来,这样排列数据可不行(这样的话每个map的数据排在一起,也就导致作图每一行是一个map,显然不行,所以需要按照下图格式重新排列axis。我是倒着理解这个transpose的,数据排列必须改成小行->大行->小列->大列,才可以把这些map展示成正常的上图的输出格式。其实这样的思路在SSD中也有用到,以19*19map为例,loc层输出batch*(6*4)*19*19,此时blob的数据排列是依次排列每个特征图上的点的同一个anchor的同一个偏移坐标。通俗的来说,对于19*19上的每个点,6个prior box的4个坐标信息分布在不同channel的特征图的同一个位置上,所以在flatten之前要把每个点的每个anchor信息放一起,而不是说单纯的24*19*19展开就好了。因此ssd有了permute层,也就相当于transpose。
第二个reshape就好理解了,转化为展示图的height*width即可。

2018.09.04 python代码
经常会看到一些好的函数,现在开始记录一下。

首先生成了一个3*3的升序矩阵,np.random.shuffle()是一个随机矩阵,如果直接输入a,则会按照行随机,但是每行内顺序不变,要想对a所有的元素随机,则需要flatten()函数;np.argmax,np.argmin分别返回np的最大值索引,最小值索引;np.argsort函数当输入一维矩阵时,对所有元素升序排序输出索引表,当输入多维矩阵时,需要直接axis,axis=1按行,默认按照行升序排序,要想对所有元素进行排序得到索引表,需要用flatten(),最后一行的函数是将a所有元素进行升序排序。

np.where返回的是一个元组,元素个数是矩阵的维度,每个元素里面的值对应的是符合条件的值在当前维的索引,所以每个元素的对应的值组合到一起就是符合条件的值的索引; np.empty返回一个和输入shape一样大的array,值一般不为0,所以其实并不是"空"矩阵.给定的shape某个元素可以是0,也能被索引,图片中均给出示例.empty_like是创造一个和给定矩阵一样shape的矩阵;np.hstack和np.vstack是垛堞列和垛堞行,输入只有一个选项,要合并的矩阵放到一个列表里面.

[:-1]可以看成切片;[::-1]是对矩阵最外面维度进行倒序排列,如果是一维矩阵,相当于倒序排列原矩阵.
np.savetxt在存储矩阵数据时,常常用了科学计数法保存,如何修改成其他格式呢?使用fmt. np.savetxt(file,array,fmt="%s")即为保存为字符串类型,fmt=%d,整形,%f,float类型
[[] for _ in range(k)]生成k个小列表
使用mpl_toolkits模块画世界地图.
xlrd读excel快,xlwt写excel不能超过65536行,openpyxl可以写大型excel数据.
f = xlrd.open_workbook("graph.xlsx").sheet_by_name("Sheet")
data = []
for i in range(f.nrows):
if type(f.cell(i,1).value)==float:
data.append([f.cell(i,j).value for j in range(f.ncols)])from openpyxl import Workbook
book = Workbook()
ws = book.active
for i in range(1,label.shape[0]+1):
ws.cell(row=i,column=1,value=label[i-1,0])
book.save(filename = "1.xlsx")python的setdefault方法 。参考链接setdefault
pytorch中经常用到OrderedDict.在遍历字典的时候对字典进行操作,经常会报RuntimeError: OrderedDict mutated during iteration错误。例如下面的代码:
from collections import OrderedDict
a=OrderedDict() # a是一个空的有序字典,b是一个已经存在且有键值的字典
for k,v in b.items():
k_newname = k + "_new"
b[k_newname] = v #会报错,因为遍历字典的时候不允许增添键值对,否则循环出出错。应该为a[k_newname] = v
错误很幼稚,但是有时候代码长了还是会犯,在此记录一下。
数据集问题解决记录:
1.数据集中样本不均衡问题;
2.数据集中图片大小差别太大;
2018.11.20
花了很长时间写论文,感觉啃了很长时间老本。年底准备好好提升一下自己的工程能力和进行必要的总结,准备明年的找工作,并冲一波ICCV。
1. group conv的一个精髓就在于concat, 如果不concat,换成sum,有效果吗?
其实group的concat换成sum,那就等效于普通的conv了。在resnext论文里有幅图,1,3两种情况最后一个block就相当于我提出的情景;
2. depthwise是一个高效的设计。本人看channel-wise过程是把dw和pw一直看成是一个conv的分解过程。所以在一般input-channel>>9的时候,dw+pw的计算量几乎全在pw上。因此如何降低pw计算量成为了提高小网络效率的关键。1 int8量化pw。ncnn没记错就是这样实现的,具体细节参看代码,我也没怎么用过(任重道远)2. shufflenet使用了group来降低pw计算量,本质是g conv代替conv进一步降低了计算量,(这里的g conv和conv指的是dw+pw合成的conv,其实是不存在的)(用dw分解gconv同样降低了约9倍计算量,其实只要是用dw+pw近似conv就是降低约9倍的计算量),当然第一个1*1也变成了g conv。3. 我自己天马行空想的。1*1卷积无外乎是一个线性加权的作用,弥补传统卷积中不同channel的spatial 过程结果的不一致变成dw后完全一致的缺陷,当然他还能起到升维降维的作用。能不能不要这些参数,直接打到一个加权的目的呢?当需要降维的时候,沿着channel维度做group的avg/max pool,其实这有点像spatial attention,或者说maxout. 需要升维的时候, 沿着channel维度可做或不做gruop的一维线性插值,这样直接就省去了计算量。至于维度不变的情况,要考虑到特征的多样性,不能简单的进行插值这样的操作,我自己拍脑袋还没想到。好想训练一个imagenet的分类模型试验自己的idea,可是我只有一张卡。悲伤脸--。
2018.12.24
图像处理操作,很常用,但是真的去写会发现容易出一些小问题,在此随便小结一下。

cv2读进来的是BGR顺序的图片,plt显示需要RGB正常的图片,所以显示出来不正常
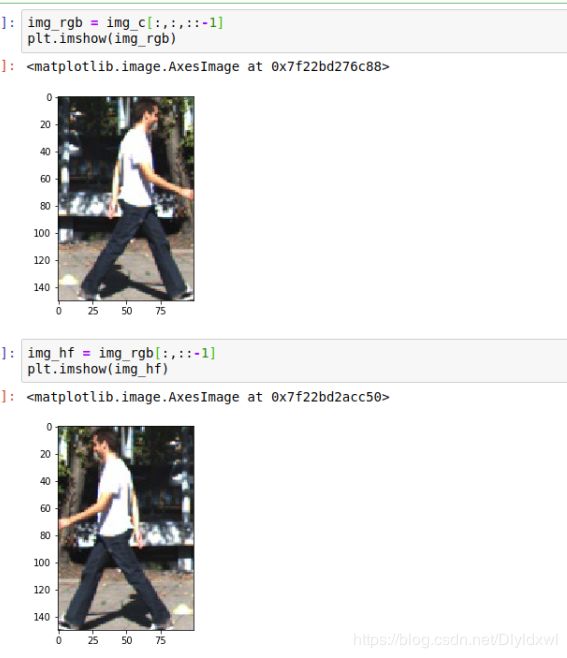
调换顺序后,输出正常了,此外可以发现调换通道顺序是在第三维进行的,所以很多在cv2.imread之后,接了transpose((2,0,1)),这是为了将通道调到第一维,例如300*300*3 -> 3*300*300。
水平翻转其实是行的像素值倒序排,也就是第二维元素。竖直翻转是列的像素值倒序排列。
2019.1.9 pytorch小记
1. param_groups.
spe_params = list(net.loc.parameters()) + list(net.conf.parameters())
spe_params_id = list(map(id,spe_params))
pre_params = list(filter(lambda x: id(x) not in spe_params_id, net.parameters()))
params_group = [{'params': spe_params},
{'params': pre_params,'lr':0.0}]
optimizer = optim.SGD(params_group, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)这里net.loc和net.conf已经是modulelist了,所以可以直接写出他们的parameters,如果是几个层,建议用nn.Modulelist转换为一个module的list,然后在后面传入的时候加一个.parareters()即可。
param-groups中每一个元素都有lr,moment,wd等超参数,在调整的时候对每个param_group赋值就好。
param_groups是一个列表,每个元素是一个字典,键是各个超参数。
需要注意的是,冻结某些层的时候,如果BN在里面,running_mean和var还是在更新,要想直接冻死,可以把BN收到CONV里面,完了需要的话再放出来。
2. pytorch0.4中的.data和.detach()的区别:参考链接,主要是说, 相同点有,都返回一个requires_grad=False的tensor,且都和原tensor共享内存,即一动全动.不同点: autograd不会跟踪.data的计算,但是会跟踪.detach().也就是说,对于tensor X, 用data方法改变了X的值(例如inplace),反向传播的时候并不知道改变了,还是把X的值直接来过来用,但是detach会让反向传播了解到X的值发生了改变,从而语法报错.
实验表明,大多数情况下data和detach结果都是一样的,只有少数情况用data后计算的梯度不对.
a = torch.rand(5, requires_grad = True)
out = a.tanh() # tanh和sigmod会报错,其他均不会报错,不管是引入其他变量的计算还是a**2等运算
c = out.detach()
c += 1
out.sum().backward()
#在CNN中经测试,两种方法也没明显差异,但是鉴于有些情况下data会出错,所以建议用detach而不是data.3, pytorch中的backward, 当一个非标量的tensor T 调用backward方法时, 需要传入一个与T维度相等的权重tensor W.
x = torch.randn(3, requires_grad=True)
y = x * 2
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
print(x.grad)
output: tensor([0.2000, 2.0000, 0.0002])参考链接1, 链接2
2019.04.20 交叉熵损失函数的简要实现
下面代码段表示a是网络输出的类别预测矩阵,4个anchor, 3个类别,b是每个anchor应该对应的类别,ce是交叉熵。
import torch
a = torch.rand(4,3)
b = torch.tensor([0,1,2,0])
print('predict:',a)
print('class:',b)
import torch.nn.functional as F
ce = F.cross_entropy(a, b, size_average=False)
print ('CE:',ce)
output:
predict: ([[0.3139, 0.3682, 0.2602],
[0.0739, 0.5971, 0.2072],
[0.6904, 0.3558, 0.7140],
[0.5112, 0.8050, 0.5738]])
class: tensor([0,
1,
2,
0,])
CE: 4.1292下面的代码段是自己实现CE的过程,实际在计算softmax分数时,讲预测矩阵都减去其最大值得到新的预测矩阵,使得指数项值在0-1之间。其实并不需要计算出实际的softmax分数,按照下面的公式推算出即可。
def log_sum_exp(x):
x_max = x.data.max()
return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True)) + x_max
torch.sum(log_sum_exp(a) - a.gather(1, b.view(-1, 1)))
output:
tensor(4.1292)gather函数便是返回了xij的值,就是第i个anchor在正确类别j上的网络输出的预测值。参考链接
2019.5.12
smooth l1 loss
最近做一个项目涉及到loss的修改。在此总结一下smoothl1 loss的特点和设计类似于smoothl1回归损失函数的几个原则,
1.为什么用smoothl1?
smoothl1是在faster rcnn中引入的。训练初期的outlier(离群点)多,loss较大,如果不加以限制,很容易grad过大,从而跑飞,所以适合用L1损失(grad==1)。训练中后期inlier与GT较为接近,如果grad仍然为常值不利于收敛到一个更好的值,此外对于不是outlier的样本,loss大的应该给予大的grad,loss小应该grad小,所以适合用L2损失。Libra RCNN提出的改进smoothl1,因为在训练过程中发现回归的梯度大部分被outlier主导了(因为他们的梯度等于max,常值1),所以将smoothl1的grad的线性部分改为log函数,增大与max的接近程度(log函数是凸函数),增大inlier的grad.
2.如何设计一个类似smoothl1的损失函数呢?
在引入reputlion loss到ssd里面时,有一项是需要对 所有正的anchors与和其第二大Iou的GT 之间的IOG进行约束,IOG的范围是[0,1],因此smoothl1不再适用,所以需要自己设计一个类似于smoothl1的距离度量函数,个人觉得主要有以下三点需要考虑:
- 过原点。x=0时,loss=0毋庸置疑;
- 是一个连续函数,也就是说两段函数在间断点的函数值相等,且需为单增函数,保证x越大,loss越大
- 导函数第一段是一个增函数,第二段是一个常函数(保证outlier不会跑飞),且在连接处导数相等(否则函数 不连续,违反上一条规则)。
- 以上均是对于x>0的情况进行讨论,x<0时,按道理说grad的图像应该是关于y轴对称,因为此时x越大其实越是inlier,grad应该越小,所以从这个角度来说,smoothl1的设计是不妥的,libra才是正确的。同理,函数的图像也应该是关于Y轴对称
Pytorch相关操作
- gather和scatter_. gather是从一个现有的张量A中按照指定的索引取出一些值从而得到最终的张量,输出的shape和索引矩阵的shape相等。torch和tensor均具有gather方法。scatter_只有张量具有该方法,torch没有。表示对给定的张量A,按照索引将另一个同索引矩阵相同shape的赋值矩阵填到A中。
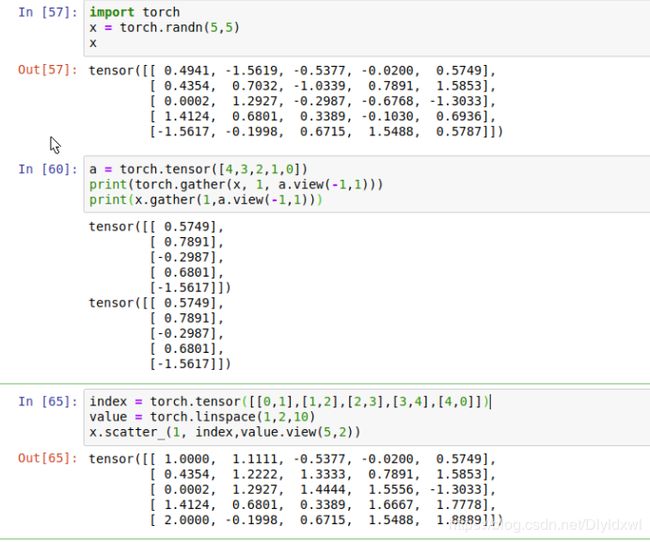
- hook。用以variable的register_hook和用在module上的register_forward_hook和register_backward_hook。建议使用register_hook。register_forward_hook的grad_in和grad_out均是正确的,但是register_backward_hook的grad_in是不正确的,不是model的input的grad,而是module的最后一次操作的grad,但是它的grad_out是正确的。register_hook只返回变量的grad,不返回value。插hook的所有操作需要在将数据x传到net之前注册好,然后再backward()结束后删除句柄 (调用.remove)
- module,children,state_dict, parameters等遍历model的方法比较。
- collate_fn定义了如何取样本,dataloader按照dataset(或者自己重写的dataset)中的getitem方法获取img和target,然后按照一一对应的方式,将batch个一一打包成元组,格式:((img,target),(),……),但是常常我们需要自定义读取方式,比如img和target分开, 但可以对应上,就需要自己写collate_fn方法。此处可能会用到torch.stack方法,这个函数和torch.cat不同,后者不改变张量轴的个数,但是stack增加1个轴,可以给定增加的轴位于第几维,若给定0,则表示按照depth方向堆叠原tensor, tensor的内容不改变。